A few years ago I raised an enhancement request for SQL Developer to add custom highlighting, specifically to “grey out” all the calls to logger throughout my code. I blogged about this here.
Oracle SQL Developer 18.3 adds this feature with PL/SQL Custom Syntax Rules – and the best thing is, these rules are enabled by default so you don’t have to do anything. Any calls to logger, dbms_output and apex_debug will be greyed out.
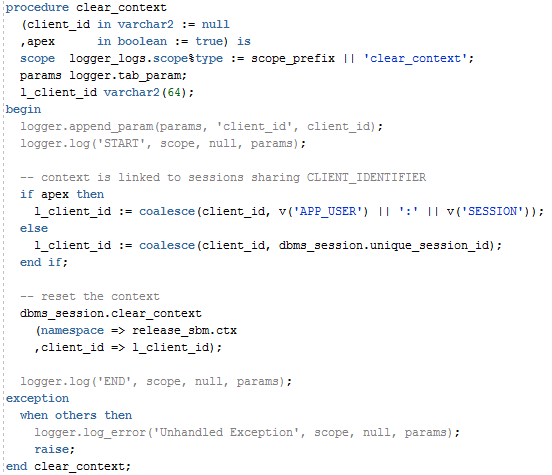
You can customise the colour for this rule in Tools -> Preferences -> Code Editor -> PL/SQL Syntax Colors – the one for logger etc. is called “PlSqlCustom2”:
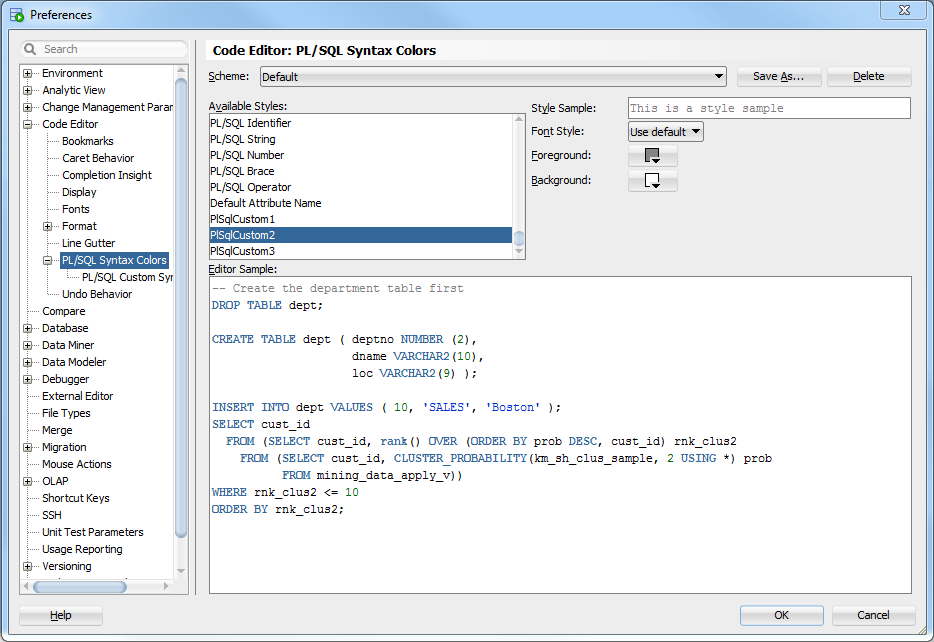
You can view (and edit, if you want) the rule in PL/SQL Custom Syntax Rules:
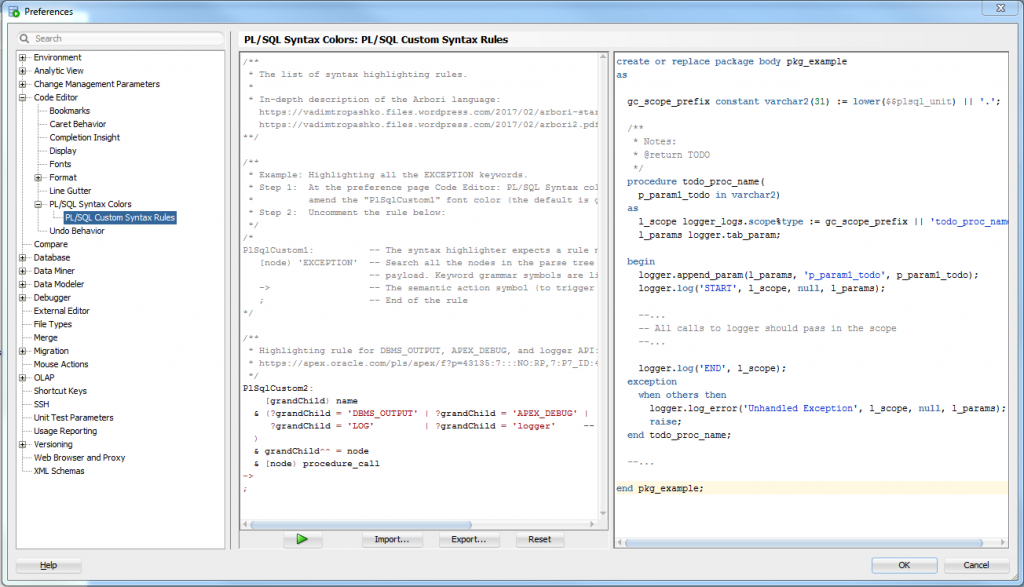
I’m not very familiar with the syntax but you can add additional libraries by adding more lines like this to the rule:
| ?grandChild = 'MYCUSTOMLOGGER'
The only thing missing is that it doesn’t pick up the standard logger variable declarations (scope and params). I haven’t worked out how to include these in the rule yet.
UPDATE 11/10/2018 – new feature added in Oracle SQL Developer 18.3
Juergen Schuster, who has been enthusiastically trying OraOpenSource Logger, raised an idea for the debug/instrumentation library requesting the addition of a standard synonym “l” for the package. The motive behind this request was to allow our PL/SQL code to remain easy to read, in spite of all the calls to logger sprinkled throughout that are needed for effective debugging and instrumentation.
In the judgement of some (myself included) the addition of the synonym to the standard package would run the risk of causing clashes on some people’s systems; and ensuring that Logger is installable on all systems “out of the box” should, I think, take precedence.
However, the readability of code is still an issue; so it was with that in mind that I suggested that perhaps an enhancement of our favourite development IDE would go a long way to improving the situation.
Therefore, I have raised the following enhancement request at the SQL Developer Exchange:
Logger: show/hide or dim (highlight) debug/instrumentation code
“The oracle open source Logger instrumentation library is gaining popularity and it would be great to build some specific support for it into SQL Developer, whether as a plugin or builtin. To enhance code readability, it would be helpful for PL/SQL developers to be able to hide/show, or dim (e.g. grey highlight) any code calling their preferred debug/instrumentation library (e.g. Logger).
“One way I expect this might work is that the Code Editor would be given a configurable list of oracle object identifiers (e.g. “logger”, “logger_logs”); any PL/SQL declarations or lines of code containing references to these objects would be greyed out, or be able to be rolled up (with something like the +/- gutter buttons).”
Mockup #1 (alternative syntax highlighting option):

Mockup #2 (identifier slugs in header bar to show/hide, with icons in the gutter showing where lines have been hidden):
“Gold-plated” Option: add an option to the SQL Editor’s right-click context menu – on any identifier, select “Hide all lines with reference to this” and it adds the identifier to the list of things that are hidden!
If you like the idea (or at least agree with the motive behind it) please vote for it.
 The cost of providing Virtual Machines to all your developers can be quite high, especially in terms of initially setting it all up (e.g. a typical developer may require two VMs running concurrently, one for the database server, one for the app server; their desktops will require enough grunt to run these while they also run their dev tools, or they’ll need at least two computers on their desks; also, you’ll need a means of scaling down the data volumes if your database is too big); but you will gain a whole lot more productivity, sanity, happiness and love from your developers.
The cost of providing Virtual Machines to all your developers can be quite high, especially in terms of initially setting it all up (e.g. a typical developer may require two VMs running concurrently, one for the database server, one for the app server; their desktops will require enough grunt to run these while they also run their dev tools, or they’ll need at least two computers on their desks; also, you’ll need a means of scaling down the data volumes if your database is too big); but you will gain a whole lot more productivity, sanity, happiness and love from your developers.
10. Fail safe.
If everything goes terribly wrong, simply restore to snapshot (duh, obviously).
9. Handle shifting conditions outside your project.
As often as I can (e.g. after a few weeks if a lot of development has gone on), I re-run the scripts on a VM based on a fresh copy of Prod – any changes that anyone else has made without my knowing it, which affect my scripts adversely, get picked up early.
8. Upgrade scripts never raise an error (unless something unexpected occurs).
It is normal for a typical upgrade script to raise many errors (e.g. “object not found” when running a standard “DROP x, CREATE x” script). However, I wrap any command like this with a custom exception handler that swallows the errors that I know are expected or benign. That way, when I hand over my upgrade scripts to the DBA, I can say, “if you get any error messages, something’s gone wrong”, which is a bit better than handing over a list of error messages they can safely ignore. Even better, I can add WHEN SQLERROR EXIT to the top of my upgrade script, so it exits out straightaway if the upgrade fails at any point.
7. Sanity Restore.
You’ve been beating your head against the wall for five minutes, and no-one’s around to add a second eye to your problem; you’re starting to wonder if the bug was something you introduced, or has always been there; and you can’t just log into production to test it. VM to the rescue – undo all your changes by restoring to an earlier snapshot, then see if your problem was a pre-existing issue.
6. Other Developers.
Let’s face it. Things would go a lot smoother if not for all the efforts of other developers to impede your progress by making random changes in the dev environment. Am I right? Well, with your private VM this is no longer a problem. Of course, with a private VM, if anything goes wrong, it’s incontrovertibly your fault now…
5. “Did you turn it off and on again?”
Finally, no need to nag the DBA to bounce the database server, or flush the shared pool, or in fact anything that requires more access than you’d usually get as a lowly developer. Need to increase that tablespace? Drop a couple hundred tables? No problem.
4. Real size estimates.
This works really well when you’re working with relatively small databases (i.e. where an entire copy of prod can be practically run in a VM). Run your upgrade script, which fails halfway through with a tablespace full error. Restore to snapshot, resize the appropriate datafile, re-run the upgrade. Rinse, repeat until no more “out of space” errors; now you know with a high degree of confidence how much extra space your upgrade requires, and for which datafiles.
3. Reduced down-time.
Dev server down? Being upgraded? Been appropriated by another department? No worries – your dev team can continue working, because they’ve got their VMs.
2. Did I say “Fail Safe” already?
I can’t emphasize this one enough. Also, the other side of “Other Developers” is that you are an Other Developer; and the mistakes you will, inevitably, make will never see the light of day (and draw everyone’s ire) if they’re made in your private VM.
1. Smug.
My last deployment to Test of a major release of an application executed perfectly, 100%, correct, first time. I couldn’t believe my eyes – I was so accustomed to my scripts failing for random reasons (usually from causes outside my control, natch). It was all thanks to my use of VMs to develop my fault-tolerant upgrade scripts. I was smug.

A colleague asked me a trick* question today which I failed 🙂
* whether it was a “trick” question is probably in the eye of the beholder, though…
“What are the differences, if any, between the following two approaches to inserting multiple rows (assume v1 and v2 have different values):
INSERT INTO mytable (a)
SELECT :v1 FROM DUAL;
INSERT INTO mytable (a)
SELECT :v2 FROM DUAL;
OR:
INSERT INTO mytable (a)
SELECT :v1 FROM DUAL
UNION
SELECT :v2 FROM DUAL;
I quickly answered:
- The first approach requires one extra parse;
- The second approach requires a Sort Distinct (albeit of only two rows)
- A UNION ALL would be better, which would not require a Sort, nor would require the extra parse.
My colleague responded, there’s one very important thing I missed: Triggers! The first approach would execute the BEFORE STATEMENT and AFTER STATEMENT triggers once for each row. The second approach would only execute these triggers once.
What’s sad is that the application we’re working on has row-level logic in the BEFORE/AFTER statement triggers. If we try to optimise the code to insert more than one row in one INSERT statement, the application only runs the row-level logic for the first row inserted. Bad code! Very very bad!
Comment out all “DROP TABLE” commands in my scripts.
(I accidentally hit F5 when the focus was in the wrong window – which happened to contain a “DROP TABLE / CREATE TABLE” script – my Toad session goes and happily drops the table that I’d been gradually accumulating statistics into for the past 3 days – and no, there’s no flashback table in 9i)
At least I kept all my scripts – rerunning them all now…
I’m starting to come around to Oracle SQL Developer. At home I only use free software so that’s obviously a big plus, but at work I’m still using PL/SQL Developer (Allround Automations) and SQL*Plus.
These are the features I like best about these products:
SQL Developer:
- Connection management
- Connection browser
- Multiple simultaneous connections
- Password persistance
- Quick connection switching within SQL worksheet
- Object viewer
- Easy Query management
- Nicer plan viewer
PL/SQL Developer:
- Faster startup, smaller memory footprint
- Fully configurable object browser
- Re-order categories
- Create/modify/delete categories
- Colour coding
- Data browser
- Edit data directly in grid
- View data, including LOBs, e.g. RTF, XML, HTML, hex, etc.
- Window management
- Summary tab lists all windows, indicating which are unsaved or are currently running SQL
- Query management
- Runs DDL and DML in a second session, easy to cancel queries
- Smart SQL and PL/SQL Editing
- Context-sensitive menus
- Smarter, context-sensitive code suggestions
- Configurable SQL beautifier
- Session browser, configurable
I’d like to see Oracle work on some of these features before I switch over at work. I’d also like to see SQL Developer able to export LOBs when exporting tables to XML.
I upgraded Oracle SQL Developer from 1.0.14.67 to 1.0.15.27, just for the heck of it. Unfortunately, all my saved connections had disappeared! After a text search I found the connections are stored in a file called IDEConnections.xml under the folder sqldeveloper\jdev\system\oracle.onlinedb.11.0.0.37.25. I copied this across to a new folder that had been created (oracle.onlinedb.11.0.0.37.36) and bingo they’re back again.
Bonus – now I know what file to back up if I want to restore my connections later on.