Disclaimer: I’m not posting to make me look better, we’ve all written code that we’re later ashamed of, and I’m no different!
This is some code I discovered buried in a system some time ago. I’ve kept a copy of it because it illustrates a number of things NOT to do:
FUNCTION password_is_valid
(in_password IN VARCHAR2)
-- do NOT copy this code!!! ...
RETURN VARCHAR2 IS
l_valid VARCHAR2(1);
l_sql VARCHAR2(32000);
CURSOR cur_rules IS
SELECT REPLACE(sql_expression
,'#PASSWORD#'
,'''' || in_password || ''''
) AS sql_expression
FROM password_rules;
BEGIN
FOR l_rec IN cur_rules LOOP
l_valid := 'N';
-- SQL injection, here we come...
l_sql := 'SELECT ''Y'' FROM DUAL ' || l_rec.sql_expression;
BEGIN
-- why not flood the shared pool with SQLs containing
-- user passwords in cleartext?
EXECUTE IMMEDIATE l_sql INTO l_valid;
EXCEPTION
WHEN NO_DATA_FOUND THEN
EXIT;
END;
IF l_valid = 'N' THEN
EXIT;
END IF;
END LOOP;
RETURN l_valid;
END password_is_valid;
I am pretty sure this code was no longer used, but I couldn’t be sure as I didn’t have access to all the instances that could run it.
I had built and was managing a web site that takes registrations from thousands of people around the state for a variety of sporting events. One of the goals of the site is to collect better quality data for the people running the events, i.e. they basically needed to get a better handle on how many people were actually attending.
One of the other goals of the site was to make it as easy and hassle-free as possible for anyone to register. This meant that requiring people to sign up for an account with usernames and passwords was undesirable, so make it possible for someone to just sign up with all their info in one session (i.e. never authenticated), then never return.
This also meant that if someone started to register one day, but abandoned their “shopping cart” (so to speak), and then came back the next day, they happily re-entered all their info again – which caused duplicate records to appear in the database. Someone accidentally closes their browser – another duplicate record. Someone signs up their friend on their behalf, not knowing their friend had already signed up – another duplicate record. Someone with very little computer experience gets an error (e.g. “Date of birth must be entered.”) and responds by closing the browser and restarting – and doing this multiple times – we got five duplicate records from this person.
So I built an automated alert system which would email the team coordinators a list of the duplicate records, based on a simple case-insensitive match on first name + surname (we did have one case last year where two different people happened to have the same name, but this is a very rare occurrence when you’re talking about only a few thousand people). I also built a de-duplicator which allowed me to compare two records side-by-side and delete one of them.
In the crunch week (the week before nominations close), we were getting 40+ registrations per day – and each day I was deleting 4 or 5 duplicate records. I thought there must be a better way.
So I (naïvely) quietly added a simple validation check to the signup page – if the player’s name was already registered it showed the error message “Sorry, a registration under you name has already been created. Please login to change your registration.” along with my contact details.
 It worked, kind of – immediately I got 3 emails and 1 phone call from people who had started their signup, having earlier ignored or missed the email with their login details, and tried to sign up again. I made sure they could login, and they were able to update their existing registration without creating duplicate records. I was quietly optimistic that it would work better now.
It worked, kind of – immediately I got 3 emails and 1 phone call from people who had started their signup, having earlier ignored or missed the email with their login details, and tried to sign up again. I made sure they could login, and they were able to update their existing registration without creating duplicate records. I was quietly optimistic that it would work better now.
Unfortunately, I was wrong. A few days later (today, actually) I decided to do an audit to see if my change had actually made things better or not. I suspected that some people might ignore that error message and just put in a different name. My suspicion was warranted, as it turns out.
So far I’ve gone through over 800 records and found variances of “Bloggs, Joe” or “Bloggs, Joe B” or “Bloggso, Joe” or “Bloggs Is My Name, Joe” scattered throughout. All my validation had done was put a roadblock in front of the users, who simply drove around it by putting in a slightly different name (I saw a lot of them simply put in their middle name), and now (more importantly) my de-duplicator is useless because it only finds matches on exact given names and surnames.
I’ve removed the validation. The duplicate records are manageable, and the system is overall easier for everyone with less validation.
What’s the biggest clue you can give that your database is vulnerable to SQL injection? When your list of “forbidden words” looks suspiciously like a sample of SQL / PL/SQL keywords:
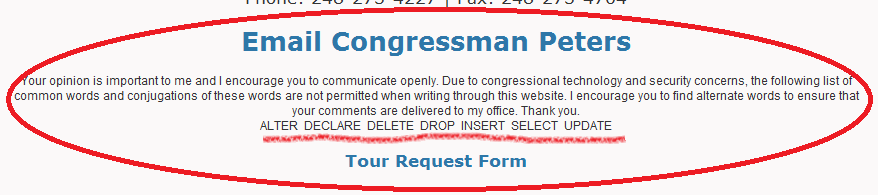
I notice that they haven’t forbidden BEGIN, CREATE, MERGE, or TRUNCATE …
Congressman Peters, your IT staff are doing it wrong.
Via: http://thedailywtf.com/Articles/Out-of-Service.aspx#pic4
") Recently I refactored some PL/SQL for sending emails – code that I wrote way back in 2004. The number of “WTF“‘s per minute has not been too high; however, I’ve cringed more times than I’d like…
Recently I refactored some PL/SQL for sending emails – code that I wrote way back in 2004. The number of “WTF“‘s per minute has not been too high; however, I’ve cringed more times than I’d like…
1. Overly-generic parameter types
When you send an email, it will have at least one recipient, and it may have many recipients. However, no email will have more than one sender. Yet, I wrote the package procedure like this:
TYPE address_type IS RECORD
(name VARCHAR2(100)
,email_address VARCHAR2(200)
);
TYPE address_list_type IS TABLE OF address_type
INDEX BY BINARY_INTEGER;
PROCEDURE send
(i_sender IN address_list_type
,i_recipients IN address_list_type
,i_subject IN VARCHAR2
,i_message IN VARCHAR2
);
Why I didn’t have i_sender be a simple address_type, I can’t remember. Internally, the procedure only looks at i_sender(1) – if a caller were to pass in a table of more than one sender, it raises an exception.
2. Functional programming to avoid local variables
Simple is best, and there’s nothing wrong with using local variables. I wish I’d realised these facts when I wrote functions like this:
FUNCTION address
(i_name IN VARCHAR2
,i_email_address IN VARCHAR2
) RETURN address_list_type;
FUNCTION address
(i_address IN address_list_type
,i_name IN VARCHAR2
,i_email_address IN VARCHAR2
) RETURN address_list_type;
All that so that callers can avoid *one local variable*:
EMAIL_PKG.send
(i_sender => EMAIL_PKG.address('joe','joe@company.com')
,i_recipients => EMAIL_PKG.address(
EMAIL_PKG.address(
'jill', 'jill@company.com')
,'bob', 'bob@company.com')
,i_subject => 'hello'
,i_message => 'world'
);
See what I did there with the recipients? Populating an array on the fly with just function calls. Smart eh? But rather useless, as it turns out; when we need to send multiple recipients, it’s usually populated within a loop of unknown sized, so this method doesn’t work anyway.
Go ahead – face your past and dig up some code you wrote 5 years ago or more. I think, if you don’t go “WTF!” every now and then, you probably haven’t learned anything or improved yourself in the intervening years. Just saying 🙂
Warning: this is a rant.
This is just a collection of observations of Hibernate, from the perspective of an Oracle developer/”DBA”. I’m aware of some of the benefits of using Hibernate to shield Java developers from having to know anything about the database or the SQL language, but sometimes it seems to me that we might generally be better off if they were required to learn a little about what’s going on “underneath the hood”. (Then I remind myself that it’s my job to help them get the most out of the database the client spent so much money getting.)
So, here are my gripes about Hibernate – just getting them off my chest so I can put them to bed.
Disclaimer: I know every Hibernate aficionado will jump in with “but it’s easy to fix that, all you have to do is…” but these are generalizations only.
 Exhibit A: Generic Query Generators
Exhibit A: Generic Query Generators
As soon as I’d loaded all the converted data into the dev and test instances, we started hitting silly performance issues. A simple search on a unique identifier would take 20-30 seconds to return at first, then settle down to 4-8 seconds a pop. Quite rightly, everyone expected these searches to be virtually instant.
The culprit was usually a query like this:
select count(*) as y0_
from XYZ.SOME_TABLE this_
inner join XYZ.SOME_CHILD_TABLE child1_
on this_.PARENT_ID=child1_.PARENT_ID
where lower(this_.UNIQUE_IDENTIFIER) like :1
order by child1_.COLH asc, child1_.COLB asc, this_.ANOTHER_COL desc
What’s wrong with this query, you might ask?
Issue 1: Case-insensitive searches by default
Firstly, it is calling LOWER() on the unique identifier, which will never contain any alphabetic characters, so case-insensitive searches will never be required – and so it will not use the unique index on that column. Instead of forcing the developers to think about whether case-insensitive searches are required or not for each column, it allows them to simply blanket the whole system with these – and quite often no-one will notice until the system goes into UAT or even Prod and someone actually decides to test searching on that particular column, and decides that waiting for half a minute is unacceptable. It’s quite likely that for some cases even this won’t occur, and these poorly performing queries (along with their associated load on the database server) will be used all the time, and people will complain about the general poor performance of the database.
Issue 2: Count first, then re-query for the data
Secondly, it is doing a COUNT(*) on a query which will immediately after be re-issued in order to get the actual data. I’d much prefer that the developers were writing the SQL by hand. That way, it’d be a trivial matter to ask them to get rid of the needless COUNT(*) query; and if they simply must show a total record count on the page, add a COUNT(*) OVER () to the main query – thus killing two birds with one efficient stone.
 Exhibit B: Magical Class Generators (tables only)
Exhibit B: Magical Class Generators (tables only)
Issue 3: No views, no procedures, no functions
When someone buys Hibernate, they might very well ask: is it possible to call an Oracle procedure or function with this product? And the answer is, of course, “yes”. Sure, you can do anything you want!
The day the Java developers peel off the shrinkwrap, the first thing they try is creating a Java class based on a single table. With glee they see it automagically create all the member attributes and getter/setter methods, and with no manual intervention required they can start coding the creation, modification and deletion of records using this class, which takes care of all the dirty SQL for them.
Then, the crusty old Oracle developer/”DBA” comes along and says: “It’d be better if you could use this API I’ve lovingly crafted in a PL/SQL package – everything you need is in there, and you’ll be shielded from any complicated stuff we might need to put in the database now or later. All you have to do is call these simple procedures and functions.” And the Java developer goes “sure, no problem” – until they discover that Hibernate cannot automatically create the same kind of class they’ve already gotten accustomed to.
“What, we actually need to read the function/procedure definition and hand-code all the calls to them? No sir, not happening.” After all, they bought Hibernate to save them all that kind of work, and who’s going to blame them?
So, you say, “Ok, no problem, we’ll wrap the API calls with some simple views, backed by instead-of triggers.” But then they hit another wall – Hibernate can’t tell from a view definition how that view relates to other views or tables.
The end result is that all the Java code does is access tables directly. And you get the kind of queries (and worse) that you saw in Exhibit “A” above.
There. I feel so much better already.
/rant
Seen in the wild:
... WHERE substr(amount,0, 1) != '-'
If you wanted to query a table of monetary transactions for any refunds (i.e. where the transaction amount is negative), how would you do it? Perhaps you’d think about avoiding problems that might occur if the default number format were to change, hm?
(before you say it: no, there is no index on amount, so it wasn’t a misguided attempt to avoid an index access path…)
Came across this in a form (6i) to be run on a 9i db. Not only is this code about 33 lines of code too long and issues any number of unnecessary database queries, its name is quite unrelated to its intended function. Needless to say it was easily replaced with a single call to INSTR.
PROCEDURE alpha_check
(ref_in IN VARCHAR2
,ref_out OUT VARCHAR2) IS
-- Procedure included to distinguish
-- ref_in between ID or reference.
l_alpha_char VARCHAR2 (1);
l_alpha_pos NUMBER;
l_found_pos NUMBER;
l_search_string VARCHAR2 (100) := ' ';
CURSOR cur_get_next_alpha(N NUMBER) IS
SELECT SUBSTR(l_search_string,N,1)
FROM dual;
CURSOR cur_check_for_alpha(C VARCHAR2)IS
SELECT INSTRB(ref_in,C, 1)
FROM dual;
BEGIN
IF ref_in IS NULL THEN
ref_out := 'X';
RETURN;
END IF;
FOR I IN 1..LENGTH(l_search_string) LOOP
OPEN cur_get_next_alpha(I);
FETCH cur_get_next_alpha
INTO l_alpha_char;
CLOSE cur_get_next_alpha;
FOR J IN 1..LENGTH(ref_in) LOOP
OPEN cur_check_for_alpha(l_alpha_char);
FETCH cur_check_for_alpha
INTO l_found_pos;
CLOSE cur_check_for_alpha;
IF l_found_pos > 0 THEN
ref_out := 'N';
RETURN;
END IF;
END LOOP;
END LOOP;
ref_out := 'Y';
EXCEPTION
WHEN OTHERS THEN
pc_ref_out := 'X';
END;
Looks like it may have been copied from the same source as “As bad as it gets”.
Seen in the wild:
SELECT ROWID
BULK COLLECT INTO t_rowids
FROM my_table
WHERE ...
FOR UPDATE NOWAIT;
IF t_rowids.COUNT > 0 THEN
FORALL i IN t_rowids.FIRST..t_rowids.LAST
DELETE FROM my_table
WHERE ROWID = t_rowids(i);
END IF;
Of course, we couldn’t just do a “DELETE FROM my_table WHERE …”, could we…
