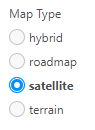
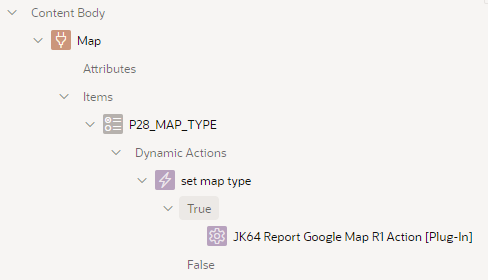
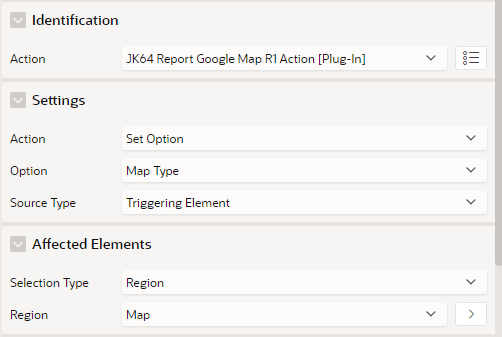
The Dynamic Action plugin, called JK64 Report Google Map R1 Action, allows you to implement any of a range of custom behaviours on your map region. If installed, you can make the map respond to user behaviour or other events without needing to resort to writing your own custom JavaScript.
You can add a dynamic action to modify a variety of options and attributes of the map, execute searches, pan and zoom, load features via geoJson, and more – and these can be based on the value of items on your page, or via JavaScript expressions that you specify.
This is implemented as a radio item with a dynamic action on the Change event:
The dynamic action has the following attributes:
Note that in this case, it sets an Option – Map Type, based on the triggering element (the P28_MAP_TYPE item). The Affected Elements is required, and must refer to the map region that we want to change.
Notice anything missing? That’s right – No Code needed!
The plugin makes it easy to customise which of the default Google Map controls (buttons, etc.) are shown to the user:
Full Screen control
Map Type control
Rotate control
Scale control
Street View Pegman control
Zoom control
Other options that can be set include:
Clickable Icons
Disable default UI
Gesture Handling
Heading
Keyboard shortcuts
Map Type
Maximum Zoom level
Minimum Zoom level
Restrict search to Country
Styles
Tilt
Zoom level
In addition, the plugin allows you to restrict the map to a set of bounds, via the Restrict to Bounds or Restrict to Bounds Strict Mode actions.
Another enhancement included in this release is explicit support for the Table / View data source. This is simple to use, although not quite as flexible as the SQL Query option. Your table or view must include columns with the correct column names expected by the selected Visualisation – for example, if your Visualisation is Pins, the table or view must have columns named lat, lng, name and id. Click the Help tab on Table Name for more details, or review the WIKI (https://github.com/jeffreykemp/jk64-plugin-reportmap/wiki/SQL-Query-Examples).
NOTE: the plugin supports APEX 18.2 and later. It is no longer planned to include backports for older versions of APEX.
A big thanks to many APEX developers around the world who have installed and used the map plugin over the years. Your suggestions, questions and bug reports have contributed a great deal to improving the plugin.
Version 1.2 of the ReportMap Google Map plugin has been released today. While the rest of you have been idling away under Covid-19 restrictions, I’ve been happy as a clam working on some exciting enhancements to the plugin.
Included in this release are the following new features:
New visualisation: Spidifier
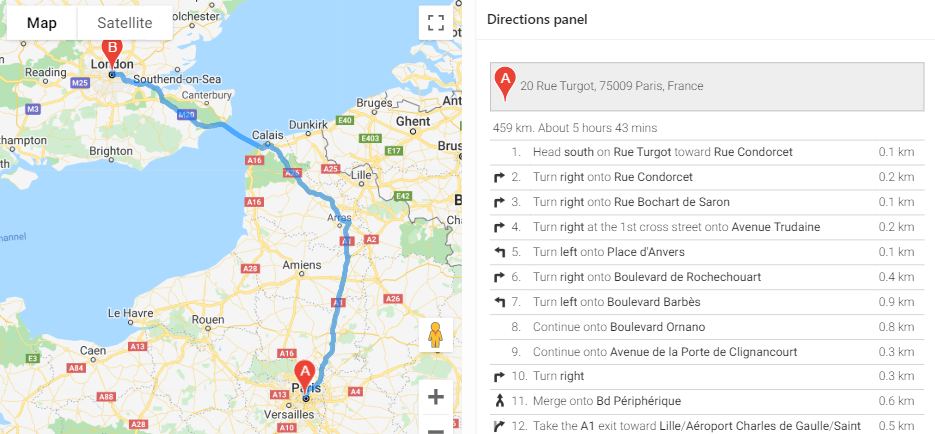
Show turn-by-turn Directions
Customise each Marker with your own JavaScript function
Load large data sets in batches
Show spinner while data is loading
Localisation options
A bug when the new Friendly URLs feature of Oracle APEX 20.1 is used with the Clustering visualisation has also been fixed in this release.
The full list of enhancements and bugfixes, with links to the issues register, may be viewed here.
If you use the Directions or Route Map options, you can now show the turn-by-turn directions on your page, anywhere you want.
The documentation has been updated. The plugin now has four new plugin attributes, as well as a number of other attributes that can be set via JavaScript (the officially supported ones are documented on the plugin attributes page). Three new plugin events have also been added to support the new features.
Spiderfier
If you have a map that needs to show a lot of pins, especially ones that are close together, the plugin previously had the option of Clustering them at high zoom levels. The user could click on a cluster to zoom in enough to show the individual pins. One weakness of this approach is that if one or more pins are almost (or exactly) overlapping, the cluster never “unclusters” – the user cannot zoom in far enough to get the pins to show individually.
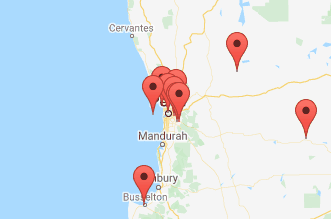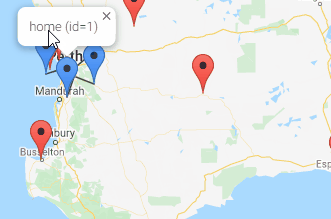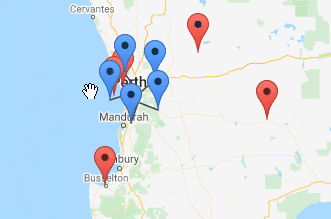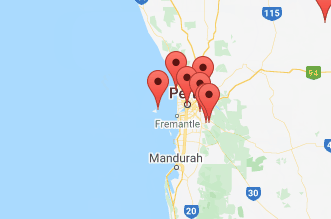
This release provides another Visualisation option, Spiderfier. This uses the OverlappingMarkerSpiderfier to control how pins react when clicked. When the user clicks a pin that is close or overlapping with other pins, it shifts the pins in that area into a ring, or a spiral (depending on how many pins are there) with lines pointing back to their original location. It also colours them blue to indicate they’ve been “spiderfied”. The user can then hover and click each marker separately.
If the user zooms in, the Spiderfier automatically returns all the pins to their original location.
I think the defaults I’ve set work reasonably well. If needed, you can customise the Spiderfier by setting its options via the JavaScript Initialisation Code (refer to “spiderfier options” here for details). You can also provide your own formatting function to change how the markers look when they are “spiderfied”.
Marker Icons
The WIKI has been augmented with a handy guide to Map Icons. The plugin has long supported the ability to specify custom images for the marker icons. This release gives a whole lot more control over the markers to the developer:
If all the icons in the query are being loaded from the same location, you can now set the iconBasePath option once and just have a relative icon file name in the query. When there is a lot of data to show in the map, this can significantly reduce the volume of data loaded to the client, which can lead to a significant performance improvement.
The developer can now supply a custom JavaScript function (via the markerFormatFn option) to format each marker using whatever logic they need.
For example, if the marker icon needs to be different according to some data value, you can send the data via one of the flex fields, and then write your custom function to set the marker icon depending on the value of the flex field.
You could also modify other characteristics of the marker, such as the title (hover text), info text (popup window), icon anchor point, opacity, and even position (although usually I’d expect your query would provide the correct lat/lng coordinates).
If you have a large number of custom icons you wish to use, along with a large data set of pins to render on the map, you could even compile the icons into a single sprite map to reduce network overhead. This means the image file is loaded once to the client, and then the map “cuts out” bits of the sprite map to render the marker icons. This can be done by setting just a few attributes of the marker’s Icon object. I haven’t tried it myself yet, but this tool looks like it would be useful for this purpose.
Loading Large Datasets
This release adds the Show Spinner and the Rows Per Batch attributes. These attributes are independent of each other, and they help to improve the quality of the experience for your end users when you are rendering a large number of pins on the map.
By default, new maps will have Show Spinner set on. For any existing maps, after upgrading you can turn this option on by setting it in the plugin attributes. This option causes the map to show the default APEX spinner while the data is loaded. The spinner is then removed when the last marker has been rendered. The effect is to give the user an indication that the map is “working”, and gives them immediate feedback when the data has finished loading and they may now interact with the map.
If the spinner seems to stay forever, it may indicate an issue with connectivity to the server (or perhaps that the server is under severe load or has stopped responding to requests).
When the APEX page has been rendered on the client, the Google Map is shown but the data is not immediately loaded; instead, a separate AJAX request is sent to the server to run your query and download all the data to render the pins on the map. By default, this is all done in one single AJAX call, which is the fastest way to get from start to finish; the downside is that the user will not see any pins on the map until all the data has been downloaded. You can change this behaviour by setting Rows Per Batch to some number (e.g. 1000). With this attribute set, the plugin will send a series of AJAX calls to the database (one at a time) and get a batch of records at a time. After loading a batch, the plugin will render the pins on the map (and if necessary, it will pan / zoom the map to show them all) and then send another AJAX request to get the next batch. When it has finished receiving all the batches, it adds any finishing touches needed (e.g. for a visualisation) and returns control to the user.
The advantage of this approach is that the user can see the pins being shown gradually, and they will know that “something is working”. This may help to give them a nicer user experience.
The downside of this approach is that it may cause a bigger load on the server (because each AJAX request requires running a new query, with an offset) and will usually take longer from start to finish. Generally, if your data comprises only a few hundred records at most, you will probably want to leave the Rows Per Batch setting blank.
The Future
There are still a few little enhancements on my “todo” list, but I’m keen to hear how you are using (or perhaps planning to use) this plugin, and if there are any new features or improvements that you need or want. If so, please raise them on the GitHub Issues page.
Quite a few people have raised questions or ideas in the past and sometimes I’ve incorporated them straight away, and other times it’s taken a little longer but I get there eventually. If you’re keen to contribute, feel free to have a poke around in the code and perhaps even do a pull request on the GitHub source to suggest a change. It would be great to collaborate with you because everyone has something unique to offer.
Long-term, I’m watching with interest the future direction of Oracle APEX. I remember at one point they were talking about incorporating some sort of new map region into the product, although the mention of this seems to have been dropped from the Statement of Direction (or maybe my memory is misleading me). I guess time will tell.
Oracle has updated apex.oracle.com to APEX 20.1 which includes among other features the new “Friendly URL” option. The legacy URL structure concatenated a string of parameters into a single “p” parameter, which works fine; but it can make it difficult to configure web server rules to match and rewrite URLs. Apart from the application ID or alias (the first part), all the parameters are optional; if all were specified the URL will be something like this (line breaks added for clarity):
In this example, the application alias is used (SAMPLE_DB_APP) and page alias (HOME) followed by the session ID etc. I’ve also specified the workspace (jk64) using the “c” query parameter.
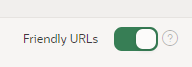
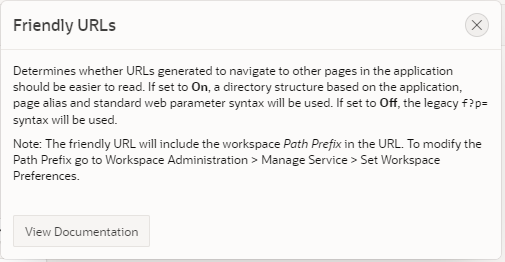
In APEX 20.1 if you edit your Application Properties, you will see the new “Friendly URLs” setting.
With this setting turned on, URLs generated throughout the application will take this form (this is not exhaustive, there are other query parameters supported as well):
When the documentation says the URLs should be “easier to read” I’m pretty sure they mean “by developers”, not end users. I suppose this means the URLs make more sense to developers of other web-based applications, because they conform better to REST URL conventions.
In its simplest form, the URL generated by APEX will include just the workspace path prefix, application, page, and session ID:
Calling APEX_PAGE.GET_URL generates the URLs correctly for the application according to whether the Friendly URL setting is on or not.
I noticed the following features of this new format:
The URL generated by APEX_PAGE.GET_URL now includes a full path (excluding the domain).
Instead of the “c” workspace query parameter, the application’s Path Prefix (which could be set to something other than the workspace name) is used (jk64 in my example). This is not the workspace name, although in most cases it usually will happen to be the same because it’s defaulted that way. This attribute is set at the workspace level, under Administration / Manage Service / Set Workspace Preferences / SQL Workshop.
If not specified, the application and page alias will be used rather than the application or page ID, which is nice.
Even if you specify the application or page alias in uppercase, APEX_PAGE.GET_URL returns them in all lowercase.
The more important attributes relevant to a user navigating the application are now further towards the start of the URL, such as page and item values, so they will be more likely to be noticed by the end user.
The “/r/” bit in the URL is just that. It’s just “r” and can’t be anything else, don’t ask me what it means. EDIT: apparently it stands for “router”…
If your users have bookmarked your application using the legacy URL format, you can still safely upgrade your application to use Friendly URLs because both are still supported. This also means that if you have some old code that generates links programmatically they should still work the same (although it is best practice to call APEX_PAGE.GET_URL for this purpose).
In case you’re wondering, it is not possible to change the URL format when calling APEX_PAGE.GET_URL, it will follow your application’s Friendly URL setting. If you call APEX_PAGE.GET_URL for another application, it will return the correct format of URL for the target application. If you call APEX_PAGE.GET_URL for an application that does not exist, it will return the URL in the legacy format.
Existing applications after upgrading, or ones you import from an older version of APEX, will still use the legacy URL syntax. New applications will use the new Friendly URLs by default – but you can revert them to the legacy URLs if you wish.
On a side note, in earlier versions when you create a new application the application alias was set to the application ID by default. In APEX 20.1, a new application will have an application alias generated from the initial application name; when I tried it, it added a number as well for some reason.
For obvious reasons, existing code that parses the URL (e.g. in javascript on the client) will probably break. This is a fairly rare thing but does happen (such as in a plugin of mine which I’ll need to fix).
At this very early stage, the legacy URL format is still fully supported – I imagine it will eventually be deprecated, but not yet.
It’s not a common requirement in my experience, but it does come up every now and then: a customer is happy with a simple Report + Form but when they open a record, they want to be able to make their changes and go to the “next” record in one button click, instead of having to go back to the report and select the other record.
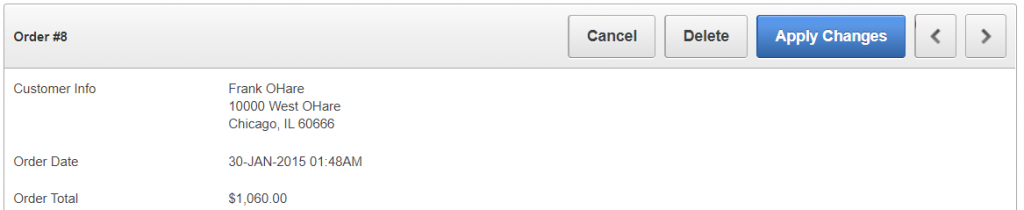
In the Sample Database Application, page 29 (Order Details) implements “Next” and “Previous” buttons which allow the user to save and open another record in one action.
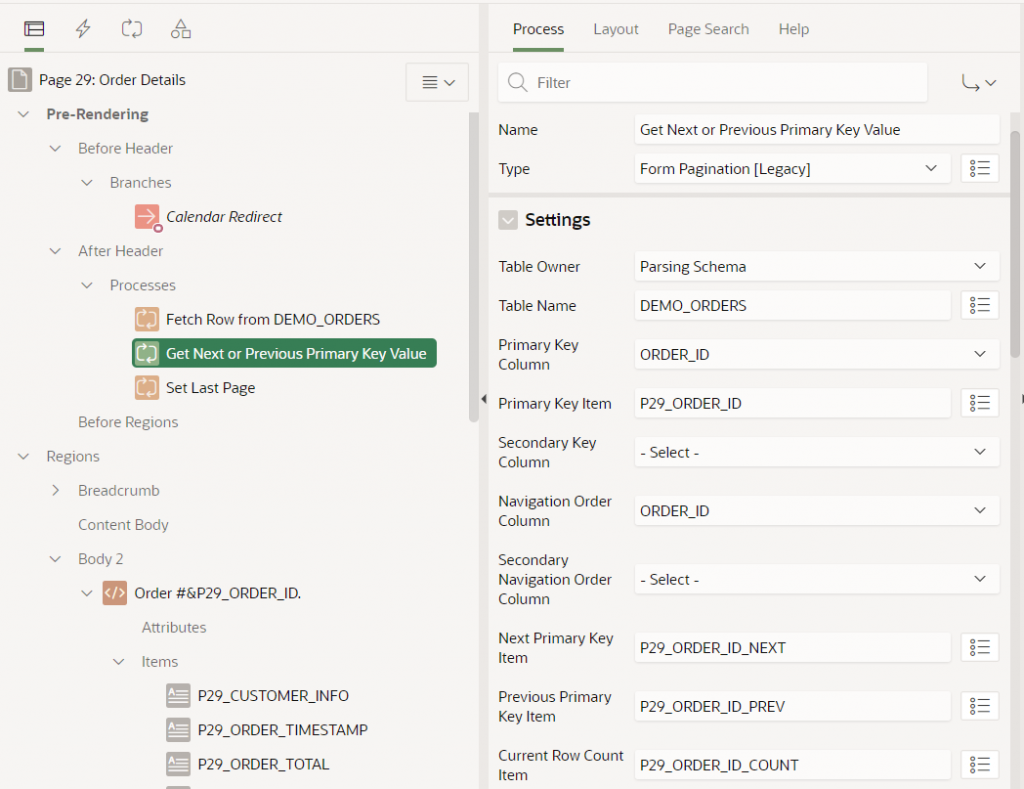
These buttons are implemented using a legacy Form Pagination process. This process sets some hidden items (P29_ORDER_ID_NEXT, P29_ORDER_ID_PREV, P29_ORDER_ID_COUNT) based on a query on a specified table (DEMO_ORDERS) with a specified unique identifier (ORDER_ID) associated with a primary key item (P29_ORDER_ID). The process requires a navigation order, specified by one or two columns (ORDER_ID, in this instance) in order to know what would the “next” and “previous” records be. If there is no next or previous record is found, the buttons are hidden.
When the page is submitted, the Next and Previous buttons submit a request (GET_NEXT_ORDER_ID or GET_PREVIOUS_ORDER_ID, respectively). After the ApplyMRU process has run, one of the relevant Branches will redirect the client back to the same page (p29) and set P29_ORDER_ID to either &P29_ORDER_ID_NEXT. or &P29_ORDER_ID_PREV. which causes the page to load the relevant record.
Some things to note with this approach:
The legacy Form Pagination process is limited to a maximum 2 columns for the uniqueness constraint, and 2 columns for the navigation order.
The navigation order of records will not match any custom sort order or filtering the user might have used on the report; so after the user opens the “first record” in the report, the form will not necessarily navigate to the “next record” that they might expect.
The Next / Previous record IDs are queried when the page is initially loaded, so if anything has changed prior to the user clicking “Next” or “Previous”, it’s possible the user will inadvertently be directed to a record that is not actually “next” or “previous” to the record as it is now. In the worst case, if someone had deleted a record, the page would show “record not found”. In a perhaps less problematic case, if someone else has just inserted a new record with a unique identifier that happens to fall between the user’s previous record and the record they are navigating to, the user will effectively “skip over” the newly inserted record and might be led to believe it doesn’t exist.
For large datasets there may be a performance penalty whenever each user loads the form since the page must issue additional queries to find the IDs for the “previous smaller” and “next larger” record, as well as to get the total number of records, and the position in the overall dataset of the current record (so it can set the “count” item to something like “8 of 10”). This involves the execution of a second query (in addition to the original query which gathered the data for the record being viewed).
These are not necessarily insurmountable or showstopping issues but should be kept in mind for forms using this approach.
With the new APEX Form feature, the above approach can still be used in much the same way – the attribute settings are a little different.
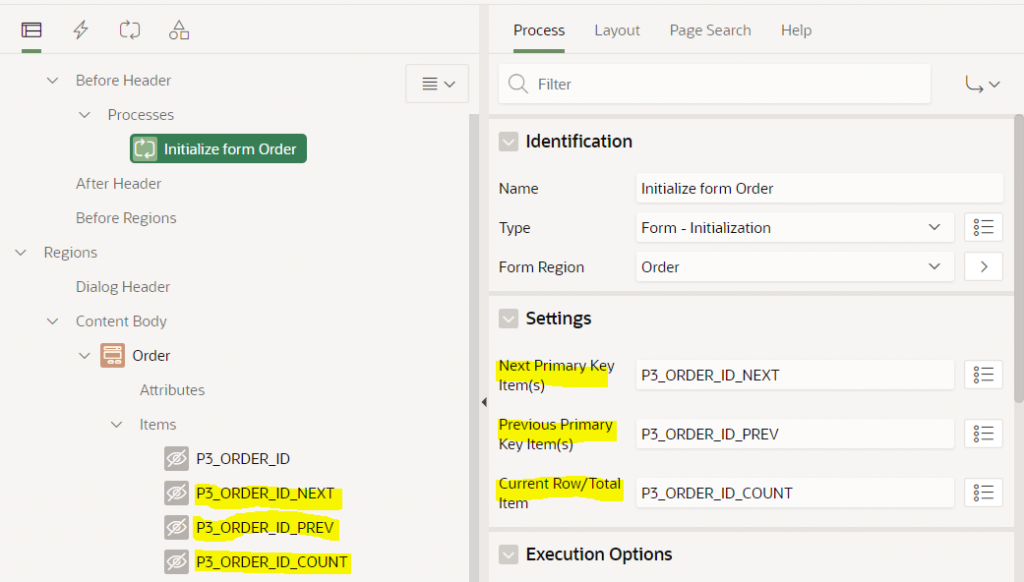
The page has a process before header of type Form – Initialization. This process has the following optional settings: Next Primary Key Item(s), Previous Primary Key Item(s), and Current Row/Total Item. To use this feature you must first create items (usually hidden) and then set these attributes to the item names.
Note that the Next / Previous Primary Key Item(s) attributes accept a comma-delimited list of items which allows them to support a compound key; I haven’t tested it but I expect this means it can support more than 2 columns.
The form will automatically populate these hidden items with the Order ID of the next and previous record, and will set the Current Row/Total Item to something like “8 of 10”. You can then use these items how you wish, e.g. as per the legacy pagination scheme, add the “Next” and “Previous” buttons, and create the navigation Branches to open the form with the relevant records.
To control the navigation order, you must set the Order By attribute on the form region. If this is not set, the navigation order is essentially unpredictable (APEX uses null as the sort order).
Same as the legacy pagination process, the form executes two queries: one to load the data for the form, and a second to gather the Next, Previous, Position and Count for the record, using SQL like this (I’ve simplified it a bit):
select i.*
from (
select ORDER_ID, CUSTOMER_ID, ORDER_TOTAL, ...
lead(ORDER_ID,1) over (order by ORDER_ID) as APX$NEXT_1,
lag(ORDER_ID,1) over (order by ORDER_ID) as APX$PREV_1,
row_number() over (order by ORDER_ID) as APX$ROWN,
count(*) over () as APX$TOTAL
from (
(select /*+ qb_name(apex$inner) */
d.ORDER_ID, d.CUSTOMER_ID, d.ORDER_TOTAL, ...
from (select x.* from DEMO_ORDERS x) d
)) i
) i where 1=1
and ORDER_ID=:apex$f1
It should be noted that the comments above about how concurrent record inserts and deletes by other users, and about report filters and sorting, also apply to the new form process.
In the past I built a system where it was important that the “Next” / “Previous” buttons should allow the user to navigate up and down the records exactly as shown in the report, respecting user-entered filters and sort order. The approach I took was to gather the IDs into a collection and pass this to the form when the user opened a record. I described the implementation and limitations of this approach in an older blog post which I expect still works today: Next/Previous buttons from Interactive Report results
If you have an Interactive Report with the Subscription feature enabled, users can “subscribe” to the report, getting a daily email with the results of the report. Unfortunately, however, this feature doesn’t work as expected if it relies on session state – e.g. if the query uses bind variables based on page items to filter the records. In this case, the subscription will run the query with a default (null) session state – APEX doesn’t remember what the page item values were when the user subscribed to the report.
The job that runs subscriptions, first sets the APEX globals (e.g. app ID, page ID) and evaluates any relevant authorizations (to check that the user still has access to the app, page and region); apart from that, only the query for the region is actually executed. Page processes are not executed, and page items with default values or expressions are not set and will be considered null if referred to by the query. In some cases you may be able to workaround this by using NVL or COALESCE in your query to handle null page items.
This is a query I used to quickly pick out all the Interactive Reports that have the Subscription feature enabled but which might rely on session state to work – i.e. it relies on items submitted from the page, refers to a bind variable or to a system context:
select workspace, application_id, application_name,
page_id, region_name, page_items_to_submit
from apex_application_page_ir
where show_notify = 'Yes'
and (page_items_to_submit is not null
or regexp_like(sql_query,':[A-Z]','i')
or regexp_like(sql_query,'SYS_CONTEXT','i')
);
For these reports, I reviewed them and where appropriate, turned off the Subscription feature. Note that this query is not perfect and might give some false positives and negatives.
As of APEX 20.1, when a subscription is saved, the session is cloned, and the clone is used for all subsequent daily emails of the report. What this effectively means it that a snapshot of the value of each item in the application is taken (i.e. the value as stored in session state on the database) and this snapshot will provide values for any items used by the report.
In addition, the Database Session Initialization PL/SQL Code (under Security Attributes) is also executed, which is how you can initialise any application contexts that the report might need (e.g. for VPD).
Note that if the report relied on any APEX collections, these are not included in the clone; but reports that are based on collections should not generally be enabled for email subscriptions anyway.