Got a lot of APEX applications, and/or a schema with lots of objects?
Not sure exactly what database objects are used by which application?
Not sure dropping a particular schema object might break something in your application?
Not sure if all the SQL and PL/SQL in every page of your application still runs without error?
If your answer to any of the above is “Yes”, you may be interested in a new API that has been added in APEX 24.1.
You can use this API to scan your application for any references to any schema objects, whether it refers to objects in a region, SQL queries, PL/SQL processes, and even plugins. Run this in your workspace, giving it the ID of an application you want to scan:
begin
apex_app_object_dependency.scan(p_application_id => :app_id);
end;
This scans through the whole application by generating a small temporary procedure that tests each schema object name, SQL, or PL/SQL. As it goes, it checks that the code compiles without error, and if it compiles, it saves a list of dependencies detected by the database including tables, views, stored functions and procedures, packages, and synonyms. It drops the temporary procedure at the end.
Depending on how big your application is, the scan may take some time to complete (e.g. 30 to 60 seconds) due to the time required to compile and analyze each temporary procedure. If you find it gets stopped prematurely due to a timeout error, you can run it in the background (for example, I like to use an “Execution Chain” process in an APEX application with “Run in Background” enabled).
Note that none of your application code is actually executed, so there should be no side effects of running the scan. However, if your database has any DDL triggers, they may fire as the temporary procedure is created and dropped.
Viewing the Scan Results
Once the scan is complete, you can query the results at your leisure by querying these views:
APEX_USED_DB_OBJECTS
APEX_USED_DB_OBJECT_COMP_PROPS
APEX_USED_DB_OBJ_DEPENDENCIES
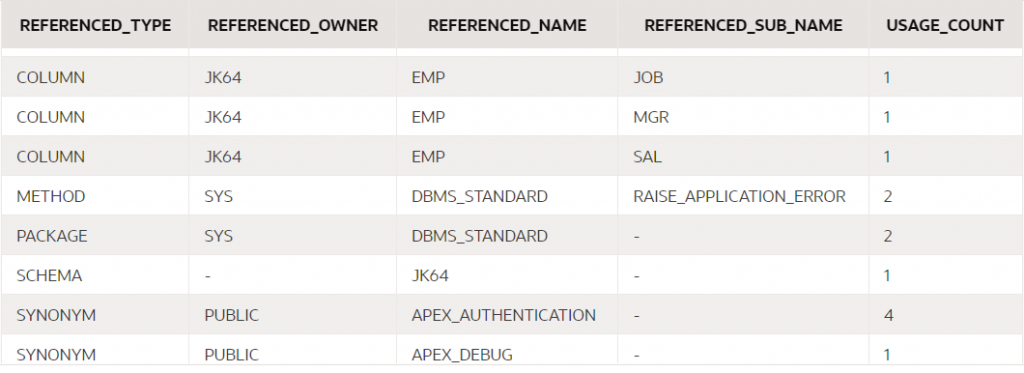
APEX_USED_DB_OBJECTS
This lists each schema object that is used at least once in your application.
select
referenced_type, referenced_owner,
referenced_name, referenced_sub_name,
usage_count
from apex_used_db_objects
where application_id = :app_id;
Note that “USAGE_COUNT” is the number of distinct component properties that refer to the schema object; if a single component (e.g. a Process) refers to an object multiple times, it will only count as one usage.
If your database package is compiled with PL/Scope enabled, the dependency analysis will also report fine-grained dependencies on the functions, procedures, and other components within the database package.
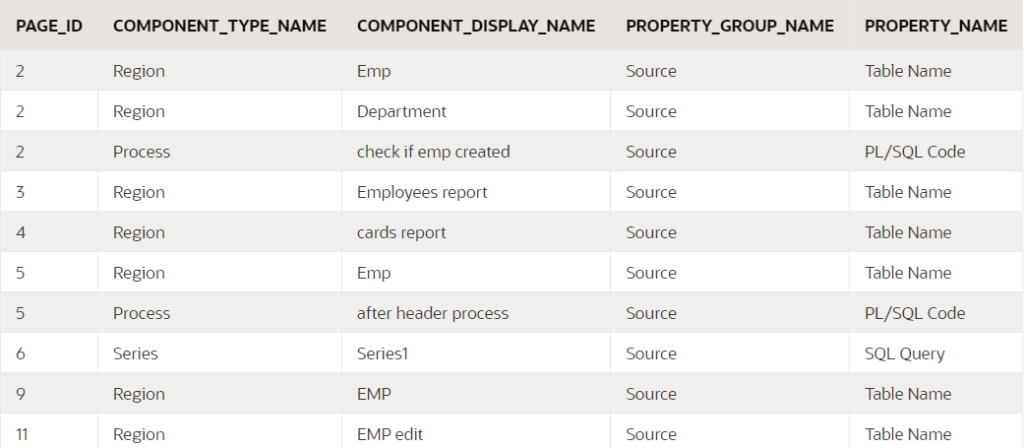
APEX_USED_DB_OBJECT_COMP_PROPS
This lists each component property in your application that references at least one schema object.
select
page_id,
component_type_name, component_display_name,
property_group_name, property_name
from apex_used_db_object_comp_props
where application_id = :app_id;
You can also include the column CODE_FRAGMENT to show the object name, SQL or PL/SQL that was analyzed.
If a component property cannot be analyzed due to a compile error (e.g. if an expected database object is missing) the same view will tell you what the compile error was, which may help you to determine what’s gone wrong.
select
page_id,
component_type_name, component_display_name,
property_group_name, property_name,
code_fragment, error_message
from apex_used_db_object_comp_props
where application_id = :app_id
and error_message is not null;
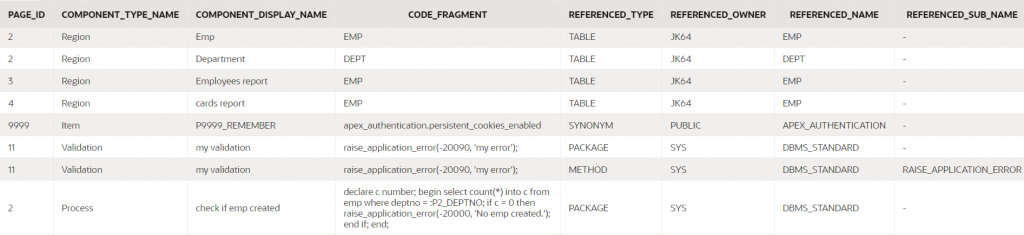
APEX_USED_DB_OBJ_DEPENDENCIES
This is the complete report showing for each component property, all the database objects it refers to.
select
page_id,
component_type_name, component_display_name,
property_group_name, property_name,
code_fragment,
referenced_type, referenced_owner,
referenced_name, referenced_sub_name
from apex_used_db_obj_dependencies
where application_id = :app_id;
(some columns were removed from this screenshot)
Using the API
The results of a scan will be retained until the application is re-scanned. You can scan any number of applications in your workspace and analyze the results all together if you need. If an application is modified, you can re-scan it to refresh the report.
You may find it useful, so I encourage you to give it a try. If you do, please note a few caveats:
The documentation for this API is not yet available, but is being worked on.
When APEX is upgraded to a new version, all report results are wiped. You can then re-scan your applications to get up-to-date results.
The reports do not include recursive dependencies – e.g. if your application refers to a view, the report will not list the underlying tables of the view.
If the application includes any plugins, the dependencies report will include references to some internal plugin-related APIs even if your code doesn’t directly reference them.
If your application executes any dynamic SQL or PL/SQL (e.g. using “execute immediate”), any dependencies arising from the dynamic code will not be reported.
There are some component properties that are not included in the scan, such as the column names in a report (however, the data source for the region is scanned).
In spite of the caveats, I’m sure there are quite a few ways this new API will prove useful. We expect it will be further improved in future releases, including being integrated into the APEX Application Builder.
Quite often I will need to export some data from one system, such as system setup metadata, preferences, etc. that need to be included in a repository and imported when the application is installed elsewhere.
I might export the data in JSON or CSV or some other text format as a CLOB (character large object) variable. I then need to wrap this in suitable commands so that it will execute as a SQL script when installed in the target system. To do this I use a simple script that takes advantage of the APEX_STRING API to split the CLOB into chunks and generate a SQL script that will re-assemble those chunks back into a CLOB on the target database, then call a procedure that will process the data (e.g. it might parse the JSON and insert metadata into the target tables).
This will work even if the incoming CLOB has lines that exceed 32K in length, e.g. a JSON document that includes embedded image data encoded in base 64, or documents with multibyte characters.
This is clob_to_sql_script:
function clob_to_sql_script (
p_clob in varchar2,
p_procedure_name in varchar2,
p_chunk_size in integer := 8191
) return clob is
-- Takes a CLOB, returns a SQL script that will call the given procedure
-- with that clob as its parameter.
l_strings apex_t_varchar2;
l_chunk varchar2(32767);
l_offset integer;
begin
apex_string.push(
l_strings,
q'[
declare
l_strings apex_t_varchar2;
procedure p (p_string in varchar2) is
begin
apex_string.push(l_strings, p_string);
end p;
begin
]');
while apex_string.next_chunk (
p_str => p_clob,
p_chunk => l_chunk,
p_offset => l_offset,
p_amount => p_chunk_size )
loop
apex_string.push(
l_strings,
q'[p(q'~]'
|| l_chunk
|| q'[~');]');
end loop;
apex_string.push(
l_strings,
replace(q'[
#PROC#(apex_string.join_clob(l_strings));
end;
]',
'#PROC#', p_procedure_name)
|| '/');
return apex_string.join_clob(l_strings);
end clob_to_sql_script;
Note that the default chunk size is 8,191 characters which is the safe limit for multi-byte characters. You can choose a smaller chunk size if you want, although if the incoming CLOB is very large, the smaller the chunk size the bigger the expanded SQL script will be.
A simple test case will demonstrate what it will do:
declare
l_input clob;
l_output clob;
begin
l_input := q'[
{
"data": "Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum."
}
]';
l_output := clob_to_sql_script(
p_clob => l_input,
p_procedure_name => 'mypackage.import',
p_chunk_size => 60 );
dbms_output.put_line( l_output );
end;
/
The above script would output this:
declare
l_strings apex_t_varchar2;
procedure p (p_string in varchar2) is
begin
apex_string.push(l_strings, p_string);
end p;
begin
p(q'~
{
"data": "Lorem ipsum dolor sit amet, consectetur adip~');
p(q'~iscing elit, sed do eiusmod tempor incididunt ut labore et d~');
p(q'~olore magna aliqua. Ut enim ad minim veniam, quis nostrud ex~');
p(q'~ercitation ullamco laboris nisi ut aliquip ex ea commodo con~');
p(q'~sequat. Duis aute irure dolor in reprehenderit in voluptate ~');
p(q'~velit esse cillum dolore eu fugiat nulla pariatur. Excepteur~');
p(q'~ sint occaecat cupidatat non proident, sunt in culpa qui off~');
p(q'~icia deserunt mollit anim id est laborum."
}
~');
mypackage.import(apex_string.join_clob(l_strings));
end;
/
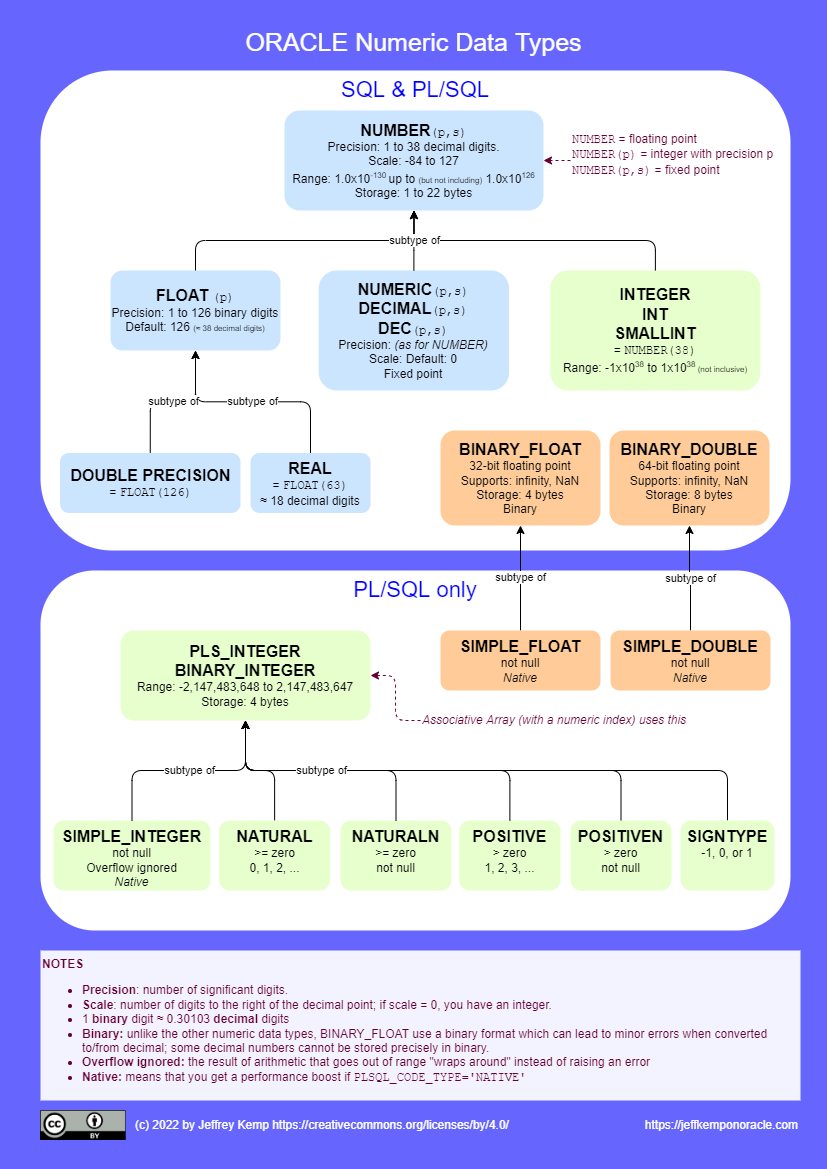
You are probably familiar with some of the data types supported by the Oracle Database for storing numeric values, but you might not be aware of the full range of types that it provides.
Some types (such as NUMBER, INTEGER) are provided for general use in SQL and PL/SQL, whereas others are only supported in PL/SQL (such as BINARY_INTEGER).
There are others (such as DECIMAL, REAL) that are provided to adhere to the SQL standard and for greater interoperability with other databases that expect these types.
Most of the numeric data types are designed for storing decimal numbers without loss of precision; whereas the binary data types (e.g. BINARY_FLOAT, BINARY_DOUBLE) are provided to conform to the IEEE754 standard for binary floating-point arithmetic. These binary types cannot store all decimal numbers exactly, but they do support some special values like “infinity” and “NaN”.
In PL/SQL you can define your own subtypes that further constrain the values that may be assigned to them, e.g. by specifying the minimum and maximum range of values, and/or by specifying that variables must be Not Null.
What do I prefer?
In my data models, I will usually use NUMBER to store numeric values, e.g. for quantities and measurements; for counts and IDs (e.g. for surrogate keys) I would use INTEGER (with the exception of IDs generated using sys_guid, these must use NUMBER).
In PL/SQL, if I need an index for an array, I will use BINARY_INTEGER (although if I’m maintaining a codebase that already uses its synonym PLS_INTEGER, I would use that for consistency). In other cases I will use INTEGER or NUMBER depending on whether I need to store integers or non-integers.
I don’t remember any occasion where I’ve needed to use FLOAT, or the binary types; and of the subtypes of BINARY_INTEGER, I’ve only used SIGNTYPE maybe once or twice. Of course, there’s nothing wrong with these types, it’s just that I haven’t encountered the need for them (yet).
What about Performance?
There are some differences in performance between these data types, but most of the time this difference will not be significant compared to other work your code is doing – see, for example, Connor on Choosing the Best Data Type. Choosing a data type that doesn’t use more storage than is required for your purpose can make a difference when the volume of data is large and when large sets of record are being processed and transmitted.
Reference Chart: Numeric Data Types
This diagram shows all the numeric data types supplied by Oracle SQL and PL/SQL, and how they relate to each other:
From smallest to largest – the maximum finite integer that can be stored by these data types is listed here. It’s interesting to see that BINARY_FLOAT can store bigger integers than INTEGER, but NUMBER can beat both of them:
BINARY_INTEGER
2.147483647 x 109
INTEGER
9.9999999999999999999999999999999999999 x 1037
BINARY_FLOAT
3.40282347 x 1038
NUMBER
9.999999999999999999999999999999999999999 x 10125
BINARY_DOUBLE
1.7976931348623157 x 10308
To put that into perspective:
If you need to store integers up to about 1 Billion (109), you can use a BINARY_INTEGER.
If you need to store Googolplex (10googol) or other ridiculously large numbers (that are nevertheless infinitely smaller than infinity), you’re “gonna need a bigger boat” – such as some version of BigDecimal with a scale represented by a BigInteger – which unfortunately has no native support in SQL or PL/SQL. Mind you, there are numbers so large that even such an implementation of BigDecimal cannot even represent the number of digits in them…
Storing SMALL Numbers
The smallest non-zero numeric value (excluding subnormal numbers) that can be stored by these data types is listed here.
BINARY_FLOAT
1.17549435 x 10-38
NUMBER
1.0 x 10-130
BINARY_DOUBLE
2.2250738585072014 x 10-308
These are VERY small quantities. For example:
The size of a Quark, the smallest known particle, is less than 10-19 metres and can easily be represented by any of these types.
You can store numbers as small as the Planck Length (1.616 × 10-35 metres) in a BINARY_FLOAT.
But to store a number like the Planck Time (5.4 × 10-44 seconds), you need a NUMBER – unless you change the units to nanoseconds, in which case it can also be stored in a BINARY_FLOAT.
I’m not aware of any specifically named numbers so small that they require a BINARY_DOUBLE; however, there are certainly use cases (e.g. scientific measurements) that need the kind of precision that this type provides.
I have been working with some code that uses JSON, sometimes fairly large documents of the stuff, and it’s often necessary to send this to the debug log (e.g. DBMS_OUTPUT) for debugging; however, the builtin functions that convert a JSON object to a string (or clob) return the JSON document in one big long line, like this:
To show this formatted, I added the following function using JSON_SERIALIZE with the “PRETTY” option, to my utility package:
function format_json (p_clob in clob) return clob is
l_blob blob;
l_clob clob;
function clob_to_blob(p_clob clob) return blob is
l_blob blob;
o1 integer := 1;
o2 integer := 1;
c integer := 0;
w integer := 0;
begin
sys.dbms_lob.createtemporary(l_blob, true);
sys.dbms_lob.converttoblob(l_blob, p_clob, length(p_clob), o1, o2, 0, c, w);
return l_blob;
end clob_to_blob;
begin
l_blob := clob_to_blob(p_clob);
select JSON_SERIALIZE(l_blob returning clob PRETTY) into l_clob from dual;
return l_clob;
end format_json;
Note that my function takes a CLOB, not a JSON object, because sometimes I receive the data already as a CLOB and I don’t want to require conversion to JSON before passing it to my formatting function.
In building a code generator I found the need to write a number of helper methods for doing basic modifications of arrays that are indexed by integer – such as appending one array onto another, inserting, and shifting. These arrays represent an ordered sequence of strings (e.g. lines of source code).
I think these would be a useful addition to the language if they were made native – e.g. (new commands in UPPERCASE):
declare
type str_array_type is table of varchar2(32767)
index by binary_integer;
l_lines str_array_type;
l_new str_array_type;
l_idx binary_integer;
begin
.. (some code to fill the arrays here) ..
-- get a subset of lines
l_new := l_lines.SLICE(50, 59);
-- extend l_lines with l_new at the end:
l_lines.APPEND(l_new);
-- shift l_lines forwards and insert l_new
-- at the beginning:
l_lines.PREPEND(l_new);
-- insert l_new into l_lines at the given index;
-- shift any existing lines at that location
-- forward:
l_lines.INSERT(l_new, at_idx => 21);
-- remove the given range of indices from
-- l_lines, replace with whatever is in l_new:
l_lines.UPDATE(l_new,
from_idx => 120,
to_idx => 149);
-- apply the given substitution on each line
l_lines.REPLACE_ALL(
old_val => 'foo',
new_val => 'bar');
-- shift the given range of lines by the given
-- offset (raise exception if existing data
-- would get overwritten):
l_lines.SHIFT(
from_idx => 20,
to_idx => 29,
offset => 1000);
-- shift and renumber all indices in the array
-- with the given starting index and increment:
l_lines.RENUMBER(start_idx => 10, increment => 10);
-- make the array contiguous (i.e. remove gaps):
l_lines.RENUMBER;
-- loop over every line in the array that contains
-- the given string:
l_idx := l_lines.FIND_NEXT(contains => 'hello');
loop
exit when l_idx is null;
.. do something with l_lines(l_idx) ..
l_idx := l_lines.FIND_NEXT(contains => 'hello',
from_idx => l_idx);
end loop;
end;
I’ve illustrated these with a little sample package that may be viewed here:
One of the nice things about PL/SQL is that it implements short circuit evaluation, a performance enhancement which takes advantage of the fact that an expression using logical AND or OR does not necessarily to evaluate both operands to determine the overall result.
For an expression using AND, if the first operand is not TRUE, the overall expression cannot be TRUE; for one using OR, if the first operand is TRUE, the overall expression must be TRUE. In the case of AND, what if the first operand is Unknown? It seems to depend on how the expression is used.
In my examples below, I have an expression that looks up an array. When an array is accessed with a key that is null, it will raise an exception. If short circuit evaluation is applied, the array is never accessed so the exception is not raised.
In the first example below, the PL/SQL engine never evaluates the second expression since the first expression ('abc' = p_param) is not TRUE:
declare
p_param varchar2(10);
l_result boolean := false;
l_arr apex_t_varchar2;
begin
if 'abc' = p_param and l_arr(p_param) = 'bla' then
l_result := true;
end if;
end;
This does not apply if the expression is being assigned to a variable. In the second example below, the exception ORA-06502: PL/SQL: numeric or value error: NULL index table key value is raised:
declare
p_param varchar2(10);
l_result boolean;
l_arr apex_t_varchar2;
begin
l_result := 'abc' = p_param and l_arr(p_param) = 'bla';
end;
If the first expression were to result in FALSE, it runs without error. If the first expression is Unknown (NULL), the second operand must be evaluated to determine whether to assign FALSE or NULL to the result.
A workaround is to use an IF statement to make the evaluation order explicit:
declare
p_param varchar2(10);
l_result boolean := false;
l_arr apex_t_varchar2;
begin
if 'abc' = p_param then
l_result := l_arr(p_param) = 'bla';
end if;
end;
Thanks to Connor for clearing up my understanding for this one.
8/10/2020 updated with better example code – instead of comparing to a literal null (which is never right), we compare to a variable which may or may not be null at runtime.
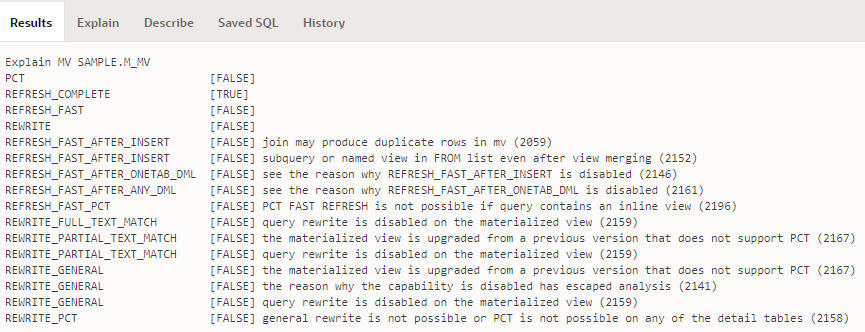
Need to run DBMS_MVIEW.explain_mview in APEX SQL Workshop, but don’t have the MV_CAPABILITIES_TABLE? You’ll get this error:
ORA-30377: table ORDS_PUBLIC_USER.MV_CAPABILITIES_TABLE not found
You don’t need to create this table. You could create this table by running admin/utlxmv.sql (if you have it). Instead, you can get the output in an array and do whatever you want with its contents, e.g.:
declare
a sys.ExplainMVArrayType;
begin
dbms_mview.explain_mview('MY_MV',a);
dbms_output.put_line('Explain MV '
|| a(1).mvowner || '.' || a(1).mvname);
for i in 1..a.count loop
dbms_output.put_line(
rpad(a(i).capability_name, 30)
|| ' [' || case a(i).possible
when 'T' then 'TRUE'
when 'F' then 'FALSE'
else a(i).possible
end || ']'
|| case when a(i).related_num != 0 then
' ' || a(i).related_text
|| ' (' || a(i).related_num || ')'
end
|| case when a(i).msgno != 0 then
' ' || a(i).msgtxt
|| ' (' || a(i).msgno || ')'
end
);
end loop;
end;
The result will be something like this:
Now, the challenge is merely how to resolve some of those “FALSEs” …
If you need to send almost any message to almost any phone from your Oracle database, and you want to use straight PL/SQL, you may want to consider using my Clicksend API.
SMS (Short Message Service)
MMS (Multimedia Message Service)
Text to Voice
I have released the first beta version of my Oracle PL/SQL API for Clicksend. Read the installation instructions, API reference and download the release from here:
Sending an SMS is as simple as adding this anywhere in your code:
begin
clicksend_pkg.send_sms
(p_sender => 'TheDatabase'
,p_mobile => '+61411111111'
,p_message => 'G''day, this is your database!'
);
clicksend_pkg.push_queue;
commit;
end;
All you need to do is signup for a Clicksend account. You’ll only be charged for messages actually sent, but they do require you to pay in advance – e.g. $20 gets you about 300 messages (Australian numbers). You can get test settings so that you can try it out for free.
I’ve been using Clicksend for years now, and have been satisfied with their service and the speed and reliability of getting messages to people’s mobiles. When I encountered any issues, a chat with their support quickly resolved them, and they were quick to offer free credits when things weren’t working out as expected.
If you want to send a photo to someone’s phone via MMS (although I’m not sure what the use-case for this might be), you need to first upload the image somewhere online, because the API only accepts a URL. In my case, I would use the Amazon S3 API from the Alexandria PL/SQL Library, then pass the generated URL to the clicksend API. There is a file upload feature that ClickSend provides, I plan to add an API call to take advantage of this which will make this seamless – and provide some file conversion capabilities as well.
begin
clicksend_pkg.send_mms
(p_sender => 'TheDatabase'
,p_mobile => '+61411111111'
,p_subject => 'G''Day!'
,p_message => 'This is an MMS from your database!'
,p_media_file_url =>
'http://s3-ap-southeast-2.amazonaws.com/jk64/jk64logo.jpg'
);
clicksend_pkg.push_queue;
commit;
end;
You can send a voice message to someone (e.g. if they don’t have a mobile phone) using the Text to Voice API.
begin
clicksend_pkg.send_voice
(p_phone_no => '+61411111111'
,p_message => 'Hello. This message was sent from your database. '
|| 'Have a nice day.'
,p_voice_lang => 'en-gb' -- British English
,p_voice_gender => 'male'
,p_schedule_dt => sysdate + interval '2' minute
);
clicksend_pkg.push_queue;
commit;
end;
You have to tell the API what language the message is in. For a number of languages, you can specify the accent/dialect (e.g. American English, British English, or Aussie) and gender (male or female). You can see the full list here.
All calls to the send_sms, send_mms and send_voice procedures use Oracle AQ to make the messages transactional. It’s up to you to either COMMIT or ROLLBACK, which determines whether the message is actually sent or not. All messages go into a single queue.
You can have a message be scheduled at a particular point in time by setting the p_schedule_dt parameter.
The default installation creates a job that runs every 5 minutes to push the queue. You can also call push_queue directly in your code after calling a send_xxx procedure. This creates a job to push the queue as well, so it won’t interfere with your transaction.
All messages get logged in a table, clicksend_msg_log. The log includes a column clicksend_cost which allows you to monitor your costs. To check your account balance, call get_credit_balance.
Please try it out if you can and let me know of any issues or suggestions for improvement.
Sending emails from the Oracle database can be both simply deceptively braindead easy, and confoundingly perplexingly awful at the same time. Easy, because all you have to do is call one of the supplied mail packages to send an email:
If you want more control over your emails you can use UTL_SMTP instead; this is what I’ve been using for the past few years because I like feeling in control (doesn’t everyone?). This is the package that APEX_MAIL is built on top of.
If you just don’t trust these high-level abstractions you can use UTL_TCP and interact directly with the mail server. I don’t know, maybe your mail server does some weird stuff that isn’t supported by the standard packages.
If you want to send attachments, you can build this yourself in UTL_SMTP or UTL_TCP, but it’s easier with APEX_MAIL which can send BLOBs. UTL_MAIL can send attachments but only up to 32K in size (half that for binary files which become base64 encoded).
Let’s make up a checklist of features supported out of the box (i.e. without requiring you to write non-trivial code) and see how they stack up:
APEX_MAIL
UTL_MAIL
UTL_SMTP
UTL_TCP
Attachments
Yes
Yes (<32K)
No*
No*
Asynchronous
Yes
No
No
No
Rate limited
Yes
No
No
No
Anti-Spam
No*
No*
No*
No*
SSL/TLS
Yes
No
No*
No*
Authentication
Yes
No
No*
No*
Features marked “No*”: these are not natively supported by the API, but generic API routines for sending arbitrary data (including RAW) can be used to build these features, if you’re really keen or you can google the code to copy-and-paste.
(Note: of course, you can add the Asynchronous and Rate limiting features to any of the UTL_* packages by writing your own code.)
Asynchronous
Calls to the API to send an email do not attempt to connect to the mail server in the same session, but record the email to be sent soon after in a separate session.
This provides two benefits:
It allows emails to be transactional – if the calling transaction is rolled back, the email will not be sent; and
It ensures the client process doesn’t have to wait until the mail server responds, which might be slow in times of peak load.
Anti-Spam
Sending an email within an organisation is easy; internal mail servers don’t usually filter out internal emails as spam. Sending an email across the internet at large is fraught with difficulties, which can rear their ugly heads months or years after going live. One day your server tries to send 100 emails to the same recipient in error, and all of a sudden your IP is blocked as a spammer and NO emails get sent, with no warning.
For the last two years I’ve been battling this problem, because my site allows my clients to broadcast messages to their customers and partners via email and SMS. The SMS side worked fine, but emails frequently went AWOL and occasionally the whole site would get spam blocked. Most emails to hotmail went into a black hole and I was always having to apologise to anyone complaining about not getting their emails – “You’re not using a hotmail address by any chance? ah, that’s the problem then – sorry about that. Do you have any other email address we can use?”
I added some rate-limiting code to ensure that my server trickled the emails out. My server was sending about 2,000 to 3,000 per month, but sometimes these were sent in short spikes rather than spread out over the month. My rate-limiting meant a broadcast to 200 people could take several hours to complete, which didn’t seem to bother anyone; and this stopped the “too many emails sent within the same hour” errors from the mail server (I was using my ISP’s mail server).
I managed to improve the situation a little by implementing SPF (Sender Policy Framework). But still, lots of emails went missing, or at least directly into people’s spam folders.
I looked into DKIM as well, but after a few hours reading I threw that into the “too hard basket”. I decided that I’d much prefer to outsource all this worry and frustration to someone with more expertise and experience.
Searching for an Email Gateway
I’ve been hosting my site on Amazon EC2 for a long time now with great results and low cost, and I’ve also been using Amazon S3 for hosting large files and user-uploaded content. Amazon also provides an Email Gateway solution called SES which seemed like a logical next step. This service gives 62,000 messages per month for free (when sent from an EC2 instance) and you just get charged small amounts for the data transfer (something like 12c per GB).
I started trying to build a PL/SQL API to Amazon SES but got stuck trying to authenticate using Amazon’s complicated scheme. Just to make life interesting they use a different encryption algorithm for SES than they do for S3 (for which I already had code from the Alexandria PL/SQL library). It was difficult because their examples all assumed you’ve installed the Amazon SDK.
It always rejected anything I sent, and gave no clues as to what I might be doing wrong. In the end I decided that what I was doing wrong was trying to work this low-level stuff out myself instead of reusing a solution that someone else has already worked out. A good developer is a lazy developer, so they say. So I decided to see what other email gateways are out there.
I looked at a few, but their costs were prohibitive for my teeny tiny business as they assumed I am a big marketing company sending 100,000s of emails per month and would be happy to pay $100’s in monthly subscriptions. I wanted a low-cost, pay-per-use transactional email service that would take care of the DKIM mail signing for me.
Mailgun
In the end, I stumbled upon Mailgun, a service provided by Rackspace. Their service takes care of the DKIM signing for me, do automated rate limiting (with dynamic ramp up and ramp down), it includes 10,000 free emails per month, and extra emails are charged at very low amounts per email with no monthly subscription requirement.
Other benefits I noticed was that it allows my server to send emails by two methods: (1) RESTful API and (2) SMTP. The SMTP interface meant that I was very quickly able to use the service simply by pointing my existing APEX mail settings and my custom UTL_SMTP solution directly to the Mailgun SMTP endpoint, and it worked out of the box. Immediately virtually all our emails were getting sent, even to hotmail addresses. I was able to remove my rate limiting code. Other bonuses were that I now had much better visibility of failed emails – the Mailgun online interface provides access to a detailed log including bounces, spam blocks and other problems. So far I’ve been using it for a few weeks, and of 2,410 emails attempted, 98.55% were delivered, and 1.45% dropped. The emails that were dropped were mainly due to incorrect email addresses in my system, deliberately “bad” test emails I’ve tried, or problems on the target mail servers. One email was blocked by someone’s server which was running SpamAssassin. So overall I’ve been blown away by how well this is running.
Once I had my immediate problem solved, I decided to have a closer look at the RESTful API. This provides a few intriguing features not supported by the SMTP interface, such as sending an email to multiple recipients with substitution strings in the message, and each recipient only sees their own name in the “To” field. My previous solution for this involved sending many emails; the API means that I can send the request to Mailgun just once, and Mailgun will send out all the individual emails.
Another little bonus is that Mailgun’s API also includes a souped-up email address validator. This validator doesn’t just check email addresses according to basic email address formatting, it also checks the MX records on the target domain to determine whether it’s likely to accept emails. For some domains (such as gmail.com and yahoo.com) I noticed that it even does some level of checking of the user name portion of the email address. It’s still not absolutely perfect, but it’s better than other email validation routines I’ve seen.
Note: Mailgun supports maximum message size of 25MB.
Email Validation Plugin
Mailgun also provide a jQuery plugin for their email address validator which means you can validate user-entered email addresses on the client before they even hit your server. To take advantage of this in Oracle APEX I created the Mailgun Email Validator Dynamic Plugin that you can use and adapt if you want.
PL/SQL API
If you follow me on twitter you are probably already aware that I’ve started building a PL/SQL API to make the Mailgun RESTful API accessible to Oracle developers. You can try it out for yourself by downloading from here if you want. The WIKI on Github has detailed installation instructions (it’s a little involved) and an API reference.
The API supports the following Mailgun features:
Email validation – does the same thing as the jQuery-based plugin, but on the server
My implementation of the Send Email API so far supports the following features:
MAILGUN_PKG
Attachments
Yes
Asynchronous
Yes
Rate limited
Yes*
Anti-Spam
Yes*
SSL/TLS
Yes, required
Authentication
Yes
Features marked “Yes*”: these are provided by the Mailgun service by default, they are not specific to this PL/SQL API.
I’m planning to add more features to the API as-and-when I have a use for them, or if someone asks me very nicely to build them. I’ll be pleased if you fork the project from Github and I welcome your pull requests to merge improvements in. I recommend reading through the Mailgun API Documentation for feature ideas.
If you use either of these in your project, please let me know as I’d love to hear about your experience with it.
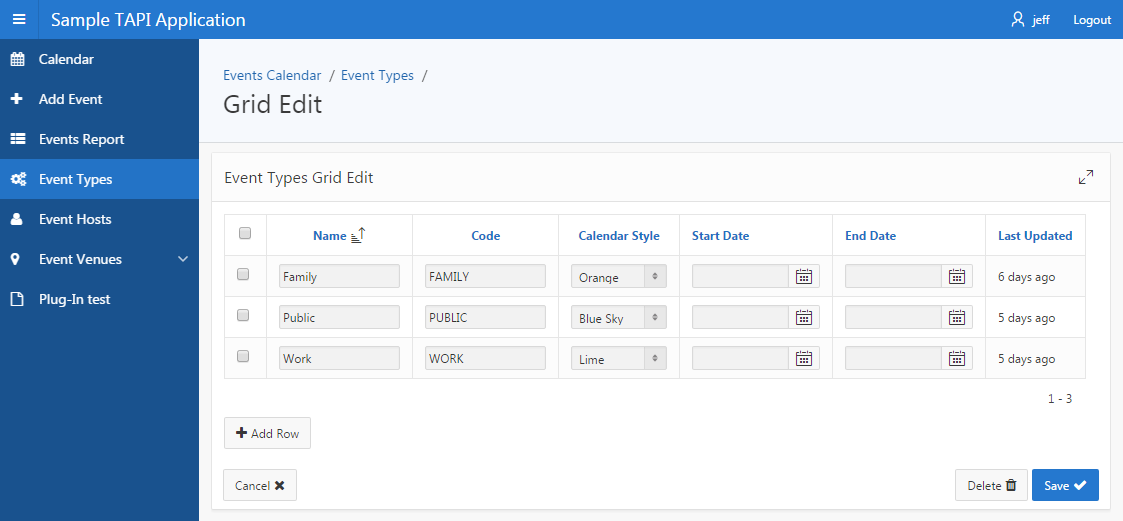
Ever since I started exploring the idea of using a TAPI approach with APEX, something I was never quite satisfied with was Tabular Forms.
They can be a bit finicky to work with, and if you’re not careful you can break them to the point where it’s easier to recreate them from scratch rather than try to fix them (although if you understand the underlying mechanics you can fix them [there was an article about this I read recently but I can’t find it now]).
I wanted to use the stock-standard APEX tabular form, rather than something like Martin D’Souza’s approach – although I have used that a number of times with good results.
In the last week or so while making numerous improvements to my TAPI generator, and creating the new APEX API generator, I tackled again the issue of tabular forms. I had a form that was still using the built-in APEX ApplyMRU and ApplyMRD processes (which, of course, bypass my TAPI). I found that if I deleted both of these processes, and replaced them with a single process that loops over the APEX_APPLICATION.g_f0x arrays, I lose a number of Tabular Form features such as detecting which records were changed.
Instead, what ended up working (while retaining all the benefits of a standard APEX tabular form) was to create a row-level process instead. Here’s some example code that I put in this APEX process that interfaces with my APEX API:
The process has Execution Scope set to For Created and Modified Rows. It first calls my TAPI.rv function to convert the individual columns from the row into an rvtype record, which it then passes to the APEX API apply_mr procedure. The downside to this approach is that each record is processed separately – no bulk updates; however, tabular forms are rarely used to insert or update significant volumes of data anyway so I doubt this would be of practical concern. The advantage of using the rv function is that it means I don’t need to repeat all the column parameters for all my API procedures, making maintenance easier.
The other change that I had to make was ensure that any Hidden columns referred to in my Apply process must be set to Hidden Column (saves state) – in this case, the VERSION_ID column.
Here’s the generated APEX API apply_mr procedure:
PROCEDURE apply_mr (rv IN VENUES$TAPI.rvtype) IS
r VENUES$TAPI.rowtype;
BEGIN
log_start('apply_mr');
UTIL.check_authorization('Operator');
IF APEX_APPLICATION.g_request = 'MULTI_ROW_DELETE' THEN
IF v('APEX$ROW_SELECTOR') = 'X' THEN
VENUES$TAPI.del (rv => rv);
END IF;
ELSE
CASE v('APEX$ROW_STATUS')
WHEN 'C' THEN
r := VENUES$TAPI.ins (rv => rv);
WHEN 'U' THEN
r := VENUES$TAPI.upd (rv => rv);
ELSE
NULL;
END CASE;
END IF;
log_end;
EXCEPTION
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END apply_mr;
The code uses APEX$ROW_STATUS to determine whether to insert or update each record. If the Delete button was pressed, it checks APEX$ROW_SELECTOR to check that the record had been selected for delete – although it could skip that check since APEX seems to call the procedure for only the selected records anyway. The debug logs show APEX skipping the records that weren’t selected.
Now, before we run off gleefully inserting and updating records we should really think about validating them and reporting any errors to the user in a nice way. The TAPI ins and upd functions do run the validation routine, but they don’t set up UTIL with the mappings so that the APEX errors are registered as we need them to. So, we add a per-record validation in the APEX page that runs this:
As for the single-record page, this validation step is of type PL/SQL Function (returning Error Text). Its Execution Scope is the same as for the apply_mr process – For Created and Modified Rows.
Note that we need to set a static ID on the tabular form region (the generator assumes it is the table name in lowercase – e.g. venues – but this can be changed if desired).
The val_row procedure is as follows:
PROCEDURE val_row
(rv IN VENUES$TAPI.rvtype
,region_static_id IN VARCHAR2
) IS
dummy VARCHAR2(32767);
column_alias_map UTIL.str_map;
BEGIN
log_start('val_row');
UTIL.pre_val_row
(label_map => VENUES$TAPI.label_map
,region_static_id => region_static_id
,column_alias_map => column_alias_map);
dummy := VENUES$TAPI.val (rv => rv);
UTIL.post_val;
log_end;
EXCEPTION
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END val_row;
The pre_val_row procedure tells all the validation handlers how to register any error message with APEX_ERROR. In this case, column_alias_map is empty, which causes them to assume that each column name in the tabular form is named the same as the column name on the database. If this default mapping is not correct for a particular column, we can declare the mapping, e.g. column_alias_map('DB_COLUMN_NAME') := 'TABULAR_FORM_COLUMN_NAME';. This way, when the errors are registered with APEX_ERROR they will be shown correctly on the APEX page.
Things got a little complicated when I tried using this approach for a table that didn’t have any surrogate key, where my TAPI uses ROWID instead to uniquely identify a row for update. In this case, I had to change the generated query to include the ROWID, e.g.:
SELECT t.event_type
,t.name
,t.calendar_css
,t.start_date
,t.end_date
,t.last_updated_dt
,t.version_id
,t.ROWID AS p_rowid
FROM event_types t
I found if I didn’t give a different alias for ROWID, the tabular form would not be rendered at runtime as it conflicted with APEX trying to get its own version of ROWID from the query. Note that the P_ROWID must also be set to Hidden Column (saves state). I found it strange that APEX would worry about it because when I removed* the ApplyMRU and ApplyMRD processes, it stopped emitting the ROWID in the frowid_000n hidden items. Anyway, giving it the alias meant that it all worked fine in the end.
* CORRECTION (7/11/2016): Don’t remove the ApplyMRU process, instead mark it with a Condition of “Never” – otherwise APEX will be unable to map errors to the right rows in the tabular form.
The Add Rows button works; also, the Save button correctly calls my TAPI only for inserted and updated records, and shows error messages correctly. I can use APEX’s builtin Tabular Form feature, integrated neatly with my TAPI instead of manipulating the table directly. Mission accomplished.


 Sending emails from the Oracle database can be both simply deceptively braindead easy, and confoundingly perplexingly awful at the same time. Easy, because all you have to do is call one of the supplied mail packages to send an email:
Sending emails from the Oracle database can be both simply deceptively braindead easy, and confoundingly perplexingly awful at the same time. Easy, because all you have to do is call one of the supplied mail packages to send an email: