 The order in which your deployment scripts create views is important. This is a fact that I was reminded of when I had to fix a minor issue in the deployment of version #2 of my application recently.
The order in which your deployment scripts create views is important. This is a fact that I was reminded of when I had to fix a minor issue in the deployment of version #2 of my application recently.
Normally, you can just generate a create or replace force view script for all your views and just run it in each environment, then recompile your schema after they’re finished – and everything’s fine. However, if views depend on other views, you can run into a logical problem if you don’t create them in the order of dependency.
Software Release 1.0
create table t (id number, name varchar2(100));
create or replace force view tv_base as
select t.*, 'hello' as stat from t;
create or replace force view tv_alpha as
select t.* from tv_base t;
desc tv_alpha;
Name Null Type
---- ---- -------------
ID NUMBER
NAME VARCHAR2(100)
STAT CHAR(5)
Here we have our first version of the schema, with a table and two views based on it. Let’s say that the tv_base includes some derived expressions, and tv_alpha is intended to do some joins on other tables for more detailed reporting.
Software Release 1.1
alter table t add (phone varchar2(10));
create or replace force view tv_alpha as
select t.* from tv_base t;
create or replace force view tv_base as
select t.*, 'hello' as stat from t;
Now, in the second release of the software, we added a new column to the table, and duly recompiled the views. In the development environment the view recompilation may happen multiple times (because other changes are being made to the views as well) – and nothing’s wrong. Everything works as expected.
However, when we run the deployment scripts in the Test environment, the “run all views” script has been run just once; and due to the way it was generated, the views are created in alphabetical order – so tv_alpha was recreated first, followed by tv_base. Now, when we describe the view, we see that it’s missing the new column:
desc tv_alpha;
Name Null Type
---- ---- -------------
ID NUMBER
NAME VARCHAR2(100)
STAT CHAR(5)
Whoops. What’s happened, of course, is that when tv_alpha was recompiled, tv_base still hadn’t been recompiled and so it didn’t have the new column in it yet. Oracle internally defines views with SELECT * expanded to list all the columns. The view won’t gain the new column until we REPLACE the view with a new one using SELECT *. By that time, it’s too late for tv_alpha – it had already been compiled, successfully, so it doesn’t see the new column.
Lesson Learnt
What should we learn from this? Be wary of SELECT * in your views. Don’t get me wrong: they are very handy, especially during initial development of your application; but they can surprise you if not handled carefully and I would suggest it’s good practice to expand those SELECT *‘s into a discrete list of columns.
Some people would go so far as to completely outlaw SELECT *, and even views-on-views, for reasons such as the above. I’m not so dogmatic, because in my view there are some good reasons to use them in some situations.
You’ve finished the design for an Apex application, and the manager asks you “when will you have it ready to test”. You resist the temptation to respond snarkily “how long is a piece of string” – which, by the way, is often the only appropriate answer if they ask for an estimate before the design work has started.

Since you have a design and a clear idea of what exactly this application will do, you can build a reasonable estimate of development time. The starting point is to break down the design into small chunks of discrete modules of work, where each chunk is something you can realistically estimate to take between half a day up to a maximum of three days. In cases where it’s something you haven’t done before, you can reduce uncertainty by creating a small Proof-of-Concept application or code snippet and seeing how the abstract ideas in the design might work in reality. This is where Apex comes in handy – by the time the design has completed, you’ll have a database schema (you created the schema in a tool like SQL Developer, didn’t you – so you can generate the DDL for that in a jiffy) and you can just point Apex to that and use the New Application wizard to create a simple application.
I plan all my projects using Trello, recording estimates using the Scrum for Trello extension. I don’t know much about the “Scrum” method but this extension allows me to assign “points” to each task (blue numbers on each card, with a total at the top of each list). I used to use a 1 point = 1 day (8 hours) convention, but I was finding most of the tasks were more fine grained (I was assigning 0.5 and 0.25 points to most tasks) so I’ve now switched to a convention of 1 point = 1 hour (more or less). In other words, I’d report my estimates with the assumption that my “velocity” would be 8 points per day.
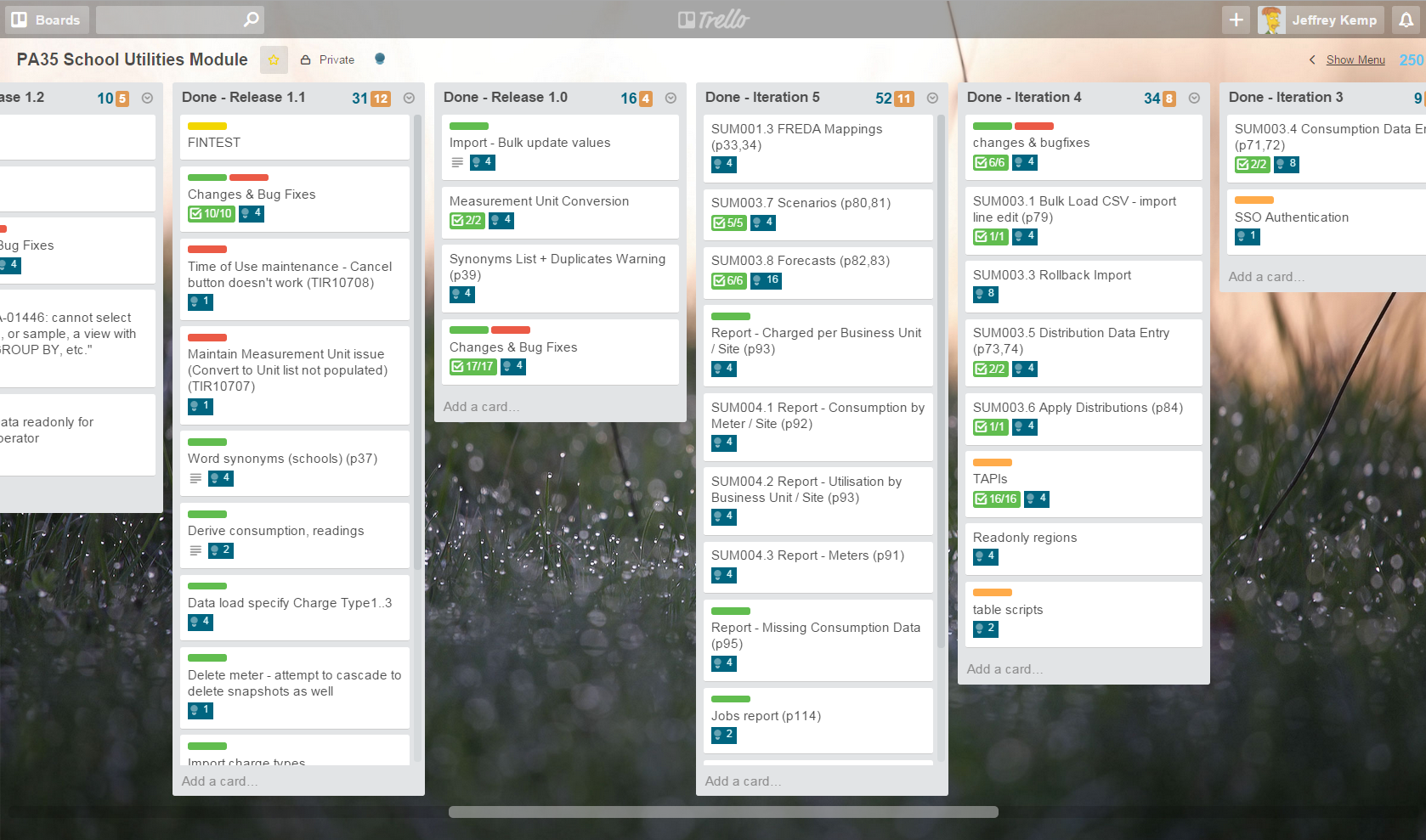
(note: the blue numbers are the Scrum for Trello points, and the orange numbers are simply the number of cards in the list)
My points system looks roughly like this:
- Simple report, form or process = 4 points
- Complex report or form or process = 8 points
- Very complex form or process = 24 points
- Simple bug fix / tweak = 1 point
- Complex bug fix / enhancement = 2 to 8 points depending on complexity
In addition to that, I keep a daily diary of work done in Evernote which has allowed me to do what I’ve wanted to do for a while now: measure my actuals vs. estimates for my projects, in order to calibrate my estimates for future projects. I made up a quick spreadsheet showing the development work for two projects, showing the original estimate, the start and finish dates, and actual development days worked (accurate roughly to the nearest half day, not counting non-development time like meetings and other project work). This allows me to see how my actual development time compares to my original estimates.
SAM Development (16 Jun 2014 to 11 Dec 2014):
- Estimate: 715 points (“18 weeks”)
- Actual: 103.5 days (21 weeks)
- Avg. points per day (“velocity”): 6.9
SAM Support (12 Dec 2014 to 29 Jul 2015):
- Estimate: 460 points (“12 weeks”)
- Actual: 64.5 days (13 weeks)
- Avg. points per day (“velocity”): 7.1
SUM Development (4 Jun 2015 to present):
- Estimate: 238 points (“6 weeks”)
- Actual: 31 days (6 weeks)
- Avg. points per day (“velocity”): 7.7
Details: EstimatesCalibration.xlsx
Since my reported estimates were roughly 8 points = 1 day, it seems I tend to underestimate. It may seem that my estimates are getting better (since my Points per Day is approaching 8), but that trend is more likely a result of SUM involving a lot less uncertainty and risk and being a smaller project overall. SAM was in a new environment and new client, whereas SUM is merely an additional application in the same environment for the same client. I was also able to re-use or adapt a lot of infrastructure-type code and Apex components from SAM in SUM.
The other thing that I can see from the details is that my “velocity” (points per day) is higher in the earlier stages of development, probably because I have plenty of work planned out, and I can work for several days in a row, uninterrupted by meetings and other distractions. In later stages, my attention gets divided by bug fixes, enhancement requests, meetings, doing design work for the next project, and general waiting-for-other-people-to-do-their-jobs.
For my next project I’ll estimate using the same points system as above, but factor in a 7 points-per-day to the estimates that I report.
Do you have a system of your own you use to create estimates and measure their accuracy? If not, why not try this for yourself? Do you keep track of your estimates and progress? If not, I recommend you start 🙂
I have Tom Kyte’s “Ask Tom” in my feed reader, and every now and then it opens for questions and the flood pours in. Quite often there is an interesting question, but more often than not there are quite a lot of “poor” questions: some just poorly worded, some too-easily-googleable, others are could-have-answered-from-the-docs questions. It’s not dissimilar to StackOverflow, which doesn’t suffer so much because of the army of people who work together to either improve or close these types of questions. Sometimes I think “Why did you waste Tom’s time with that? You could have googled it, searched the docs, or opened SO and you’d probably find a good answer there without even having to ask it.”
However, my impression is wrong, I think, because my feed reader only shows me the initial question, and not the detailed follow-up by Tom and others. I was reminded today of how a poor question can still lead to enlightenment, by this excellent quote by Tom:
As things grow and change over time – engineers need to use different approaches. The planes I fly in have wings that go straight out from the plane. That is because I fly at about 500 mph. A fighter jet at mach 2 would be going 1,500 mph. The wings on a fighter jet are significantly different in their architecture – because if they weren’t it wouldn’t work. We have different types of bridges in order to cross different types of chasms. We have different building styles for different types of builds (stick and brick for a 2 story house, steel girders in a frame for 30 story buildings).
As you scale up, the solutions that worked for trivial amounts of data will not necessarily work for large amounts of data.
If you are in a place that says “make it work but do not change code” – expect to have a bad day.
(Source)
And, if you’re wondering how he keeps up with all this:
After 14 years on asktom and 20 years total (usenet news groups last century) answering tens of thousands of questions, I took a break from social media stuff.
(Source)
We could all do with a break from time to time, I think 🙂
 My current client has a large number of APEX applications, one of which is a doozy. It is a mission-critical and complex application in APEX 4.0.2 used throughout the business, with an impressively long list of features, with an equally impressively long list of enhancement requests in the queue.
My current client has a large number of APEX applications, one of which is a doozy. It is a mission-critical and complex application in APEX 4.0.2 used throughout the business, with an impressively long list of features, with an equally impressively long list of enhancement requests in the queue.
They always have a number of projects on the go with it, and they wanted us to develop two major revisions to it in parallel. In other words, we’d have v1.0 (so to speak) in Production, which still needed support and urgent defect fixing, v1.1 in Dev1 for project A, and v1.2 in Dev2 for project B. Oh, and we don’t know if Project A will go live before Project B, or vice versa. We have source control, so we should be able to branch the application and have separate teams working on each branch, right?
We said, “no way”. Trying to merge changes from a branch of an APEX app into an existing APEX app is not going to work, practically speaking. The merged script would most likely fail to run at all, or if it somehow magically runs, it’d probably break something.
So we pushed back a bit, and the terms of the project were changed so that development of project A would be done first, and the development of project B would follow straight after. So at least now we know that v1.2 can be built on top of v1.1 with no merge required. However, we still had the problem that production defect fixes would still need to be done on a separate version of the application in dev, and that they needed to continue being deployed to sit/uat/prod without carrying any changes from our projects.
The solution we have used is to have two copies of dev, each with its own schema, APEX application and version control folder: I’ll call them APP and APP2. We took an export of APP and created APP2, and instructed the developer who was tasked with production defect fixes to manually duplicate his changes in both APP and APP2. That way the defect fixes were “merged” in a manual fashion as we went along – also, it meant that the project development would gain the benefit of the defect fixes straight away. The downside was that everything worked and acted as if they were two completely different and separate applications, which made things tricky for integration.
Next, for developing project A and project B, we needed to be able to make changes for both projects in parallel, but we needed to be able to deploy just Project A to SIT/UAT/PROD without carrying the changes from project B with it. The solution was to use APEX’s Build Option feature (which has been around for donkey’s years but I never had a use for it until now), in combination with Conditional Compilation on the database schema.
I created a build option called (e.g.) “Project B”. I set Status = “Include”, and Default on Export = “Exclude”. What this means is that in dev, my Project B changes will be enabled, but when the app is exported for deployment to SIT etc the build option’s status will be set to “Exclude”. In fact, my changes will be included in the export script, but they just won’t be rendered in the target environments.
When we created a new page, region, item, process, condition, or dynamic action for project B, we would mark it with our build option “Project B”. If an existing element was to be removed or replaced by Project B, we would mark it as “{NOT} Project B”.
Any code on the database side that was only for project B would be switched on with conditional compilation, e.g.:
$IF $$projectB $THEN
PROCEDURE my_proc (new_param IN ...) IS...
$ELSE
PROCEDURE my_proc IS...
$END
When the code is compiled, if the projectB flag has been set (e.g. with ALTER SESSION SET PLSQL_CCFLAGS='projectB:TRUE';), the new code will be compiled.
Build Options can be applied to:
- Pages & Regions
- Items & Buttons
- Branches, Computations & Processes
- Lists & List Entries
- LOV Entries
- Navigation Bar & Breadcrumb Entries
- Shortcuts
- Tabs & Parent Tabs
This works quite well for 90% of the changes required. Unfortunately it doesn’t handle the following scenarios:
1. Changed attributes for existing APEX components – e.g. some layout changes that would re-order the items in a form cannot be isolated to a build option.
2. Templates and Authorization Schemes cannot be marked with a build option.
On the database side, it is possible to detect at runtime if a build option has been enabled or not. In our case, a lot of our code was dependent on schema structural changes (e.g. new table columns) which would not compile in the target environments anyway – so conditional compilation was a better solution.
Apart from these caveats, the use of Build Options and Conditional Compilation have made the parallel development of these two projects feasible. Not perfect, mind you – but feasible. The best part? There’s a feature in APEX that allows you to view a list of all the components that have been marked with a Build Option – this is accessible from Shared Components -> Build Options -> Utilization (tab).
Enhancement Requests:
1. If Build Options could be improved to allow the scenarios listed above, I’d be glad. In a perfect world, I should be able to go into APEX, select “Project B”, and all my changes (adding/modifying/removing items, regions, pages, LOVs, auth schemes, etc) would be marked for Project B. I could switch to “Project A”, and my changes for Project B would be hidden. I think this would require the APEX engine to be able to have multiple definitions of each item, region or page, one for each build option. Merging changes between build options would need to be made possible, somehow – I don’t hold any illusions that this would be a simple feature for the APEX team to deliver.
2. Make the items/regions/pages listed in the Utilization tab clickable, so I can easily click through and change properties on them.
3. Another thing I’d like to see from the APEX team is builtin GUI support for exporting applications as a collection of individual scripts, each independently runnable – one for each page and shared component. I’m aware there is a Java tool for this purpose, but the individual scripts it generates cannot be run on their own. For example, if I export a page, I should be able to import that page into another copy of the same application (but with a different application ID) to replace the existing version of that page. I should be able to check in a change to an authorization scheme or an LOV or a template, and deploy just the script for that component to other applications, even in other workspaces. The export feature for all this should be available and supported using a PL/SQL API so that we can automate the whole thing and integrate it with our version control and deployment software.
4. What would be really cool, would be if the export scripts from APEX were structured in such a way that existing source code merge tools could merge different versions of the same APEX script and result in a usable APEX script. This already works quite well for our schema scripts (table scripts, views, packages, etc), so why not?
Further Reading:
Warning: this is a rant.
This is just a collection of observations of Hibernate, from the perspective of an Oracle developer/”DBA”. I’m aware of some of the benefits of using Hibernate to shield Java developers from having to know anything about the database or the SQL language, but sometimes it seems to me that we might generally be better off if they were required to learn a little about what’s going on “underneath the hood”. (Then I remind myself that it’s my job to help them get the most out of the database the client spent so much money getting.)
So, here are my gripes about Hibernate – just getting them off my chest so I can put them to bed.
Disclaimer: I know every Hibernate aficionado will jump in with “but it’s easy to fix that, all you have to do is…” but these are generalizations only.
 Exhibit A: Generic Query Generators
Exhibit A: Generic Query Generators
As soon as I’d loaded all the converted data into the dev and test instances, we started hitting silly performance issues. A simple search on a unique identifier would take 20-30 seconds to return at first, then settle down to 4-8 seconds a pop. Quite rightly, everyone expected these searches to be virtually instant.
The culprit was usually a query like this:
select count(*) as y0_
from XYZ.SOME_TABLE this_
inner join XYZ.SOME_CHILD_TABLE child1_
on this_.PARENT_ID=child1_.PARENT_ID
where lower(this_.UNIQUE_IDENTIFIER) like :1
order by child1_.COLH asc, child1_.COLB asc, this_.ANOTHER_COL desc
What’s wrong with this query, you might ask?
Issue 1: Case-insensitive searches by default
Firstly, it is calling LOWER() on the unique identifier, which will never contain any alphabetic characters, so case-insensitive searches will never be required – and so it will not use the unique index on that column. Instead of forcing the developers to think about whether case-insensitive searches are required or not for each column, it allows them to simply blanket the whole system with these – and quite often no-one will notice until the system goes into UAT or even Prod and someone actually decides to test searching on that particular column, and decides that waiting for half a minute is unacceptable. It’s quite likely that for some cases even this won’t occur, and these poorly performing queries (along with their associated load on the database server) will be used all the time, and people will complain about the general poor performance of the database.
Issue 2: Count first, then re-query for the data
Secondly, it is doing a COUNT(*) on a query which will immediately after be re-issued in order to get the actual data. I’d much prefer that the developers were writing the SQL by hand. That way, it’d be a trivial matter to ask them to get rid of the needless COUNT(*) query; and if they simply must show a total record count on the page, add a COUNT(*) OVER () to the main query – thus killing two birds with one efficient stone.
 Exhibit B: Magical Class Generators (tables only)
Exhibit B: Magical Class Generators (tables only)
Issue 3: No views, no procedures, no functions
When someone buys Hibernate, they might very well ask: is it possible to call an Oracle procedure or function with this product? And the answer is, of course, “yes”. Sure, you can do anything you want!
The day the Java developers peel off the shrinkwrap, the first thing they try is creating a Java class based on a single table. With glee they see it automagically create all the member attributes and getter/setter methods, and with no manual intervention required they can start coding the creation, modification and deletion of records using this class, which takes care of all the dirty SQL for them.
Then, the crusty old Oracle developer/”DBA” comes along and says: “It’d be better if you could use this API I’ve lovingly crafted in a PL/SQL package – everything you need is in there, and you’ll be shielded from any complicated stuff we might need to put in the database now or later. All you have to do is call these simple procedures and functions.” And the Java developer goes “sure, no problem” – until they discover that Hibernate cannot automatically create the same kind of class they’ve already gotten accustomed to.
“What, we actually need to read the function/procedure definition and hand-code all the calls to them? No sir, not happening.” After all, they bought Hibernate to save them all that kind of work, and who’s going to blame them?
So, you say, “Ok, no problem, we’ll wrap the API calls with some simple views, backed by instead-of triggers.” But then they hit another wall – Hibernate can’t tell from a view definition how that view relates to other views or tables.
The end result is that all the Java code does is access tables directly. And you get the kind of queries (and worse) that you saw in Exhibit “A” above.
There. I feel so much better already.
/rant
 The cost of providing Virtual Machines to all your developers can be quite high, especially in terms of initially setting it all up (e.g. a typical developer may require two VMs running concurrently, one for the database server, one for the app server; their desktops will require enough grunt to run these while they also run their dev tools, or they’ll need at least two computers on their desks; also, you’ll need a means of scaling down the data volumes if your database is too big); but you will gain a whole lot more productivity, sanity, happiness and love from your developers.
The cost of providing Virtual Machines to all your developers can be quite high, especially in terms of initially setting it all up (e.g. a typical developer may require two VMs running concurrently, one for the database server, one for the app server; their desktops will require enough grunt to run these while they also run their dev tools, or they’ll need at least two computers on their desks; also, you’ll need a means of scaling down the data volumes if your database is too big); but you will gain a whole lot more productivity, sanity, happiness and love from your developers.
10. Fail safe.
If everything goes terribly wrong, simply restore to snapshot (duh, obviously).
9. Handle shifting conditions outside your project.
As often as I can (e.g. after a few weeks if a lot of development has gone on), I re-run the scripts on a VM based on a fresh copy of Prod – any changes that anyone else has made without my knowing it, which affect my scripts adversely, get picked up early.
8. Upgrade scripts never raise an error (unless something unexpected occurs).
It is normal for a typical upgrade script to raise many errors (e.g. “object not found” when running a standard “DROP x, CREATE x” script). However, I wrap any command like this with a custom exception handler that swallows the errors that I know are expected or benign. That way, when I hand over my upgrade scripts to the DBA, I can say, “if you get any error messages, something’s gone wrong”, which is a bit better than handing over a list of error messages they can safely ignore. Even better, I can add WHEN SQLERROR EXIT to the top of my upgrade script, so it exits out straightaway if the upgrade fails at any point.
7. Sanity Restore.
You’ve been beating your head against the wall for five minutes, and no-one’s around to add a second eye to your problem; you’re starting to wonder if the bug was something you introduced, or has always been there; and you can’t just log into production to test it. VM to the rescue – undo all your changes by restoring to an earlier snapshot, then see if your problem was a pre-existing issue.
6. Other Developers.
Let’s face it. Things would go a lot smoother if not for all the efforts of other developers to impede your progress by making random changes in the dev environment. Am I right? Well, with your private VM this is no longer a problem. Of course, with a private VM, if anything goes wrong, it’s incontrovertibly your fault now…
5. “Did you turn it off and on again?”
Finally, no need to nag the DBA to bounce the database server, or flush the shared pool, or in fact anything that requires more access than you’d usually get as a lowly developer. Need to increase that tablespace? Drop a couple hundred tables? No problem.
4. Real size estimates.
This works really well when you’re working with relatively small databases (i.e. where an entire copy of prod can be practically run in a VM). Run your upgrade script, which fails halfway through with a tablespace full error. Restore to snapshot, resize the appropriate datafile, re-run the upgrade. Rinse, repeat until no more “out of space” errors; now you know with a high degree of confidence how much extra space your upgrade requires, and for which datafiles.
3. Reduced down-time.
Dev server down? Being upgraded? Been appropriated by another department? No worries – your dev team can continue working, because they’ve got their VMs.
2. Did I say “Fail Safe” already?
I can’t emphasize this one enough. Also, the other side of “Other Developers” is that you are an Other Developer; and the mistakes you will, inevitably, make will never see the light of day (and draw everyone’s ire) if they’re made in your private VM.
1. Smug.
My last deployment to Test of a major release of an application executed perfectly, 100%, correct, first time. I couldn’t believe my eyes – I was so accustomed to my scripts failing for random reasons (usually from causes outside my control, natch). It was all thanks to my use of VMs to develop my fault-tolerant upgrade scripts. I was smug.
 Every place has a different way of assigning priority and/or severity to defect reports – some bigger places have many different ways (unfortunately). I’ve not been subjected to Prince2 training so here’s my take on this subject.
Every place has a different way of assigning priority and/or severity to defect reports – some bigger places have many different ways (unfortunately). I’ve not been subjected to Prince2 training so here’s my take on this subject.
I reckon, the simpler the scheme, the more likely it will be used consistently. Every defect should have just a single priority/severity (call it what you will): Critical, High, Medium or Low.
- Critical – problem significantly affects ability to test the system; “showstopper” – all other work to be delayed until the issue is resolved – an example might be “unable to log in”; “screen x opens with error every time”; “function y causes my computer to explode”
- High – problem affects critical functionality; should be fixed as a matter of priority over other issues – an example would be “error x always/often occurs at process point y”
- Medium – functionality not working as per specified requirements; must eventually be fixed (at least before Go Live) – an example would be “default value not being set correctly”; “navigation does not work correctly”
- Low – cosmetic issue; “nice to have” function; or error/warning occurs very infrequently but doesn’t significantly affect correct processing; ok to Go Live if not fixed
That’s it. Notice how each category is unambiguous in what it means to the developers, testers and others. I’d expect a system to normally have mostly Medium issues, several Highs, hopefully no Criticals, and maybe some Lows. I’d expect some issues to be reclassified up or down as they are assessed, as developers negotiate with the testers and business reps.
I’m certain that there’s all sorts of great reasons why someone needs more levels, or needs to separate the “priority” concept from the “severity” or “impact” concepts, but to my mind there’s not a lot gained from forcing all your testers, developers, and change managers to learn a complicated system, and classify and update their records. When you need a 2D or 3D matrix of priority vs severity vs whatever printed and posted on your cubicle wall, it’s time to ask, “is all this really necessary?”.
Keep it simple, and everyone will not only use it, everyone else will understand it.
P.S. did you notice that Apex’s builtin “feedback” feature only has one level? It’s either a bug report, or it’s not (e.g. an enhancement request or comment). I love that.
Steven Feuerstein lists seven excellent “Golden Rules” in his presentation (via Eddie Awad) and says “Don’t repeat anything. Aim for a Single Point of Definition for every aspect of your application – formulas, business rules, magic values, SQL statements.” giving the following code as exhibit A:
I’m guessing in his presentation he spoke about various things that could be done to improve this code, but they’re not in the PDF; so I’d like to give it a go myself and see how much we can improve the maintainability of this code by reducing hard-coding.
1. Type Declarations
Instead of declaring parameters and variables as NUMBER, VARCHAR2 etc, these should use the %TYPE operator so that they are automatically synchronized with the datatype from the table columns they represent:
PROCEDURE process_employee
(department_id_in IN employees.department_id%TYPE)
IS
l_id employees.employee_id%TYPE;
l_salary employees.salary%TYPE;
...
l_name, however, is not based on any table column we know of at this point; so there is no %TYPE we can use for it. But bear with me, we’ll fix this later.
2. Magic Values
This one’s a no-brainer: that “10000000” is obviously a magic value that some bean-counter decided was the correct threshold for the CEO’s salary. Whatever.
You might define this as a constant defined in a global package specification, e.g.
CREATE PACKAGE employee_constant AS
ceo_salary_threshold CONSTANT employees.salary%TYPE := 10000000;
END employee_constant;
Personally, I’d suspect that the business will review and revise this number from time to time, to keep up with inflation; so we might end up needing a database table to store the current threshold, plus a date range for which the threshold applies. I’d then add an interface on top of this table so that queries and procedures don’t need to know how to get the current threshold. We can retrofit this later by changing ceo_salary_threshold into a function instead of a constant. That’s a bit beyond the scope of this exercise, however.
3. Formatting Rules
The rule about formatting an employee name as “LAST,FIRST” is duplicated in a comment and in the SELECT statement; and chances are it will be required elsewhere in the application as well. My preferred method for creating a SPOD for this sort of business rule used to be to move the implementation into a view, e.g.:
CREATE VIEW formatted_employees AS
SELECT employees.*,
employees.last_name || ',' || employees.first_name
AS full_name
FROM employees;
COMMENT ON COLUMN formatted_employees.full_name
IS 'Full name: LAST COMMA FIRST (ReqDoc 123.A.47)';
This view is what I like to call a “formatting” view: it is only allowed to query one table, it contains no WHERE, GROUP BY or HAVING clauses, and it selects all the columns from the table. The view can be used almost anywhere the table may be used. It adds additional columns that format the data in various ways. If need be, we can even add INSTEAD OF triggers to handle inserts/updates on the derived columns – if the business rules make the conversion from derived-to-underlying-column well defined.
So, now we can redefine the cursor as:
CURSOR emps_in_dept_cur
IS
SELECT employee_id, salary, full_name AS lname
FROM formatted_employees
WHERE department_id = department_id_in;
Notice that I don’t call the column “last_comma_first” or anything like that – that would again be hard-coding the business rule, which would then be replicated throughout the application. In Oracle 11g, however, I think it might be better to create virtual columns on the table instead:
ALTER TABLE employees ADD (
full_name VARCHAR2(100)
GENERATED ALWAYS AS (last_name || ',' || first_name) VIRTUAL
);
COMMENT ON COLUMN employees.full_name
IS 'Full name: LAST COMMA FIRST (ReqDoc 123.A.47)';
CURSOR emps_in_dept_cur
IS
SELECT employee_id, salary, full_name AS lname
FROM employees
WHERE department_id = department_id_in;
The virtual column can have its own stats, and even an index if needed for querying.
Another option would be to create a function that does this formatting:
CREATE FUNCTION employee_full_name
(last_name IN employees.last_name%TYPE,
first_name IN employees.first_name%TYPE)
RETURN VARCHAR2 DETERMINISTIC IS
--Full name: LAST COMMA FIRST (ReqDoc 123.A.47)
BEGIN
RETURN last_name || ',' || first_name;
END employee_full_name;
We could call this function from the procedure or the view, but if we’re on 11g there’s no reason we can’t create a virtual column on it:
ALTER TABLE employees ADD (
full_name VARCHAR2(100)
GENERATED ALWAYS
AS (employee_full_name(last_name,first_name)) VIRTUAL
);
Another advantage to using the view or a virtual column is that we can now remove the “VARCHAR2 (100)” from the variable declaration, e.g.:
l_name employees.full_name%TYPE;
4. Cursor Parameter
The cursor refers directly to the parameter to the procedure, which is a no-no – this couples the cursor too much with the procedure, i.e. we can’t re-use it elsewhere unless we always define a variable “department_id_in”. Instead, we should use a cursor parameter:
CURSOR emps_in_dept_cur
(department_id_in IN employees.department_id%TYPE)
IS
SELECT employee_id, salary, full_name AS lname
FROM employees
WHERE department_id = emps_in_dept_cur.department_id_in;
The addition of the context “emps_in_dept_cur.” is not strictly necessary, but it is good practice to define the scope of all variables so that unrelated changes (e.g. the addition of a column called “department_id_in”) don’t change the code.
5. Cursor Row Type
What if we need to add 10 more columns to the cursor? At the moment we’re adding one more variable for each column of the cursor, and specifying it three times (variable declaration, cursor SELECT clause, and the FETCH INTO). We can reduce this to just once by declaring a cursor row type instead:
PROCEDURE process_employee
(department_id_in IN employees.department_id%TYPE)
IS
CURSOR emps_in_dept_cur
(department_id_in IN employees.department_id%TYPE)
IS
SELECT employee_id, salary, full_name lname
FROM employees
WHERE department_id = emps_in_dept_cur.department_id_in;
TYPE emps_in_dept_cur_type IS emps_in_dept_cur%ROWTYPE;
emp emps_in_dept_cur_type;
BEGIN
OPEN emps_in_dept_cur;
LOOP
FETCH emps_in_dept_cur
INTO emp;
...
6. Don’t COMMIT
Procedures should rarely COMMIT (there are very few exceptions to this rule, e.g. procedures declared as autonomous transactions). Transactional control should be left to the calling process – this process might need to be done along with a number of other changes elsewhere, and we would want to either COMMIT or ROLLBACK all the changes together as one transaction. What if the next procedure raised an error and we had to rollback? Our system would be left in an inconsistent state.
7. Error Package
That RAISE_APPLICATION_ERROR hard-codes an error code and an error message. What if we type the error number wrong somewhere? If the calling process handles ORA-20907 in some fashion, but we mistype it as -20908 in one procedure, the calling process will not handle it.
We could declare an exception instead, e.g. in a global package specification:
CREATE PACKAGE employee_exception AS
invalid_dept_id EXCEPTION;
PRAGMA EXCEPTION_INIT (invalid_dept_id, -20907);
END employee_exception;
Now, our exception handler can raise just the one exception:
EXCEPTION WHEN NO_DATA_FOUND THEN
RAISE employee_exception.invalid_dept_id;
However, we’ve now lost the error message. It would be better to create an error-handling package instead:
CREATE PACKAGE employee_error AS
invalid_error_no CONSTANT NUMBER := -20000;
invalid_error_no_exception EXCEPTION;
PRAGMA EXCEPTION_INIT (invalid_error_no_exception, -20000);
invalid_dept_id CONSTANT NUMBER := -20907;
invalid_dept_id_exception EXCEPTION;
PRAGMA EXCEPTION_INIT (invalid_dept_id_exception, -20907);
PROCEDURE raise_exception (error_no IN NUMBER);
END employee_exception;
CREATE PACKAGE BODY employee_error AS
PROCEDURE raise_exception (error_no IN NUMBER) IS
BEGIN
CASE error_no
WHEN invalid_dept_id
THEN RAISE_APPLICATION_ERROR(invalid_dept_id, 'Invalid department ID');
ELSE RAISE_APPLICATION_ERROR(invalid_error_no, 'Bug: invalid error number');
END;
END message;
END employee_exception;
EDIT: PRAGMA EXCEPTION_INIT only accepts literal numbers for its second parameter (or else you get PLS-00702 at compile time) – fixed accordingly
Now, our exception handler is nicely modular:
EXCEPTION WHEN NO_DATA_FOUND THEN
employee_error.raise_exception(employee_error.invalid_dept_id);
So now, our code looks like this:
PROCEDURE process_employee (department_id_in IN employees.department_id%TYPE)
IS
CURSOR emps_in_dept_cur (department_id_in IN employees.department_id%TYPE)
IS
SELECT employee_id, salary, full_name lname
FROM employees
WHERE department_id = emps_in_dept_cur.department_id_in;
TYPE emps_in_dept_cur_type IS emps_in_dept_cur%ROWTYPE;
emp emps_in_dept_cur_type;
BEGIN
OPEN emps_in_dept_cur;
LOOP
FETCH emps_in_dept_cur
INTO emp;
IF emp.salary > employee_constant.ceo_salary_threshold THEN adjust_comp_for_ceo (emp.salary);
ELSE analyze_compensation (emp.employee_id, emp.salary, employee_constant.ceo_salary_threshold); END IF;
EXIT WHEN emps_in_dept_cur%NOTFOUND;
END LOOP;
EXCEPTION WHEN NO_DATA_FOUND THEN
employee_error.raise_exception(employee_error.invalid_dept_id);
END;
One final change that one might make here is to move the SQL query right out of the procedure and use a ref cursor instead, supplied by a central “employee_cursor” package.
There are probably plenty of other changes we could make to improve the maintainability of this code further.
What do you think?
In my daily reading these two articles came fairly close together, and I have a strong feeling they are describing exactly the same project. *
From one side of the fence: A total rewrite: costly, time-consuming, but worth it?
“Our CMS was developed using Active Server Pages, and consisted of around 80,000 lines of VBScript code.”
“as we continued to develop the rest of the framework, we saw that it took a lot longer than anticipated”
From the other side: The Homegrown CMS
“If one were to create a list of adjectives to describe this monstrosity, “stable,” “reliable,” and “accurate” would be strikingly absent.”
“…nearly 200 tables (mostly imported from Microsoft Access) and not a single stored procedure. Boolean-type values were represented as a CHAR(5) field, holding possible values of ‘true’, ‘false’, or NULL…
“There were also no indexes. Nor any primary key columns… For inserts, an ID was assigned via in-line SQL by requesting the Max(ID) field of any particular table and adding 1.”
My point of view: this sounds like a good counter-example to the (very good, but general) advice offered by Joel Spolsky: don’t rewrite from scratch.
* EDIT: Vidar Langberget has advised that these are not the same project, proving that I’m not such a great prognosticator 😐



