I had a simple form where the user can select a vendor from a select list (using the Select2 plugin), and the form would retrieve the latest purchase details based on a simple string search of that vendor’s name – for most cases. Sometimes, however, it failed to find anything even though I knew the data was there.
There was a dynamic action that fires on Change of the list item that executes a PL/SQL procedure and retrieves the Total Amount and the Memo:
This didn’t work in some cases where a vendor name included special characters, such as &. This is because the item had Escape special characters set to the default (Yes), which is good practice to protect against Cross-Site Scripting (XSS) attacks. Therefore, the value sent by the dynamic action to my PL/SQL procedure had the special html characters escaped, e.g. “Ben & Jerry’s” was escaped to “Ben & Jerry's“. I believe APEX uses the apex_escape.html function to do this.
Usually, I would try to rework my code to send a numeric ID instead of a string; but in this particular case the data model does not have surrogate keys for vendors (it’s just a free-text field in the transactions table) so I want to use the name.
If I was doing this properly, I would fix the data model to make vendors first-class entities, instead of using a free-text field. This would allow using a surrogate key for the vendor list and this escaping behaviour would no longer be a problem.
Another alternative here is to use the latest transaction ID as a surrogate key for each vendor; but then I would need to modify the form to translate this back into a vendor name when inserting or updating the table; and this would add unnecessary complexity to this simple form, in my opinion.
Instead, before sending this string to my procedure, I’ve chosen to unescape the data. To do this, I add a call to utl_i18n.unescape_reference:
The new Form Region feature introduced in Oracle APEX 19.1 is a big improvement to the way that single-record forms are defined declaratively.
In prior versions of APEX, you were effectively limited to a single DML load process and a single DML submit process, and all the items on the page that were linked to a table column were required to be from only a single table. If you wanted to do anything more complicated than that, you had to either split your form into multiple pages or get rid of the DML processes and hand-code the PL/SQL yourself.
The new components/attributes for Form Regions are:
Region type “Form” which defines the Source Table (or view, or SQL Query, or PL/SQL returning a SQL query, or Web Source) and associated semantics.
Item Source attribute that associates each item with a particular Form Region. The item can optionally be marked as “Query Only” and/or as a “Primary Key”.
Pre-render process type “Form – Initialization” that is associated with a Form Region.
Page process type “Form – Automatic Row Processing (DML)” that is associated with a Form Region. This can be used to change the Target for the form region (default is the Source Table) to a different table or view, or to replace the DML processing with your custom PL/SQL. You can also modify other semantics such as Prevent Lost Updates and row locking.
If you generate a single-record form page APEX will generate all the above for you and you can then customise them as you need.
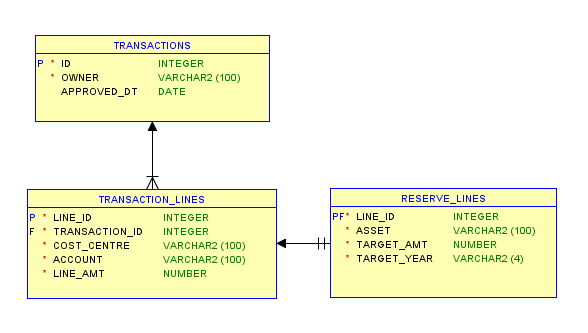
Now, I want to create a slightly more complex form – one based on two tables that are related – “Transaction Lines” and “Reserve Lines” have the same Primary Key, and a referential integrity constraint linking them. They act like a “super class / subclass”, where one table (“Reserve Lines”) is optional. This data model eliminates the need to have lots of nullable columns in a base table.
Data model
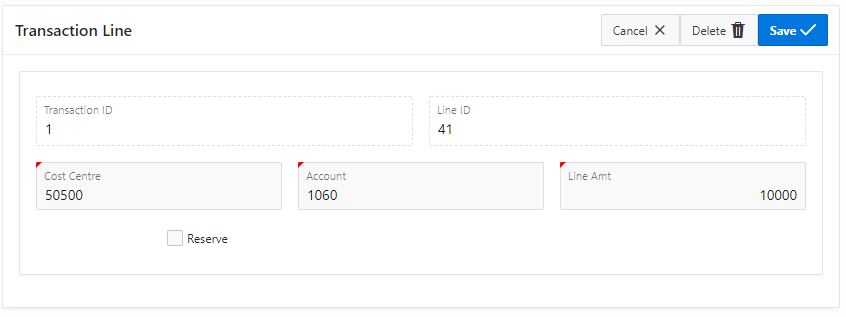
Here’s the form for editing a single “Transaction Line”:
Form with “Reserve” unticked
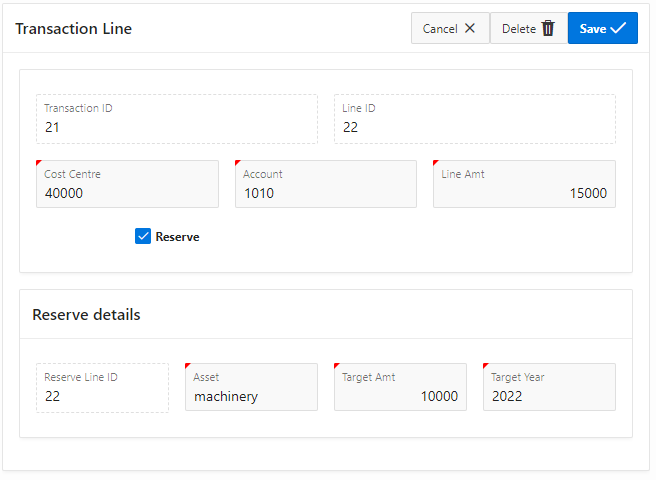
The form shows the associated “Reserve Line” if it exists:
Form with “Reserve” ticked
If the “Reserve” checkbox is ticked, the Reserve details region is shown and the user can enter the Reserve Line attributes.
I need the page to perform the following actions:
For a new record, if the user leaves “Reserve” unticked, only a Transaction Line should be inserted.
For a new record, if the user ticks “Reserve”, both a Transaction Line and a Reserve Line should be inserted.
For an existing record, if the user ticks or unticks “Reserve”, the Reserve Line should be inserted or deleted accordingly.
If you want to see this example in action, feel free to try it out here: https://apex.oracle.com/pls/apex/f?p=JK201904&c=JK64 (login using your email address if you want). The starting page is a blank transaction; click “Create”, then click “Add Line” to open the transaction line page.
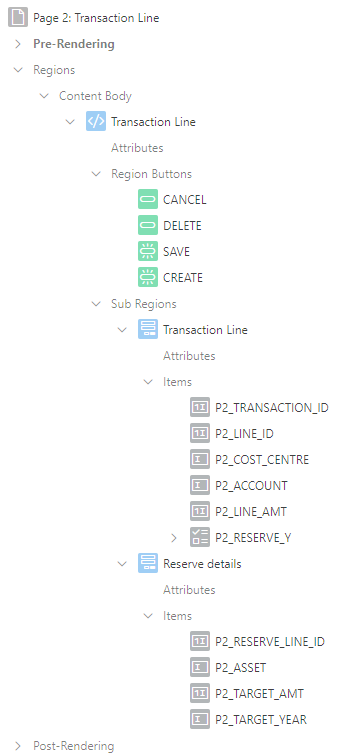
The page is composed of two Form Regions. Note that in this example I’ve laid out all the items for each form within its Form Region, but this is not strictly necessary.
To do this, I built the form in the following manner:
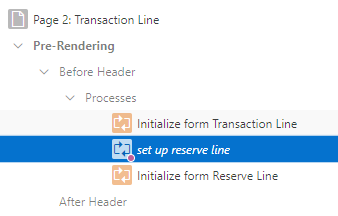
Created a Form Region for the Transaction Line with standard Initialize form and Automatic Row Processing (DML) processes.
Created a second Form Region for the Reserve Line with the standard processes (but customised later).
Added the “P2_RESERVE_Y” checkbox item, not linked to any source column. Added a dynamic action to show/hide the Reserve details region if it is ticked/unticked.
Added a “set up reserve line” PL/SQL Code process immediately after the Initialize form Transaction Line and just before the Initialize form Reserve Line process:
Server-side Condition Type = Rows returned
SQL Query = select null from reserve_lines where line_id=:P2_LINE_ID
5. Change the Automatic Row Processing (DML) for the Reserve Line region:
Target Type = PL/SQL Code
PL/SQL Code to Insert/Update/Delete:
case when :P2_RESERVE_Y is null then
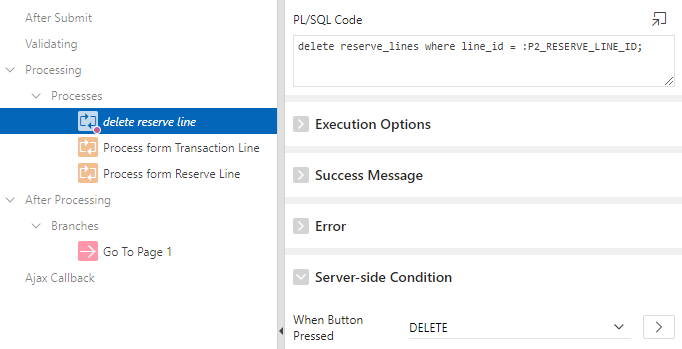
delete reserve_lines where line_id=:P2_RESERVE_LINE_ID;
when :P2_RESERVE_Y is not null
and :P2_RESERVE_LINE_ID is null then
insert into reserve_lines
(line_id,asset,target_amt,target_year)
values
(:P2_LINE_ID,:P2_ASSET,:P2_TARGET_AMT,:P2_TARGET_YEAR )
returning line_id into :P2_RESERVE_LINE_ID;
when :P2_RESERVE_Y is not null
and :P2_RESERVE_LINE_ID is not null then
update reserve_lines
set asset=:P2_ASSET
,target_amt=:P2_TARGET_AMT
,target_year=:P2_TARGET_YEAR
where line_id=:P2_RESERVE_LINE_ID;
else
null;
end case;
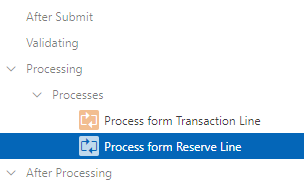
6. Add a special handler to delete the reserve line if the user clicks the Delete button (this needs to be executed prior to the Process form Transaction Line to avoid a FK violation).
This solution is not quite as “low-code” as I’d like; it would be simpler to call a TAPI here instead of hardcoding the DML statements. The reason we need custom PL/SQL here is that when the user clicks the “Create” or “Save” buttons (which are associated with the SQL Insert and Update actions, respectively), we often need to translate this into a different DML action (insert, update, or delete) for the Reserve Lines table.
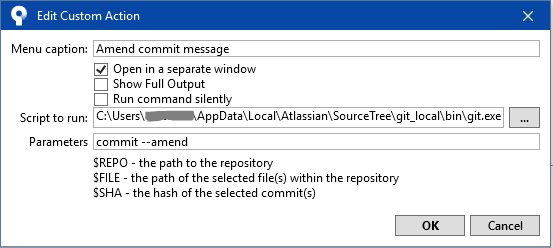
If you’re using Atlassian SourceTree with a git repository and you do a local commit but then realise the message was incorrect, you can amend it before you push it to remote. To set this up, you can create a “Custom Action” in SourceTree:
Tools -> Options -> Custom Actions
Click Add
Set Menu caption, e.g. “Amend commit message”
Select “Open in a separate window” and unselect “Run command silently”
Set Script to run to “git.exe” including path
Set Parameters to “commit –amend”
Now, whenever you want to correct the message on your latest commit, you right-click on the commit, and select “Custom Actions” -> “Amend commit message“. A terminal window will open with a vi editor open with the current commit message at the top of the file (there will also be some instructions with # at the start of each line; you can leave them alone).
If you know vi, you’ll know what to do. Here’s a quick guide:
To start editing, press “i” and then edit the message (on the first line of the file).
To delete everything on the line, press ESC, followed by “ddO” (this will delete the line and then return you to edit mode to type the new message)
To save and quit, press ESC, followed by “:wq“
To quit without making any changes, press ESC, followed by “:q!“
This is an article I wrote quite some time ago and put “on ice” until I completed the client project it was related to. However, for unrelated reasons the project was significantly delayed and later rebooted with an updated set of requirements, which no longer require Oracle Workspace Manager. This means I’m unable to add a triumphant postscript saying “this was a great success and it’s being used to this day”. Instead, I’m adding this preamble to say “this was a very interesting feature of Oracle I learned but didn’t quite get to use, but hopefully someone will find it useful”.
Oracle Workspace Manager (OWM) is a feature of the Oracle database that was built back in the 8i days and installed in Oracle by default since 9i. As described by Tim Hall, it allows multiple transactionally consistent environments to exist within one database.
Confusing Terms… Don’t confuse OWM with Oracle APEX workspaces, or with Analytic Workspace Manager for Oracle OLAP.
OWM allows the developer to take a leap over the complexities involved in a number of use cases, such as:
Savepoints – a snapshot of a point in time
Workspaces – a private area for modifications that are not visible to normal users
Row History – store a history of every change for every record
Valid Time – support date/time range validity for each record
The Row History use case is similar to using Flashback Query which is a more modern feature of the database; however, since it can be enabled or disabled individually for each table, it may require less storage space to support querying back as far as the user would like in time.
The Valid Time use case allows your users to set a date/time range on each record; multiple versions of a unique row can be created with non-overlapping date ranges; updates can be done within the context of a given date/time range, which will cause rows that span the boundary of the range to be split into multiple versions. I haven’t tried this myself but it looks like a powerful feature.
Note: the default workspace for a user session is called “LIVE“, and the default savepoint is “LATEST“.
One example of using savepoints is that a user could create a savepoint, make changes, go back and view the database as of the savepoint, and can rollback all changes to a savepoint. They can also run an API command (dbms_wm.SetDiffVersions) to generate a differences report which shows all the inserts, updates, and deletes that have occurred since a savepoint.
An example of using workspaces is where a user could create one or two workspaces, each representing a different scenario. The user can jump back and forth between the scenarios and the “live” workspace (which is the default). They can edit any of these workspaces. Changes made by other users to the “live” workspace may, optionally, be automatically propagated into a workspace. Similarly to savepoints, the user can get a differences report between any workspace (including the “live” workspace). In addition, the user can create and view savepoints and additional workspaces within a workspace – OWM maintains a hierarchy of workspaces.
If the user is not happy with their scenario, they can simply delete the workspace and the live data is not affected.
If they are happy with their changes in a workspace, they can choose to do a Merge – which attempts to effect all the inserts, updates and deletes that were made in the workspace to its parent workspace (e.g. the “live” workspace if that was the source). If any change to a row would conflict with a change that another user made to the same row in the parent workspace, the merge stops and the user may be prompted to resolve the conflicts (i.e. for each row, the user can decide to refresh their workspace with the updated data in the parent, or they can force their workspace’s change onto the parent).
I suspect OWM was once known (or internally referred to) as “Long Transactions” or something like that, probably because of its user workspace and merging features. You can see the remnants of this old name in the documentation – many of the document URLs start with “long”. Also, note the title of this slide deck by an Oracle product manager: “Long Transactions with Oracle Database Workspace Manager Feature”.
The features of OWM only affect the tables that you explicitly Enable Versioning on via the API (DBMS_WM).
Limitations/Restrictions of Workspace Manager
If you are looking into using OWM, you must read the Intro to Workspace Manager in the docs. Make sure to review the restrictions that apply, such as:
Each version-enabled table must have a primary key.
If a parent table is version-enabled, each child table must also be version-enabled (but the opposite does not apply).
Referential integrity constraints MUST refer to the primary key in the parent table.
Primary key values in a parent table cannot be updated.
Only row-level triggers are supported – no per-statement triggers.
SQL MERGE statements are not allowed (attempts to do so results in “ORA-01400 cannot insert NULL into WM_VERSION”).
RETURNING clause is not supported (for INSERT or UPDATE statements).
Row-level security policies (VPD) are not enforced during workspace operations (such as Merge Workspace, and Rollback to Savepoint).
Materialized Views on a version-enabled table can only use the REFRESH COMPLETE method; e.g. no FAST or ON COMMIT.
Table names cannot be longer than 25 characters.
Column names cannot be longer than 28 characters.
Trigger names cannot be longer than 27 characters.
Some reserved words and characters apply, e.g. column names cannot start with WM$ or WM_.
Most DDL operations cannot be run directly on a version-enabled table (see below).
There are some other restrictions, so make sure to review the intro document carefully and consider the ramifications of each limitation for your particular situation.
I’ve used this simple script to do some basic checks on a table before I enable it for versioning: check_table_for_owm.sql
Database schema changes made by OWM
Internally, when you version-enable a table (e.g. MYTABLE), OWM makes a number of changes to your schema as follows:
Renames MYTABLE to MYTABLE_LT, for internal use only
Adds a number of grants on the object to WMSYS and WM_ADMIN_ROLE
Adds some extra OWM-specific columns (with names prefixed with WM_) and indexes to MYTABLE_LT
Creates the view MYTABLE, for use by your application for querying and DML
Creates an INSTEAD OF trigger (owned by WMSYS) on the view to handle DML
Creates some other triggers on any parent tables for referential integrity
Creates one or two other tables (MYTABLE_AUX, and sometimes MYTABLE_LCK) for internal use only
Creates some other views (MYTABLE_CONF, MYTABLE_DIFF, MYTABLE_HIST, MYTABLE_LOCK, MYTABLE_MW) for application use where needed
Converts any triggers and VPD policies on the table to metadata and then drops them; these are managed by OWM from then on
Based on the grants that OWM gives to WMSYS (such as ON COMMIT REFRESH and QUERY REWRITE) I think the OWM tables are materialized views.
To change the structure of a version-enabled table, e.g. adding/modifying/removing a column, constraint, or trigger, the following steps must be done:
Call dbms_wm.BeginDDL('MYTABLE');
Make the changes to a special table called MYTABLE_LTS
Call dbms_wm.CommitDDL('MYTABLE');
Note that this will fail if the table happens to have any constraints or indexes that are longer than 26 characters – so keep this in mind when naming them.
One of the most pleasing features of OWM is that it is relatively idiot-proof; if you try to perform an operation that is not supported, OWM will simply raise an exception (e.g. “ORA-20061: versioned objects have to be version disabled before being dropped“) instead of leaving you with a mess to clean up. Therefore it’s generally safe to test your scripts by simply running them and seeing what happens. For example, try doing some damage to the underlying tables or views by changing columns or dropping them – OWM will stop you. I would never do this sort of experiment in a production environment, of course!
Column comments on a table that becomes version-enabled are not migrated automatically to the view. They do remain on the renamed table (MYTABLE_LT). You can add comments to the view columns (and you don’t need to execute the BeginDDL/CommitDDL procedures for this); the same applies to the TABLE_LT table as well. Note, however, that if you remove the versioning from the table the view is dropped along with its comments, so if you later re-enable versioning you might want to re-apply the column comments as well.
To copy/synchronize the column comments from the underlying MYTABLE_LT table to the MYTABLE view, I use this script: sync_comments_lt_to_view.sql.
Implementing Workspace Manager
For guidance on how to take advantage of Oracle Workspace Manager in an APEX application, I watched this video by Dan McGhan. He demonstrates it in a javascript application but the real work is all done on the database in PL/SQL, which can be used by any application environment including APEX.
These are some of the API calls that I’ve used to build OWM features into my application:
My APEX application already uses VPD (or Row Level Security) to provide a multi-tenant environment for a wide range of users. Groups of users are assigned to one or more Security Groups; when they login they are assigned to one Security Group at a time which is set in a Global Application Context. A VPD policy has been applied to most tables like this:
function vpd_policy
(object_schema in varchar2
,object_name in varchar2
) return varchar2 is
begin
return q'[security_group_id=sys_context('CTX','SECURITY_GROUP_ID')]';
end vpd_policy;
The Application Context is associated with the APEX session’s Client Identifier (e.g. JBLOGGS:16630445499603) so each page request will be executed within the correct VPD context. A procedure is called from the Post-Authentication Procedure Name on the authentication scheme which sets the SECURITY_GROUP_ID context variable.
According to the docs, OWM can work along with VPD. However, you need to be aware of a few considerations:
Row-level security policies are not enforced during workspace operations, including MergeWorkspace and RollbackToSP.
Row-level security policies must be defined on a number of views, not just the view for the version-enabled table.
Don’t apply policies to the underlying tables created by OWM.
You can add VPD policies to a table prior to version-enabling it and these will be handled correctly by OWM when you version-enable it. However, if I need to add VPD policies after a table has been version-enabled, this is the code I run:
declare
target_table varchar2(30) := 'MYTABLE';
begin
for r in (
select view_name
from user_views
where view_name in (target_table
,target_table||'_LOCK'
,target_table||'_CONF'
,target_table||'_DIFF'
,target_table||'_HIST'
,target_table||'_MW')
) loop
begin
dbms_rls.add_policy
(object_name => r.view_name
,policy_name => 'security_policy'
,policy_function => 'security_pkg.security_policy'
,update_check => true
,static_policy => true);
exception
when others then
if sqlcode != -28101 /*policy already exists*/ then
raise;
end if;
end;
end loop;
end;
It adds the policy to the base view, as well as the five specific associated views (mytable_LOCK, mytable_CONF, mytable_DIFF, mytable_HIST and mytable_MW). Similar code may be used to alter or drop policies.
Note: with relation to VPD policies, the documentation doesn’t specifically mention the Multi-Workspace (_MW) view. As far as I can tell, however, this is required – because when you version-enable a table, a VPD policy on a non-version-enabled table will be applied by Workspace Manager to this _MW view as well as the other views.
Since a user’s changes within a workspace will be restricted to data for their Security Group, a MergeWorkspace works just fine – even though technically the merge occurs across the entire table ignoring the VPD policy, the only changes we expect are those for the user’s Security Group.
However, Savepoints are different; like workspaces, they are a snapshot of the entire table; if you issue a RollbackToSP, it will ignore any VPD policies and rollback all data to the selected savepoint. This means that you can’t use RollbackToSP to give users the ability to rollback their data to a snapshot, while isolating their changes to their VPD context. For this reason I don’t use RollbackToSP in my application.
All together – OWM, VPD and APEX
The users of my application need to be able to create scenarios for people in their Security Group to make proposed changes, see how the changes affect the reports, and merge those changes back to the “live” version. To facilitate this, I create a table to list the workspaces, and apply the VPD policy to it so that users can only view and work with workspaces for their Security Group.
create table scenarios (
scenario_id number
default to_number(sys_guid()
,'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX')
not null
,scenario_name varchar2(200) not null
,wm_workspace varchar2(30) not null
,security_group_id number
default sys_context('CTX','SECURITY_GROUP_ID')
not null
,constraint scenario_pk primary key (scenario_id)
,constraint scenario_uk unique (wm_workspace)
);
Each scenario has an internal ID (in this case, a surrogate key generated from a GUID), a user-specified name, and a name for the workspace. I didn’t use the user-entered name for the workspace name because (a) it must be unique across the database, and (b) it is limited to 30 characters.
After a user clicks the “Create Scenario” button and enters a name, the page process calls the following procedure (within the package security_pkg associated with the context):
procedure create_scenario
(scenario_name in varchar2
,keep_refreshed in boolean := false) is
l_wm_workspace varchar2(30);
begin
-- workspace name must be unique and <=30 chars
l_wm_workspace := to_basex
(to_number(sys_guid(),'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX')
,36);
-- record the new scenario
insert into scenarios (scenario_name, wm_workspace)
values (create_scenario.scenario_name, l_wm_workspace);
-- create the workspace
dbms_wm.CreateWorkspace
(workspace => l_wm_workspace
,isrefreshed => keep_refreshed
,description => scenario_name
|| ' ('
|| sys_context('CTX','SECURITY_GROUP')
|| ')'
,auto_commit => false);
-- reset the savepoint, if required
dbms_session.clear_context
(namespace => 'CTX'
,attribute => 'WM_SAVEPOINT'
,client_id => sys_context('userenv','CLIENT_IDENTIFIER'));
-- go to the workspace on the next page view
dbms_session.set_context
(namespace => 'CTX'
,attribute => 'WM_WORKSPACE'
,value => l_wm_workspace
,client_id => sys_context('userenv','CLIENT_IDENTIFIER'));
end create_scenario;
In my APEX application Security Attributes, I have the following:
Initialization PL/SQL Code
security_pkg.init_apex_session;
Cleanup PL/SQL Code
security_pkg.cleanup_apex_session;
The procedures called above are as follows:
procedure wm_init is
begin
dbms_wm.GotoWorkspace(nvl(sys_context('CTX','WM_WORKSPACE')
,'LIVE'));
dbms_wm.GotoSavepoint(nvl(sys_context('CTX','WM_SAVEPOINT')
,'LATEST'));
end wm_init;
procedure init_apex_session is
begin
wm_init;
end init_apex_session;
procedure cleanup_apex_session is
begin
dbms_wm.GotoWorkspace('LIVE');
dbms_wm.GotoSavepoint('LATEST');
end cleanup_apex_session;
The effect of this is that for each page request, the user’s selected workspace and/or savepoint is activated, or if they have not yet chosen a workspace or savepoint, the “live” workspace and “latest” savepoint is selected (which are the defaults). At the end of each page request, the session is reset to the “live” workspace and “latest” savepoint.
“That makes two of us.”
Create a Snapshot
Here is my code to create a snapshot, using the Workspace Manager SavePoint feature:
procedure create_snapshot
(snapshot_name in varchar2) is
l_wm_workspace varchar2(30);
l_wm_savepoint varchar2(30);
begin
-- savepoint name must be unique and <=30 chars
l_wm_savepoint := to_basex
(to_number(sys_guid(),'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX')
,36);
l_wm_workspace := nvl(sys_context(CTX,'WM_WORKSPACE'), 'LIVE');
-- record the snapshot
insert into snapshots
(snapshot_name
,wm_workspace
,wm_savepoint)
values
(create_snapshot.snapshot_name
,l_wm_workspace
,l_wm_savepoint);
-- create the savepoint
dbms_wm.CreateSavepoint
(workspace => l_wm_workspace
,savepoint_name => l_wm_savepoint
,description => snapshot_name
|| ' ('
|| sys_context(CTX,'SECURITY_GROUP')
|| ')'
,auto_commit => false);
end create_snapshot;
Go to a Scenario
This sets the context for the user’s session so that subsequent page requests will load the specified Workspace. Any DML the user performs on version-enabled tables will be private to the workspace.
procedure goto_scenario (scenario_name in varchar2) is
l_wm_workspace varchar2(30);
begin
-- retrieve the workspace name for the given scenario
select s.wm_workspace into l_wm_workspace
from scenarios s
where s.scenario_name = goto_scenario.scenario_name;
-- reset the savepoint, if required
dbms_session.clear_context
(namespace => 'CTX'
,attribute => 'WM_SAVEPOINT'
,client_id => sys_context('userenv','CLIENT_IDENTIFIER'));
-- go to the workspace on the next page view
dbms_session.set_context
(namespace => 'CTX'
,attribute => 'WM_WORKSPACE'
,value => l_wm_workspace
,client_id => sys_context('userenv','CLIENT_IDENTIFIER'));
end goto_scenario;
View a Snapshot
This sets the context for the user’s session so that subsequent page requests will be viewing the specified Savepoint. The version-enabled tables will be read-only; any DML on them will raise an exception.
procedure goto_snapshot (snapshot_name in varchar2) is
l_wm_workspace varchar2(30);
l_wm_savepoint varchar2(30);
begin
-- retrieve the details for the given snapshot
select s.wm_workspace
,s.wm_savepoint
into l_wm_workspace
,l_wm_savepoint
from snapshots s
where s.snapshot_name = goto_snapshot.snapshot_name;
-- set the workspace and savepoint on the next page request
dbms_session.set_context
(namespace => 'CTX'
,attribute => 'WM_WORKSPACE'
,value => l_wm_workspace
,client_id => sys_context('userenv','CLIENT_IDENTIFIER'));
dbms_session.set_context
(namespace => 'CTX'
,attribute => 'WM_SAVEPOINT'
,value => l_wm_savepoint
,client_id => sys_context('userenv','CLIENT_IDENTIFIER'));
end goto_snapshot;
Go to Live
When the user is in a Scenario, and they wish to go back to “Live”, they can click a button which executes the following procedure. Their next page request will go to the LATEST savepoint in the LIVE workspace.
procedure goto_live is
begin
dbms_session.clear_context
(namespace => 'CTX'
,attribute => 'WM_WORKSPACE'
,client_id => sys_context('userenv','CLIENT_IDENTIFIER'));
dbms_session.clear_context
(namespace => 'CTX'
,attribute => 'WM_SAVEPOINT'
,client_id => sys_context('userenv','CLIENT_IDENTIFIER'));
end goto_live;
Go to Latest
When the user is viewing a Snapshot, and they wish to go back to “Latest” (so they do DML, etc.), they can click a button which executes the following procedure. This works regardless of whether they are in the Live workspace or viewing a scenario. Their next page request will go to the LATEST savepoint.
procedure goto_latest is
begin
dbms_session.clear_context
(namespace => 'CTX'
,attribute => 'WM_SAVEPOINT'
,client_id => sys_context('userenv','CLIENT_IDENTIFIER'));
end goto_latest;
Compare two Scenarios
When the user wishes to analyze the differences between two scenarios, or between a scenario and the Live workspace, there is a two-step process:
The user selects two Scenarios (or the “Live” workspace) from some select lists; the return value of these select lists should be the wm_workspace column from the table, or 'LIVE' for the Live workspace.
The user clicks a button to execute the find_diffs1 procedure (see below).
The page has a report on the view mytable_DIFF.
procedure find_diffs1
(wm_workspace1 in varchar2
,wm_workspace2 in varchar2) is
begin
dbms_wm.SetDiffVersions
(workspace1 => wm_workspace1
,workspace2 => wm_workspace2
,onlyModified => true);
end find_diffs1;
Compare Snapshots
When the user wishes to analyze the differences between two snapshots (in any workspace), or between the latest data and a snapshot, a similar process is used:
The user selects two Snapshots (or the “Latest” snapshot for either the Live workspace or a given Scenario); the return values of these select lists should be the wm_workspace and wm_savepoint, e.g. wm_workspace||':'||wm_savepoint.
The user clicks a button to execute the find_diffs2 procedure (see below).
The page has a report on the view mytable_DIFF.
procedure find_diffs
(workspace_savepoint1 in varchar2
,workspace_savepoint2 in varchar2) is
l_sep1 number := instr(workspace_savepoint1,':');
l_sep2 number := instr(workspace_savepoint2,':');
begin
dbms_wm.SetDiffVersions
(workspace1 => substr(workspace_savepoint1, 1, l_sep1-1)
,savepoint1 => substr(workspace_savepoint1, l_sep1+1)
,workspace2 => substr(workspace_savepoint2, 1, l_sep2-1)
,savepoint2 => substr(workspace_savepoint2, l_sep2+1)
,onlyModified => true);
end find_diffs;
Merge a Scenario
In my system, I don’t allow users to create scenarios within scenarios, although this is possible with Workspace Manager. If the user wishes to merge all changes in a Scenario to Live, they click a button to execute the following procedure:
wm_error_55 exception;
wm_error_56 exception;
pragma exception_init(wm_error_55, -20055);
pragma exception_init(wm_error_56, -20056);
procedure merge_scenario is
l_wm_workspace varchar2(30);
begin
l_wm_workspace := sys_context('CTX','WM_WORKSPACE');
goto_live;
wm_init;
-- merge the workspace
dbms_wm.MergeWorkspace
(workspace => l_wm_workspace
,remove_workspace => true
,auto_commit => false);
-- delete the scenario
delete scenarios s
where s.wm_workspace = merge_scenario.scenario_id;
exception
when wm_error_55 or wm_error_56 then
-- unable to merge due to conflicts
-- go back into the workspace
dbms_session.set_context
(namespace => 'CTX'
,attribute => 'WM_WORKSPACE'
,value => l_wm_workspace
,client_id => sys_context('userenv','CLIENT_IDENTIFIER'));
-- caller should redirect user to the "resolve conflicts" page
raise e_merge_conflict;
end merge_scenario;
This will fail with an exception if there are any conflicting changes in the Live workspace, e.g.:
a record was updated in the scenario, but was deleted in Live
a record was updated or deleted in the scenario, but also updated in Live
a record was inserted in the scenario, but another record with the same PK was inserted in Live
If the workspace had been created with the isrefreshed option, the changes being made in Live will be automatically copied to the workspace so these conflicts should be minimised; however, conflicts cannot always be avoided. To give the user the ability to analyze the conflicts, you would perform the following steps:
Allow the user to select an action for each record in conflict – either “PARENT” (keep the parent, i.e. discard the change in the scenario) or “CHILD” (keep the child, i.e. discard the change made in Live).
For each record, call dbms_wm.ResolveConflicts (see example below).
The ResolveConflicts procedure takes a where clause that identifies the row (or rows) to mark as resolved. In my case, I just call it with the id for each record the user chose:
for r in (
...query on something, e.g. an APEX collection...
) loop
dbms_wm.ResolveConflicts
(workspace => sys_context('CTX','WM_WORKSPACE')
,table_name => 'MYTABLE'
,where_clause => 'id=' || r.id
,keep => r.action /*'PARENT' or 'CHILD'*/);
end loop;
If the conflicts are across multiple tables, the UI will probably be a bit more complicated. You’d have to resolve conflicts on all the affected tables before the Merge can succeed.
“Don’t let a white fence and a promotion end the world for you.”
Delete a Scenario
Deleting a scenario uses RemoveWorkspace:
procedure delete_scenario
(scenario_name in varchar2) is
l_wm_workspace varchar2(30);
begin
-- retrieve the workspace name for the given scenario
select s.wm_workspace into l_wm_workspace
from scenarios s
where s.scenario_name = delete_scenario.scenario_name;
-- get out of the workspace
goto_live;
wm_init;
-- delete the workspace
dbms_wm.RemoveWorkspace
(workspace => l_wm_workspace
,auto_commit => false);
delete scenarios s
where s.wm_workspace = l_wm_workspace;
end delete_scenario;
Delete a Snapshot
Deleting a snapshot uses DeleteSavepoint:
procedure delete_snapshot
(snapshot_name varchar2) is
l_wm_workspace varchar2(30);
l_wm_savepoint varchar2(30);
begin
-- retrieve the details for the given snapshot
select s.wm_workspace
,s.wm_savepoint
into l_wm_workspace
,l_wm_savepoint
from snapshots s
where s.snapshot_name = delete_snapshot.snapshot_name;
-- get out of the snapshot/scenario:
goto_latest;
wm_init;
-- delete the savepoint
dbms_wm.DeleteSavepoint
(workspace => nvl(l_wm_workspace,'LIVE')
,savepoint_name => l_wm_savepoint
,auto_commit => false);
delete snapshots s
where s.wm_savepoint = l_wm_savepoint;
end delete_snapshot;
Row History
One of the requirements of my application was to show a report of the entire history of edits to each record in a table. Since I’m already going to version-enable this table, it makes sense to take advantage of the Row History feature of Oracle Workspace Manager.
When you version-enable a table, OWM creates a view called MYTABLE_HIST which includes all the columns of the table, plus the following columns: WM_WORKSPACE, WM_VERSION, WM_USERNAME, WM_OPTYPE, WM_CREATETIME, and WM_RETIRETIME. By default, when you version-enable a table, OWM keeps only a minimal set of history in order to support other features in use, such as snapshots. In order to retain a complete history of changes to the record, enable versioning with the View Without Overwrite history option:
begin
dbms_wm.EnableVersioning('MYTABLE'
,hist => 'VIEW_WO_OVERWRITE');
end;
This stops OWM from overwriting the history of changes to each record, so it can be queried via the _HIST view.
Now, I wanted to expose the contents of this view to my users, and for each history record show Who did it and When. “When” is easily answered by WM_CREATETIME, which is a TIMESTAMP WITH TIME ZONE. “Who” would normally be answered by WM_USERNAME, but since we’re in APEX, this will always be 'APEX_PUBLIC_USER' which is not very useful. Therefore, I have an ordinary column in my table called DB$UPDATED_BY which is set by the following ordinary trigger:
create trigger MYTABLE$TRG
before update on MYTABLE
for each row
begin
:new.db$updated_by :=
coalesce(sys_context('APEX$SESSION','APP_USER')
,sys_context('USERENV','SESSION_USER'));
end MYTABLE$TRG;
This means my report will show the actual APEX username of who created or updated the record.
The WM_OPTYPE column in the _HIST view will be 'I' (inserted), 'U' (updated), or 'D' (deleted). I can translate this code into user-friendly values for reporting purposes, but there is one problem: when a row is deleted, the _HIST table knows the username who deleted the record, but we never recorded the APEX username. Our db$updated_by column wasn’t changed, so it simply shows whoever last updated the records before it was deleted.
To solve this, we have two options: (1) Write the application to do a quick no-change UPDATE on each row immediately before deleting it; then do some fancy footwork in the view to show this as a “Delete” operation. (2) Don’t allow the application to execute actual DELETEs – in other words, use a “soft-delete” design.
I’ve gone with option (2) which is what the users needed anyway – they needed to be able to Delete and Undelete records at will, so I’ve only granted INSERT and UPDATE on the table and the application will translate a request to “DELETE” into an update of a “deleted” flag on the table. A request to Undelete a record is simply another update to set the “deleted” flag to NULL. All reports in the application have a predicate to filter out any deleted records unless the user is viewing the “recycle bin”. In addition, if the user is viewing a deleted record, I put the form into “Readonly” mode – the only thing they can do is Undelete it (thereafter, they can modify the record if they wish).
I’ve created the following view in order to show the history of changes to a record:
create or replace view mytable_hist_vw as
select x.id, x.name, etc.
,l.wm_createtime as op_timestamp
,case
when x.wm_optype = 'U'
and x.deleted_ind = 'Y'
and lag(x.deleted_ind,1)
over (partition by x.id
order by x.wm_createtime) is null
then 'Deleted'
when x.wm_optype = 'U'
and x.deleted_ind is null
and lag(x.deleted_ind,1)
over (partition by x.id
order by x.wm_createtime) = 'Y'
then 'Undeleted'
when x.wm_optype = 'I' then 'Created'
when x.wm_optype = 'U' then 'Updated'
when x.wm_optype = 'D' then 'Deleted permanently'
end as op_desc
,case
when x.wm_optype = 'D'
then x.wm_username
else x.db$updated_by
end as op_by
from mytable_hist x
I interpret an WM_OPTYPE of 'D' as “Deleted permanently”. This might occur if we do a delete directly on the table, e.g. via a data fix run directly on the database. In this case I report the username according to the wm_username column since we won’t have the APEX user name.
A user sent me a CSV they had downloaded from my APEX application and then subsequently updated. I needed to know which database column was the source for each column in the spreadsheet; this was not as simple as you might think because the labels from this report (that has a bewilderingly large number of columns) were quite often very different from the database column name.
To map their spreadsheet columns to database columns I used this simple query:
select x.interactive_report_id, x.report_label, x.column_alias
from apex_application_page_ir_col x
where x.application_id = <my app id>
and x.page_id = <my page id>
order by x.interactive_report_id, x.report_label;
After upgrading APEX I found this query useful to review all the plugins I had installed across multiple workspaces and in multiple applications to find ones that needed to be upgraded.
select name
,plugin_type
,version_identifier
,workspace
,application_id
,application_name
from APEX_APPL_PLUGINS
where workspace not in ('INTERNAL','COM.ORACLE.CUST.REPOSITORY')
order by name, workspace, application_id;
Face it: your users are in love with Microsoft Excel, and you can’t do anything about it.
You can show them the excellent Interactive Report and Interactive Grid features of APEX, and train some of your users to use some of their capabilities, but at the end of the day, your users will still download the data into their spreadsheet software to do their own stuff with it.
Once they’ve finished with the data, odds are they’ll come back to you and ask “how do I upload this data back into APEX?” and expect that the answer is merely a flip of a switch to enable a built-in APEX feature. Of course, you know and I know that this is not necessarily a simple thing; it is certainly not just an option to be enabled. Depending on what exactly they mean by “upload this data” it may be reasonably easy to build or it could get quite complex.
File Formats
Typically the data will be provided in some kind of text format (CSV, tab delimited, fixed width) or binary file (XLS or XLSX). If they have copied the data from a table in Excel, it will be in tab-delimited format in the clipboard. Perhaps in some odd instances the user will have received the data from some system in fixed width, XML or JSON format – but this is rare as this is typically part of the build of a system integration solution and users expect these to be “harder”.
Actual Requirements
When your user wants you to provide a facility for uploading data, there are some basic questions you’ll need to ask. Knowing these will help you choose the right approach and solution.
Where are the files – i.e. are they stored on the database server, or is the user going to upload them via an online APEX application
How much automation is required, how often – i.e. is this a ad-hoc, rare situation; something they need to do a few times per month; or something that is frequent and needs to be painless and automatic?
What are the files named – i.e. if they are stored on the database server, do we know what the files will be called?
How consistent is the data structure?
Data Structure
That last one is important. Will the columns in the file remain the same, or might they change all the time? If the structure is not amenable to automated data matching, can the file structure be changed to accommodate our program? Is the structure even in tabular form (e.g. is it a simple “header line, data line, data line” structure or are there bits and pieces dotted around the spreadsheet)? If it’s an Excel file, is all the data in one sheet, or is it spread across multiple sheets? Should all the sheets be processed, or should some of them be ignored? Can the columns vary depending on requirement – might there be some columns in one file that don’t exist in other files, and vice versa?
Finally, is all the data to be loaded actually encoded in text form? This is an issue where a spreadsheet is provided where the user has, trying to be helpful, highlighted rows with different colours to indicate different statuses or other categorising information. I’ve received spreadsheets where some data rows were not “real” data rows, but merely explanatory text or notes entered by the users – since they coloured the background on those rows in grey, they expected my program to automatically filter those rows out.
Solution Components
Any solution for processing uploaded files must incorporate each of the following components:
Load – read the raw file data
Parse – extract the text data from the file
Map – identify how the text data relates to your schema
Validate – check that the data satisfies all schema and business rule constraints
Process – make the relevant changes in the database based on the data
Each of these components have multiple solution options, some are listed here:
Map – Fixed (we already know which columns appear where) (e.g. SQL*Loader Express Mode); Manual (allow the user to choose which column maps to which target); or A.I. (use some sort of heuristic algorithm to guess which column maps to what, e.g. based on the header labels)
Validate – Database constraints; and/or PL/SQL API
Process – INSERT; MERGE; or call a PL/SQL API
The rest of this post is focussed primarily on Parsing and Mapping Text and Excel files.
Solutions for Text files
These are some solutions for parsing text files (CSV, tab-delimited, fixed-width, etc.) that I’ve used or heard of. I’m not including the more standardised data interchange text formats in this list (e.g. XML, JSON) as these are rarely used by end users to supply spreadsheet data. “Your Mileage May Vary” – so test and evaluate them to determine if they will suit your needs.
LOB2Table PL/SQL (CSV, delimited and fixed width files) – Michael Schmid, 2015
Excel2Collection APEX process plugin (CSV, delimited, XLS and XLSX files) – Anton Scheffer, 2013
csv2db – load CSV files from the command line (Linux). Gerald Venzl, 2019
KiBeHa’s CSV parser – a simple CSV parser in PL/SQL written by Kim Berg Hansen, 2014 (this is a simplistic parser that will not handle all CSV files, e.g. ones that have embedded delimiters with double-quoted text)
It could be noted here that the Interactive Grid in APEX 5.1 and later does support Paste; if the user selects some data from Excel, then selects the corresponding columns and rows in the grid, they can Paste the tab-delimited data right in. Of course, this requires that the columns be in exactly the right order.
External Table
This uses the SQL*Loader access driver and you can look up the syntax in the Oracle docs by searching for “ORACLE_LOADER”. Since Oracle 12.1 you can use the simple “FIELDS CSV” syntax to parse CSV files, e.g.:
create table emp_staging
( emp_no number(4)
, name varchar2(10)
, ...
)
organization external
( default directory ext_dir
access parameters
( records delimited by newline
FIELDS CSV
reject rows with all null fields
)
location ( 'emp.dat' )
)
reject limit unlimited
Since Oracle 12.1 the sqlldr command-line utility supports “Express Mode” which by default reads a CSV file, and loads the data into a given table. Read this quick intro here. This can come in handy for scripting the load of a number of CSV files on an ad-hoc basis into tables that already have exactly the same structure as those CSV files.
> sqlldr userid=scott/tiger table=emp
This expects to find a file named “emp.dat” which contains CSV data to be loaded into the nominated table. Internally, it creates a temporary external table to load the data. Additional parameters can be added to change the filename, delimiters, field names, and other options.
APEX Data Workshop
The APEX Data Workshop is found under SQL Workshop > Utilities > Data Workshop and allows the developer to quickly load data from a CSV, tab-delimited, XML, or copy-and-paste from Excel into an existing or new table. This can be very handy when your client sends you some spreadsheets and you need to quickly load the data as one or more tables.
A related utility is the Create Application from Spreadsheet which does the same thing, plus creates a basic application to report and maintain the data in the new table.
APEX Data Loader Wizard
If your users need to load data on an ad-hoc, on-demand basis, and you don’t know necessarily what the structure of the files will be (e.g. the headings might change, or the order of the columns might change), you can use the APEX Data Loader Wizard to build an APEX application that guides your users in loading, mapping, and validating the data for themselves. If required you can customise the generated pages to add your own processing.
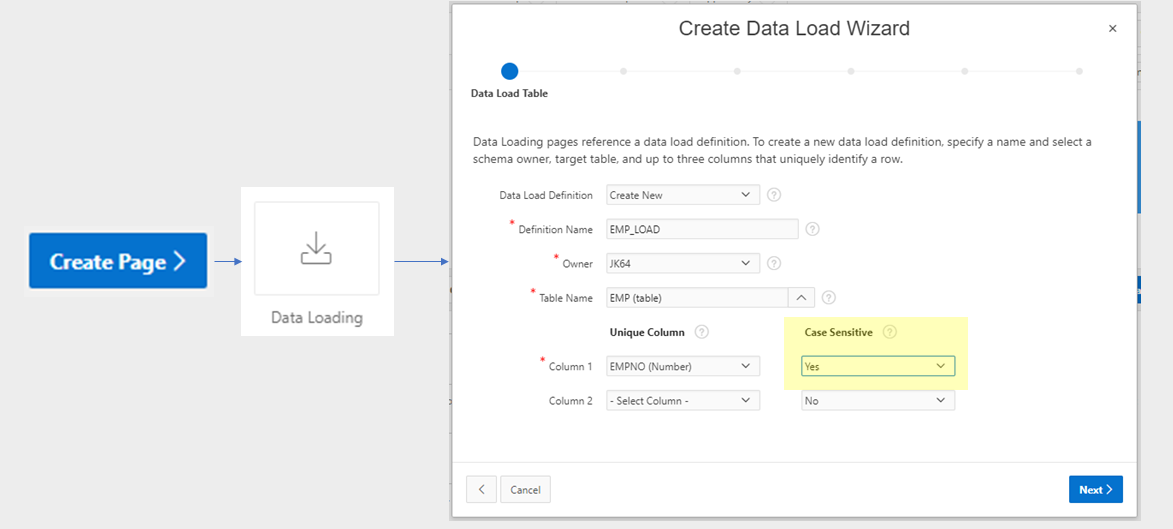
To create the wizard, click Create Page, choose Data Loading, and follow the steps to define the Data Load Definition and its associated pages. The definition determines the target table, the unique column(s) for data matching, transformation rules, and lookups (e.g. to get foreign keys for reference tables). Once this is done, the following four pages will be created for you:
You can customise these pages to modify the look and feel (e.g. moving some of the more complicated options in a collapsible region), or to add your own custom processing for the data.
For example, I will often add an additional process on either the 3rd page (to be run after the “Prepare Uploaded Data” process) that will do further processing of the loaded data. The process would be set up to only run When Button Pressed = “NEXT” and would have a Condition “Item is NULL or Zero” = “P111_ERROR_COUNT”. The result is that on the Data Validation (3rd) page, after reviewing the validation summary, the user clicks “Next” and the data is loaded and processed.
Alternatively, I sometimes want the user to view additional validation or summary information on the 4th page before doing further processing. In this case, I would add the process to the Data Load Results (4th) page, When Button Pressed = “FINISH”. For this to work, you need to modify the FINISH button to Submit the page (instead of redirecting). I also would add a CANCEL button to the page so the user can choose to not run the final processing if they wish.
Updating a Data Load Definition
The Data Load Definitions (one for each target table) may be found under Shared Components > Data Load Definitions. Here, you can modify the transformations and lookup tables for the definition. However, if the table structure has changed (e.g. a new column has been added), it will not automatically pick up the change. To reflect the change in the definition, you need to follow the following steps:
Edit the Data Load Definition
Click Re-create Data Load Pages
Delete the new generated pages
This refreshes the Data Load Definition and creates 4 new pages for the wizard. Since you already had the pages you need (possibly with some customisations you’ve made) you don’t need the new pages so you can just delete them.
CSV_UTIL_PKG
The Alexandria PL/SQL Library includes CSV_UTIL_PKG which I’ve used in a number of projects. It’s simple to use and effective – it requires no APEX session, nothing but PL/SQL, and can be called from SQL for any CLOB data. It’s handy when you know ahead of time what the columns will be. You could read and interpret the headings in the first line from the file if you want to write some code to automatically determine which column is which – but personally in this case I’d lean towards using the APEX Data Loader Wizard instead and make the user do the mapping.
If you don’t already have the full Alexandria library installed, to use this package you must first create the schema types t_str_array and t_csv_tab. You will find the definition for these types in setup/types.sql. After that, simply install ora/csv_util_pkg.pks and ora/csv_util_pkg.pkb and you’re good to go.
In the example below I get a CSV file that a user has uploaded via my APEX application, convert it to a CLOB, then parse it using CSV_UTIL_PKG.clob_to_csv:
procedure parse_csv (filename in varchar2) is
bl blob; cl clob;
begin
select x.blob_content into bl
from apex_application_temp_files x
where x.name = parse_csv.filename;
cl := blob_to_clob(bl);
insert into csv_staging_lines
(session_id, line_no, school_code, school_name
,line_type, amount, line_description)
select sys_context('APEX$SESSION','APP_SESSION')
,line_number - 1
,c001 as school_code
,c002 as school_name
,c003 as line_type
,replace(replace(c004,'$',''),',','') as amount
,c005 as line_description
from table(csv_util_pkg.clob_to_csv(cl, p_skip_rows => 1))
where trim(line_raw) is not null;
end parse_csv;
This PL/SQL package written and maintained by Michael Schmid parses CSV, delimited or Fixed-width data embedded in any LOB or VARCHAR2, including in a table with many records. The data can be read from any CLOB, BLOB, BFILE, or VARCHAR2. This makes it quite versatile, it reportedly provides excellent performance, and it includes a pipelined option. It will read up to 200 columns, with a maximum of 32K per record.
It requires execute privileges on SYS.DBMS_LOB and SYS.UTL_I18N and creates some object types and a database package. You can download the source from sourceforge. It appears to be well supported and was most recently updated in June 2018. I recommend checking it out.
select d.deptno, d.dname,
t.row_no,
t.column1, t.column2,
t.column3, t.column4 from dept d
cross join table(
lob2table.separatedcolumns(
d.myclob, /* the data LOB */
chr(10), /* row separator */
',', /* column separator */
'"' /* delimiter (optional) */
) ) t;
Excel2Collection
This is a process type APEX plugin written by Anton Scheffer (AMIS) in 2013, and has been actively maintained since then. You can download it from here or find it on apex.world.
The plugin detects and parses CSV, XLS, XML 2003 and XLSX files which makes it very versatile. It will load 50 columns from the spreadsheet into an APEX collection (max 10K rows). If you need to load larger spreadsheets you can send Anton a donation and your email address and he’ll send you a database package that can handle larger files.
Solutions for Excel files
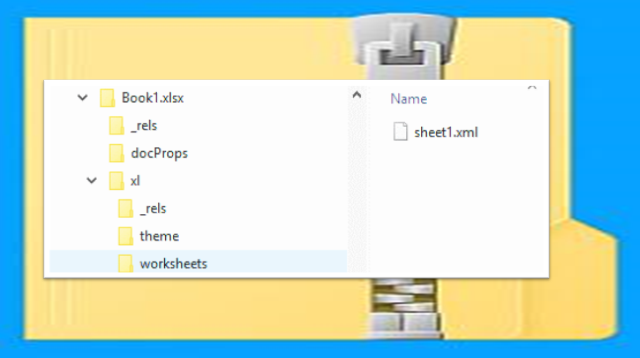
The first thing to know about XLSX files is that they are basically a ZIP file containing a folder structure filled with a number of XML documents. Parsing an XLSX file, therefore, involves first unzipping the file, reading the relevant XML documents and parsing their contents. As usual with any Microsoft file format, the internal structure of these XML documents can be quite complex so I’d much rather leave the work to someone who has already worked out the details. Thankfully, this has largely been done.
These are some solutions for loading data from Microsoft Excel files (XLS, XLSX) that I’ve come across. Again, “YMMV” – so test and evaluate them to determine if they will suit your needs.
The Alexandria PL/SQL Library includes OOXML_UTIL_PKG which provides a number of utilities for parsing (and creating) XLSX, DOCX and PPTX files. It provides functions to get file attributes (including title, creator, last modified) and a list of worksheets in an XLSX. It provides functions to get the text data from any cell in any sheet, although for reasonable performance if you need more than one cell you should use the functions that returns a range of cells in one go.
Installation requires zip_util_pkg, sql_util_pkg, string_util_pkg, xml_util_pkg, xml_stylesheet_pkg, and ooxml_util_pkg, all of which are in the Alexandria library. Given this list of dependencies (and probably others I didn’t notice) I recommend installing the whole library – after all, there’s a lot of useful stuff in there so it’s worth it.
declare
l_blob blob;
l_names t_str_array := t_str_array('B3','C3','B4','C4','B5','C5');
l_values t_str_array;
begin
l_blob := file_util_pkg.get_blob_from_file('EXT_DIR','sample.xlsx');
l_values := ooxml_util_pkg.get_xlsx_cell_values(l_blob, 'Sheet1', l_names);
for i in 1..l_values.count loop
dbms_output.put_line(l_names(i) || ' = ' || l_values(i));
end loop;
end;
As noted above, the Excel2Collection APEX plugin can detect and parse XLS, XML 2003 and XLSX files (as well as CSV files). The fact that it detects the file type automatically is a big plus for usability.
Apache POI
This solution involves installing Apache POI (“Poor Obfuscation Implementation”), a Java API for Microsoft products, into the database. The solution described by Christian Neumueller here parses XLS and XLSX files although it is admittedly not very efficient.
XLSX_PARSER
In 2018 Carsten Czarski posted a blog article “Easy XLSX Parser just with SQL and PL/SQL” listing a simple database package that parses XLSX files. This uses APEX_ZIP which comes with APEX, although using it does not require an APEX session or collections. It can load the file from a BLOB, or from APEX_APPLICATION_TEMP_FILES. It uses XMLTable to parse the XML content and return the text content of up to 50 columns for any worksheet in the file. It may be modified to support up to 1,000 columns.
To get a list of worksheets from a file:
select * from table(
xlsx_parser.get_worksheets(
p_xlsx_name => :P1_XLSX_FILE
));
I used this solution in a recent APEX application but the client was still on APEX 4.2 which did not include APEX_ZIP; so I adapted it to use ZIP_UTIL_PKG from the Alexandria PL/SQL Library. If you’re interested in this implementation you can download the source code from here.
ExcelTable
ExcelTable is a powerful API for reading XLSX, XLSM, XLSB, XLS and ODF (.ods) spreadsheets. It is based on PL/SQL + Java and reportedly performs very well. It requires a grant on DBMS_CRYPTO which allows it to read encrypted files. It includes an API for extracting cell comments as well. It can return the results as a pipelined table or as a refcursor. It knows how to interpret special cell values and error codes such as booleans, #N/A, #DIV/0!, #VALUE!, #REF! etc.
It includes API calls that allow you to map the input from a spreadsheet to insert or merge into a table, defining how to map columns in the spreadsheet to your table columns, which may improve throughput and may mean it uses less memory to process large files.
The API was written by Marc Bleron in 2016 and has been in active maintenance since then (latest update 22/10/2018 as of the writing of this article). You can read more details and download it from here: https://github.com/mbleron/ExcelTable
EDIT 17/12/2018: thanks to Nicholas Ochoa who alerted me to this one.
APEX 19.1 Statement of Direction
DISCLAIMER: all comments and code samples regarding APEX 19.1 in this article are based primarily on the Statement of Direction and are subject to Oracle’s “Safe Harbour” provision and must therefore not be relied on when making business decisions.
The SOD for the next release of APEX includes the following note, which is exciting:
“New Data Loading: The data upload functionality in SQL Workshop will be modernized with a new drag & drop user interface and support for native Excel, CSV, XML and JSON documents. The same capabilities will be added to the Create App from Spreadsheet wizard and a new, public data loading PL/SQL API will be made available.”
Whether this release will include corresponding enhancements to the APEX Data Loader Wizard remains to be seen; I hope the wizard is enhanced to accept XLSX files because this is something a lot of my users would be happy about.
EDIT 6/2/2019: Early Adopter of APEX 19.1 reveals that the Data Workshop supports loading CSV, XLSX, XML and JSON data. If you load an XLSX file, it will allow you to choose which worksheet to load the data from (only one worksheet at a time, though). Also, the Data Loader Wizard has not been updated to use the new API, it still only supports loading from CSV files. This is on the radar for a future version of APEX, however.
APEX_DATA_PARSER
The most promising part of the APEX 19.1 SOD is the PL/SQL API bit, which will mean no plugins or 3rd-party code will be needed to parse XLSX files. It appears the package will be called APEX_DATA_PARSER, providing routines to automatically detect and parse file formats including XLSX, XML, JSON and CSV/tab-delimited files, e.g.:
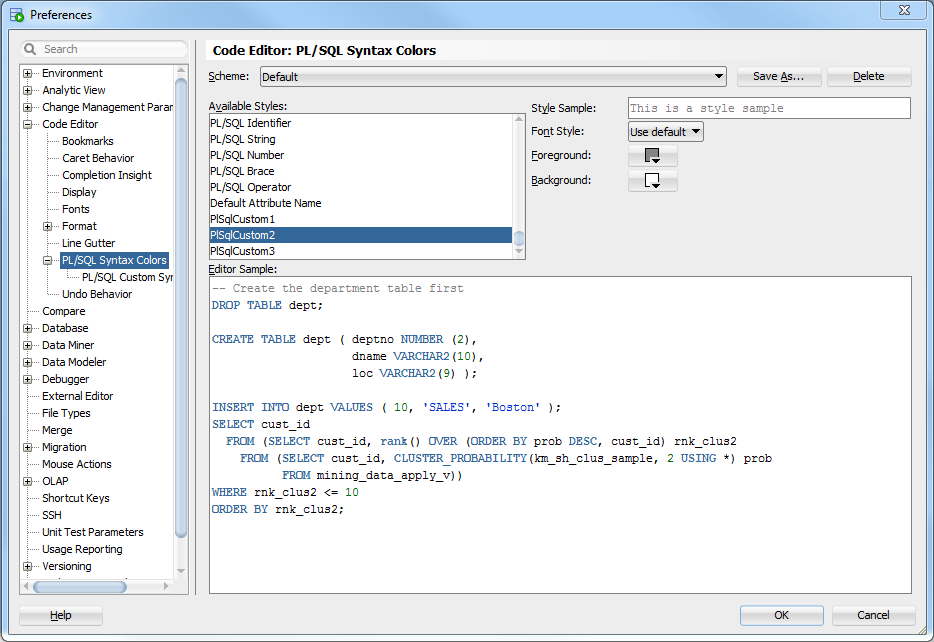
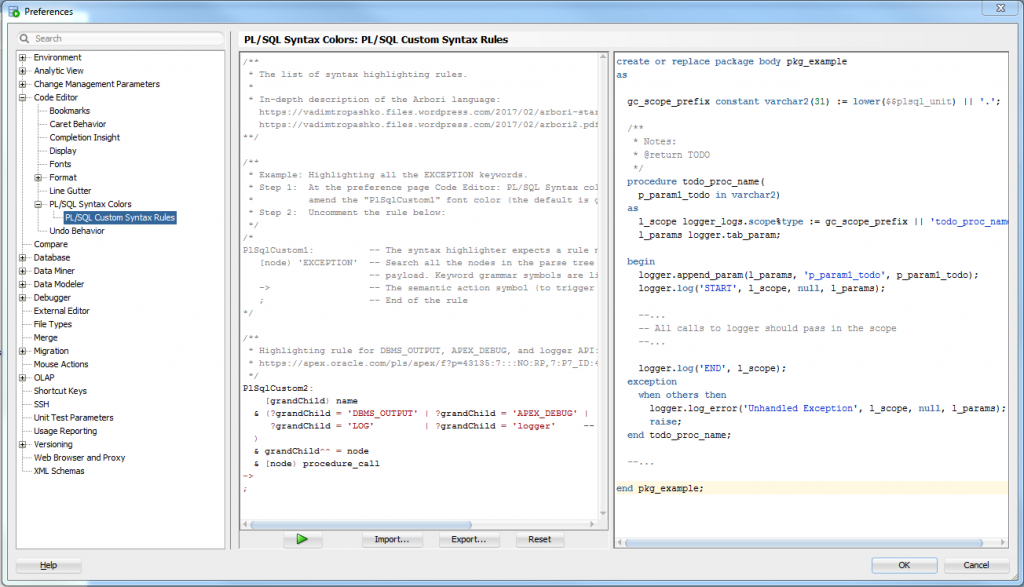
Oracle SQL Developer 18.3 adds this feature with PL/SQL Custom Syntax Rules – and the best thing is, these rules are enabled by default so you don’t have to do anything. Any calls to logger, dbms_output and apex_debug will be greyed out.
You can customise the colour for this rule in Tools -> Preferences -> Code Editor -> PL/SQL Syntax Colors – the one for logger etc. is called “PlSqlCustom2”:
You can view (and edit, if you want) the rule in PL/SQL Custom Syntax Rules:
I’m not very familiar with the syntax but you can add additional libraries by adding more lines like this to the rule:
| ?grandChild = 'MYCUSTOMLOGGER'
The only thing missing is that it doesn’t pick up the standard logger variable declarations (scope and params). I haven’t worked out how to include these in the rule yet.
Pictured: Hamersley Gorge, Karajini National Park, Western Australia
Why is this blog called “Jeff Kemp on Oracle”?
Pretty much my entire career has been underpinned by the Oracle database. My first few I.T. jobs involved maintaining and building Oracle Forms and Reports. SQL and PL/SQL have been my indispensable two-pronged tool since day one and remain so today. Through fortuitous circumstance I had the opportunity to swap Forms for APEX quite a few years ago and I’ve been busy working on APEX applications since then.
The Oracle database is pretty old, and it’s huge and horrendously complex. It’s not the most popular – it certainly is among the “most dreaded” technologies in recent surveys; and (apart from XE) it is not cheap. But it unarguably has been, and still is, a major force to be reckoned with. When handled well it is still top of the line when it comes to performance and reliability.
Oracle APEX started out as a kid brother to Oracle Forms back in the mid-2000s, and has since quietly risen to be a nimble and capable development platform. It allows developers from different backgrounds to be productive very quickly.
If you’re a web developer skilled with HTML, CSS and Javascript, you can let APEX handle the database plumbing for you and build beautiful, functional and responsive web sites.
If you’re a PL/SQL nut like me, you can let APEX handle all the user interface and web browser complexities and build beautiful, functional and responsive web sites.
Either way, APEX gives you a starting point to learn the “other side”, whichever angle you came from.
Normally, in a report you can add a checkbox to select records like this:
select apex_item.checkbox2(1,x.id) as sel
,x.mycol
,...
from mytable x
And process the selected records using a process like this:
for i in 1..apex_application.g_f01.count loop
l_id := apex_application.g_f01(i);
-- ... process ...
end loop;
Since we have set the value of the checkbox to the record ID we can just get that ID from the resulting g_f01 array. What if we need multiple columns in our processing? There are a few approaches we could use:
Option 1. Re-query the table to get the corresponding data for the record ID
This is possible as long as the record ID is a unique identifier for the results in the report. A downside is that this involves running an extra query to get the corresponding data which might add a performance problem. An advantage is that the query can bring back as much data as we need – so if we need more than, say, 6 or 7 columns, this would be a reasonable approach.
Option 2. Concatenate the extra data into the checkbox value
For example:
select apex_item.checkbox2(1, x.col1 || ':' || x.col2) as sel
,x.mycol
,...
from mytable x
This requires parsing the value in the process, e.g.:
for i in 1..apex_application.g_f01.count loop
l_buf := apex_application.g_f01(i);
l_col1 := substr(l_buf, 1, instr(l_buf,':')-1);
l_col2 := substr(l_buf, instr(l_buf,':')+1);
-- ... process ...
end loop;
Option 3. Add extra hidden items to hold the data
select apex_item.checkbox2(1,rownum)
|| apex_item.hidden(2,rownum)
|| apex_item.hidden(3,col1)
|| apex_item.hidden(4,col2)
as sel
,x.mycol
,...
from mytable x
Note: using “rownum” like this allows selecting the data from the row in the report, even if the underlying view for the report has no unique values that might be used.
Processing involves getting the selected rownums from the checkbox, then searching the hidden item (#2) for the corresponding rownum. This is because the g_f01 array (being based on a checkbox) will only contain elements for the selected records, whereas the g_f02, g_f03, etc. arrays will contain all elements from all records that were visible on the page.
for i in 1..apex_application.g_f01.count loop
for j in 1..apex_application.g_f02.count loop
-- compare the ROWNUMs
if apex_application.g_f02(j) = apex_application.g_f01(i)
then
l_col1 := apex_application.g_f03(j);
l_col2 := apex_application.g_f04(j);
-- ... process ...
end if;
end loop;
end loop;
This approach helped when I had a report based on a “full outer join” view, which involved multiple record IDs which were not always present on each report row, and I had multiple processes that needed to process based on different record IDs and other data, which would have been too clumsy to concatenate and parse (as per option #2 above).