715175039885776956103287888080
I needed to generate a random string with an exact length consisting of numeric digits, that I could send in an SMS to a user as a temporary account “pin”. DBMS_RANDOM.string is unsuitable for this purpose as its supported modes all include alphabetic characters. So I used DBMS_RANDOM.value instead. I call TRUNC afterwards to lop off the decimal portion.
FUNCTION random_pin (digits IN NUMBER)
RETURN NUMBER IS
BEGIN
IF digits IS NULL OR digits < 1 OR digits > 39 THEN
RAISE_APPLICATION_ERROR(-20000,'digits must be 1..39');
END IF;
IF digits = 1 THEN
RETURN TRUNC( DBMS_RANDOM.value(0,10) );
ELSE
RETURN TRUNC( DBMS_RANDOM.value(
POWER(10, digits-1)
,POWER(10, digits) ));
END IF;
END random_pin;
random_pin(digits => 6);
482372
EDIT 8/1/2016: added special case for 1 digit
ADDENDUM
Because the requirements of my “pin” function was to return a value that would remain unchanged when represented as an integer, it cannot return a string of digits starting with any zeros, which is why the lowerbound for the random function is POWER(10,digits-1). This, unfortunately, makes it somewhat less than perfectly random because zeroes are less frequent – if you call this function 1000 times for a given length of digits, then counted the frequency of each digit from 0..9, you will notice that 0 has a small but significantly lower frequency than the digits 1 to 9.
To fix this, the following function returns a random string of digits, with equal chance of returning a string starting with one or more zeroes:
FUNCTION random_digits (digits IN NUMBER)
RETURN VARCHAR2 IS
BEGIN
IF digits IS NULL OR digits < 1 OR digits > 39 THEN
RAISE_APPLICATION_ERROR(-20000,'digits must be 1..39');
END IF;
RETURN LPAD( TRUNC(
DBMS_RANDOM.value(0, POWER(10, digits))
), digits, '0');
END random_digits;
The above functions may be tested and downloaded from Oracle Live SQL.
 Just a quick note that (as mentioned by Christian Neumueller earlier) APEX 5 now populates an Application Context
Just a quick note that (as mentioned by Christian Neumueller earlier) APEX 5 now populates an Application Context APEX$SESSION with the session’s User, Session ID and Workspace ID:
SYS_CONTEXT('APEX$SESSION','APP_USER')
SYS_CONTEXT('APEX$SESSION','APP_SESSION')
SYS_CONTEXT('APEX$SESSION','WORKSPACE_ID')
Using the above should be faster in your queries than calling v() to get these values. Note that the alias 'SESSION' won’t work like it does with v().
The context is managed by the database package APEX_050000.WWV_FLOW_SESSION_CONTEXT which is an undocumented API used internally by APEX to synchronize the context with the associated APEX attibutes. Incidentally, the comments in the package indicate it was authored by Chris himself.
Personally I was hoping that a bit more of the session state would be replicated in the context, e.g. application ID, page ID, request, debug mode, application items and page items.
Sidebar: to see all contexts that are visible to your session, query ALL_CONTEXT. To see all context values set in your session, query SESSION_CONTEXT. Of course, don’t query these in your application code to get individual values – that’s what the SYS_CONTEXT function is for.
You have a Select List item on your page driven from a dynamic query, e.g. one that only shows valid values. One day, users notice that the list appears empty and raise a defect note.

You check the query behind the list and verify that indeed, the list should be empty because there are no valid values to show. It’s an optional item so the user is free to save the record if they wish.
There are a number of ways we could make this more user-friendly: depending on the specifics of the situation, we might just hide the item, or we might want to show an alternative item or a warning message. We can do any of these things quite easily using either a computation on page load (if the list doesn’t change while the page is open) or a dynamic action.
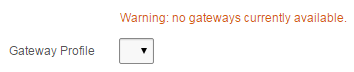
In the case of my client, they wanted the item to remain on screen, but to show an orange warning message to let them know that there are no gateways currently available; this is only a warning because there are subsequent processes that can handle the missing gateway (e.g. a higher-privileged user can assign a “hidden” gateway to the record if they deem it suitable).
To do this we create a display item (e.g. “P1_NO_GATEWAY_WARNING” which shows the warning message) and a dynamic action with the following attributes:
- Event = Page Load
- Condition = JavaScript expression
- Value =
listIsEmpty("P1_GATEWAY_ID")
- True Action = Set Value
- Set Type = Static Assignment
- Value = Warning: no gateways currently available
- Selection Type = Item(s)
- Item(s) = P1_NO_GATEWAY_WARNING
In the page’s Function and Global Variable Declaration, or (even better) in the application’s global javascript file, we add the following:
function listIsEmpty(itemName) {
return $("#" + itemName + " option:enabled").filter(
function(){return this.text;}
).length==0;
}
This was adapted from some solutions here. It looks for all <option>s under the item, filters the list for options which are not disabled and have a label, and returns true if the remaining set is empty. I added the this.text bit because the empty lists generated by Apex include a single empty option for the “NULL” value. This is because I have set the list item’s Null Display Value to blank (null).
Quite a long time ago I made a collection of MP3s available from our APEX website and made them playable within the browser using Google’s shockwave player, using code like this:
<embed type="application/x-shockwave-flash"
flashvars="audioUrl=#FILE_URL#"
src="/3523697345-audio-player.swf"
width="400"
height="27"
quality="best">
</embed>
This relies on the user’s browser being able to run flash applications. It looked like this:

With HTML5, however, this is no longer required, so I’ve updated it to:
<audio controls preload>
<source src="#FILE_URL#" type="audio/mpeg">
</audio>
Not only is it simpler and no longer requires flash, it looks much nicer as well:

Note: you may or may not want to include the preload tag, especially if you have more than one audio control on a page.
Yesterday I published a SQL problem (that I I had solved – or at least, thought I had solved!) and invited readers to submit their own solutions.
SPOILER ALERT: if you haven’t had a chance to have a go yourself, go back, don’t read the comments (yet), but see if you can solve it yourself.
I was very pleased to see two excellent submissions that were both correct as far as I could tell, and are (in my opinion) sufficiently simple, elegant and efficient. Note that this was not a competition and I will not be ranking or rating or anything like that. If you need to solve a similar problem, I would suggest you try all of these solutions out and pick the one that seems to work the best for you.
Solution #1
Stew Ashton supplied the first solution which was very simple and elegant:
with dates as (
select distinct deptid, dte from (
select deptid, from_date, to_date+1 to_date from t1
union all
select deptid, from_date, to_date+1 to_date from t2
)
unpivot(dte for col in(from_date, to_date))
)
select * from (
select distinct a.deptid, dte from_date,
lead(dte) over(partition by a.deptid order by dte) - 1 to_date,
data1, data2 from dates a
left join t1 b on a.deptid = b.deptid and a.dte between b.from_date and b.to_date
left join t2 c on a.deptid = c.deptid and a.dte between c.from_date and c.to_date
)
where data1 is not null or data2 is not null
order by 1,2;
SQL Fiddle
Stew’s solution does a quick pass over the two tables and generates a “date dimension” table in memory; it then does left joins to each table to generate each row. It may have a disadvantage due to the requirement to make two passes over the tables, which might be mitigated by suitable indexing. As pointed out by Matthias Rogel, this solution can be easily generalised to more than two tables, which is a plus.
Solution #2
The second solution was provided by Kim Berg Hansen which was a bit longer but in my opinion, still simple and elegant:
with v1 as (
select t.deptid
, case r.l
when 1 then t.from_date
when 2 then date '0001-01-01'
when 3 then t.max_to + 1
end from_date
, case r.l
when 1 then t.to_date
when 2 then t.min_from -1
when 3 then date '9999-01-01'
end to_date
, case r.l
when 1 then t.data1
end data1
from (
select deptid
, from_date
, to_date
, data1
, row_number() over (partition by deptid order by from_date) rn
, min(from_date) over (partition by deptid) min_from
, max(to_date) over (partition by deptid) max_to
from t1
) t, lateral(
select level l
from dual
connect by level <= case t.rn when 1 then 3 else 1 end
) r
), v2 as (
select t.deptid
, case r.l
when 1 then t.from_date
when 2 then date '0001-01-01'
when 3 then t.max_to + 1
end from_date
, case r.l
when 1 then t.to_date
when 2 then t.min_from -1
when 3 then date '9999-01-01'
end to_date
, case r.l
when 1 then t.data2
end data2
from (
select deptid
, from_date
, to_date
, data2
, row_number() over (partition by deptid order by from_date) rn
, min(from_date) over (partition by deptid) min_from
, max(to_date) over (partition by deptid) max_to
from t2
) t, lateral(
select level l
from dual
connect by level <= case t.rn when 1 then 3 else 1 end
) r
)
select v1.deptid
, greatest(v1.from_date, v2.from_date) from_date
, least(v1.to_date, v2.to_date) to_date
, v1.data1
, v2.data2
from v1
join v2
on v2.deptid = v1.deptid
and v2.to_date >= v1.from_date
and v2.from_date <= v1.to_date
where v2.data2 is not null or v1.data1 is not null
order by v1.deptid
, greatest(v1.from_date, v2.from_date)
Since it takes advantage of 12c’s new LATERAL feature, I wasn’t able to test it on my system, but I was able to test it on Oracle’s new Live SQL and it passed with flying colours. I backported it to 11g and it worked just fine on my system as well. An advantage of Kim’s solution is that it should only make one pass over each of the two tables.
Oracle Live SQL: merge-history-kimberghansen (this is the 12c version – Oracle login required)
SQL Fiddle (this is my attempt to backport to 11g – you can judge for yourself if I was faithful to the original)
Solution #3
When my colleague came to me with this problem, I started by creating a test suite including as many test cases as we could think of. Developing and testing the solution against these test cases proved invaluable and allowed a number of ideas to be tested and thrown away. Big thanks go to Kim Berg Hansen for providing an additional test case, which revealed a small bug in my original solution.
with q1 as (
select nvl(t1.deptid, t2.deptid) as deptid
,greatest(nvl(t1.from_date, t2.from_date), nvl(t2.from_date, t1.from_date)) as gt_from_date
,least(nvl(t1.to_date, t2.to_date), nvl(t2.to_date, t1.to_date)) as lt_to_date
,t1.from_date AS t1_from_date
,t1.to_date AS t1_to_date
,t2.from_date AS t2_from_date
,t2.to_date AS t2_to_date
,min(greatest(t1.from_date, t2.from_date)) over (partition by t1.deptid) - 1 as fr_to_date
,max(least(t1.to_date, t2.to_date)) over (partition by t2.deptid) + 1 as lr_from_date
,t1.data1
,t2.data2
,row_number() over (partition by t1.deptid, t2.deptid order by t1.from_date) as rn_fr1
,row_number() over (partition by t1.deptid, t2.deptid order by t2.from_date) as rn_fr2
,row_number() over (partition by t1.deptid, t2.deptid order by t1.to_date desc) as rn_lr1
,row_number() over (partition by t1.deptid, t2.deptid order by t2.to_date desc) as rn_lr2
from t1
full outer join t2
on t1.deptid = t2.deptid
and (t1.from_date between t2.from_date and t2.to_date
or t1.to_date between t2.from_date and t2.to_date
or t2.from_date between t1.from_date and t1.to_date
or t2.to_date between t1.from_date and t1.to_date)
order by 1, 2
)
select deptid
,gt_from_date AS from_date
,lt_to_date AS to_date
,data1
,data2
from q1
union all
select deptid
,t1_from_date as from_date
,fr_to_date AS to_date
,data1
,'' AS data2
from q1
where fr_to_date between t1_from_date and t1_to_date
and rn_fr1 = 1
union all
select deptid
,t2_from_date as from_date
,fr_to_date AS to_date
,'' AS data1
,data2
from q1
where fr_to_date between t2_from_date and t2_to_date
and rn_fr2 = 1
union all
select deptid
,lr_from_date as from_date
,t2_to_date AS to_date
,'' AS data1
,data2
from q1
where lr_from_date between t2_from_date and t2_to_date
and rn_lr2 = 1
union all
select deptid
,lr_from_date as from_date
,t1_to_date AS to_date
,data1
,'' AS data2
from q1
where lr_from_date between t1_from_date and t1_to_date
and rn_lr1 = 1
order by deptid, from_date
SQL Fiddle
This solution is probably the ugliest of the three, and though it only requires one pass over the two tables, it materializes all the data in a temp table so probably requires a fair amount of memory for large data sets.
I’m so glad I posted this problem – I received help in the form of two quite different solutions, which help to show different ways of approaching problems like this. Not only that, but it highlighted the value of test-driven development – instead of groping in the dark to come up with a quick-and-dirty solution (that might or might not work), starting with comprehensive test cases is invaluable for both developing and validating potential solutions.
A colleague asked me if I could help solve a problem in SQL, and I was grateful because I love solving problems in SQL! So we sat down, built a test suite, and worked together to solve it.
I will first present the problem and invite you to have a go at solving it for yourself; tomorrow I will post the solution we came up with. I think our solution is reasonably simple and elegant, but I’m certain there are other solutions as well, some of which may be more elegant or efficient.
I have two “record history” tables, from different data sources, that record the history of changes to two sets of columns describing the same entity. Here are the example tables:
T1 (deptid, from_date, to_date, data1)
T2 (deptid, from_date, to_date, data2)
So T1 records the changes in the column “data1” over time for each deptid; and T2 records the changes in the column “data2” over time for each deptid.
Assumptions/Constraints on T1 and T2:
- All columns are not Null.
- All dates are just dates (no time values).
- All date ranges are valid (i.e. from_date <- to_date).
- Within each table, all date ranges for a particular deptid are gap-free and have no overlaps.
We want to produce a query that returns the following structure:
T3 (deptid, from_date, to_date, data1, data2)
Where the dates for a particular deptid overlap between T1 and T2, we want to see the corresponding data1 and data2 values. Where the dates do not overlap (e.g. where we have a value for data1 in T1 but not in T2), we want to see the corresponding data1 but NULL for data2; and vice versa.
Below is the setup and test cases you can use if you wish. Alternatively, you can use the SQL Fiddle here.
create table t1
(deptid number not null
,from_date date not null
,to_date date not null
,data1 varchar2(30) not null
,primary key (deptid, from_date)
);
create table t2
(deptid number not null
,from_date date not null
,to_date date not null
,data2 varchar2(30) not null
,primary key (deptid, from_date)
);
--Test Case 1 (4001)
--T1 |-------------||-------------|
--T2 |-------------||-------------||-------------|
insert into t1 values (4001, date'2015-01-01', date'2015-01-31', 'jan data 1');
insert into t1 values (4001, date'2015-02-01', date'2015-02-28', 'feb data 1');
insert into t2 values (4001, date'2015-01-15', date'2015-02-14', 'jan-feb data 2');
insert into t2 values (4001, date'2015-02-15', date'2015-03-14', 'feb-mar data 2');
insert into t2 values (4001, date'2015-03-15', date'2015-04-14', 'mar-apr data 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4001 01-JAN-2015 14-JAN-2015 jan data 1
--4001 15-JAN-2015 31-JAN-2015 jan data 1 jan-feb data 2
--4001 01-FEB-2015 14-FEB-2015 feb data 1 jan-feb data 2
--4001 15-FEB-2015 28-FEB-2015 feb data 1 feb-mar data 2
--4001 01-MAR-2015 14-MAR-2015 feb-mar data 2
--4001 15-MAR-2015 14-APR-2015 mar-apr data 2
--Test Case 2 (4002)
--T1 |-------------||-------------||-------------|
--T2 |-------------||-------------|
insert into t1 values (4002, date'2015-01-15', date'2015-02-14', 'jan-feb data 1');
insert into t1 values (4002, date'2015-02-15', date'2015-03-14', 'feb-mar data 1');
insert into t1 values (4002, date'2015-03-15', date'2015-04-14', 'mar-apr data 1');
insert into t2 values (4002, date'2015-01-01', date'2015-01-31', 'jan data 2');
insert into t2 values (4002, date'2015-02-01', date'2015-02-28', 'feb data 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4002 01-JAN-2015 14-JAN-2015 jan data 2
--4002 15-JAN-2015 31-JAN-2015 jan-feb data 1 jan data 2
--4002 01-FEB-2015 14-FEB-2015 jan-feb data 1 feb data 2
--4002 15-FEB-2015 28-FEB-2015 feb-mar data 1 feb data 2
--4002 01-MAR-2015 14-MAR-2015 feb-mar data 1
--4002 15-MAR-2015 14-APR-2015 mar-apr data 1
--Test Case 3 (4003)
--T1 |-------------|
--T2 |-------------|
insert into t1 values (4003, date'2015-01-01', date'2015-01-31', 'jan data 1');
insert into t2 values (4003, date'2015-01-01', date'2015-01-31', 'jan data 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4003 01-JAN-2015 31-JAN-2015 jan data 1 jan data 2
--Test Case 4 (4004)
--T1 |-------------|
--T2 |-----|
insert into t1 values (4004, date'2015-01-01', date'2015-01-31', 'jan data 1');
insert into t2 values (4004, date'2015-01-10', date'2015-01-20', 'jan data int 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4004 01-JAN-2015 09-JAN-2015 jan data 1
--4004 10-JAN-2015 20-JAN-2015 jan data 1 jan data int 2
--4004 21-JAN-2015 31-JAN-2015 jan data 1
--Test Case 5 (4005)
--T1 |-----|
--T2 |-------------|
insert into t1 values (4005, date'2015-01-10', date'2015-01-20', 'jan data int 1');
insert into t2 values (4005, date'2015-01-01', date'2015-01-31', 'jan data 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4005 01-JAN-2015 09-JAN-2015 jan data 2
--4005 10-JAN-2015 20-JAN-2015 jan data int 1 jan data 2
--4005 21-JAN-2015 31-JAN-2015 jan data 2
--Test Case 6 (4006)
--T1 ||------------|
--T2 |-------------|
insert into t1 values (4006, date'2015-01-01', date'2015-01-01', 'jan data a 1');
insert into t1 values (4006, date'2015-01-02', date'2015-01-31', 'jan data b 1');
insert into t2 values (4006, date'2015-01-01', date'2015-01-31', 'jan data 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4006 01-JAN-2015 01-JAN-2015 jan data a 1 jan data 2
--4006 02-JAN-2015 31-JAN-2015 jan data b 1 jan data 2
--Test Case 7 (4007)
--T1 |-------------|
--T2 ||------------|
insert into t1 values (4007, date'2015-01-01', date'2015-01-31', 'jan data 1');
insert into t2 values (4007, date'2015-01-01', date'2015-01-01', 'jan data a 2');
insert into t2 values (4007, date'2015-01-02', date'2015-01-31', 'jan data b 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4007 01-JAN-2015 01-JAN-2015 jan data 1 jan data a 2
--4007 02-JAN-2015 31-JAN-2015 jan data 1 jan data b 2
--Test Case 8 (4008)
--T1 |-------------|
--T2 |---||---||---|
insert into t1 values (4008, date'2015-01-01', date'2015-01-31', 'jan data 1');
insert into t2 values (4008, date'2015-01-09', date'2015-01-17', 'jan data a 2');
insert into t2 values (4008, date'2015-01-18', date'2015-01-26', 'jan data b 2');
insert into t2 values (4008, date'2015-01-27', date'2015-02-04', 'jan-feb data 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4008 01-JAN-2015 08-JAN-2015 jan data 1
--4008 09-JAN-2015 17-JAN-2015 jan data 1 jan data a 2
--4008 18-JAN-2015 26-JAN-2015 jan data 1 jan data b 2
--4008 27-JAN-2015 31-JAN-2015 jan data 1 jan-feb data 2
--4008 01-FEB-2015 04-FEB-2015 jan-feb data 2
--Test Case 9 (4009)
--T1 |---||---||---|
--T2 |-------------|
insert into t1 values (4009, date'2015-01-09', date'2015-01-17', 'jan data a 1');
insert into t1 values (4009, date'2015-01-18', date'2015-01-26', 'jan data b 1');
insert into t1 values (4009, date'2015-01-27', date'2015-02-04', 'jan-feb data 1');
insert into t2 values (4009, date'2015-01-01', date'2015-01-31', 'jan data 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4009 01-JAN-2015 08-JAN-2015 jan data 2
--4009 09-JAN-2015 17-JAN-2015 jan data a 1 jan data 2
--4009 18-JAN-2015 26-JAN-2015 jan data b 1 jan data 2
--4009 27-JAN-2015 31-JAN-2015 jan-feb data 1 jan data 2
--4009 01-FEB-2015 04-FEB-2015 jan-feb data 1
EDIT 15/10/2015: added Kim Berg Hansen’s test cases
UPDATE 15/10/2015: solutions (spoiler alert!)
This is just a quick note for my future reference. I needed all items with the class “uppercase” to be converted to uppercase, and I thought it would work with just some CSS:
.uppercase { text-transform: uppercase; }
This makes the items appear uppercase, but when the page is posted it actually sends the values exactly as the user typed. They’d type in “lower“, it looks like “LOWER” on screen, but gets posted as “lower“.
In many cases I could just convert the value in my PL/SQL code, but in cases where I was using APEX tabular forms, I don’t know a simple way to intercept the values before the insert occurs.
To solve this I added this to the page’s Execute when Page Loads:
//the item looks uppercase but the internal value is still lowercase
$(document).on('change', '.uppercase', function() {
var i = "#" + $(this).attr("id");
$(i).val( $(i).val().toUpperCase() );
});
Or, even better, add this to the application’s global javascript file:
$(document).ready( function() {
$(document).on('change', '.uppercase', function() {
var i = "#" + $(this).attr("id");
$(i).val( $(i).val().toUpperCase() );
});
});
UPDATE: Interactive Grids
For interactive grids, you can still use this method. Put the class uppercase in the Advanced / CSS Classes attribute (Note: this is different to the Appearance / CSS Classes attribute!). I would also set the Column Filter / Text Case to Upper for good measure.
Most places I’ve worked at allow employees to use any of the major browsers to do their work, but mandate an “SOE” that only supports IE, presumably because that generates the most amount of work for us developers. I’d conservatively estimate that 99% of the rendering bugs I’ve had to deal with are only reproducible in IE. (cue one of the thousands of IE joke images… nah, just do a Google Image search, there’s plenty!)
Anyway, we had a number of these rendering issues in Apex on IE8, IE9 and IE10, mainly in edge cases involving some custom CSS or plugins. In some cases I was never able to reproduce the issue until we noticed that the user had inadvertently switched “IE Compatility Mode” on:

We told them to make sure the icon was grey, like this:

– and most of the issues went away.
Since there’s nothing in our Apex application that requires compatibility mode, we would rather the option not be available at all. To this end, we simply add this code to all the Page templates in the application:
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
This is added just after the <head> tag, like this:
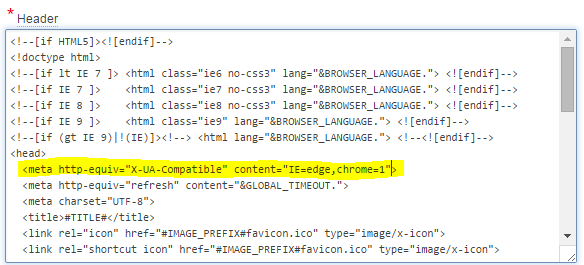
Now, the compatibility button doesn’t appear at all – one less choice for users and less bug reports to deal with:

For more information, see this stackoverflow question and read all the answers. Note that it may be better to add this as a header in the response generated by your web server. In our case it was simpler to just add it into the html.

I’ve added this script to our toolbelt for future upgrades. We have a friendly “System is under maintenance, sorry for any convenience” web page that we want to show to users while we run upgrades, and we want it to be shown even if we’re just doing some database schema changes.
So I took the script from here and adapted it slightly, here’s our version:
declare PRAGMA AUTONOMOUS_TRANSACTION;
v_workspace CONSTANT VARCHAR2(100) := 'MYSCHEMA';
v_workspace_id NUMBER;
begin
select workspace_id into v_workspace_id
from apex_workspaces where workspace = v_workspace;
apex_application_install.set_workspace_id (v_workspace_id);
apex_util.set_security_group_id
(p_security_group_id => apex_application_install.get_workspace_id);
wwv_flow_api.set_flow_status
(p_flow_id => 100
,p_flow_status => 'UNAVAILABLE_URL'
,p_flow_status_message => 'http://www.example.com/system_unavailable.html'
);
commit;
end;
/
It uses an autonomous transaction because we want the system to be unavailable immediately for all users while the deployment is running.
Warning: WWV_FLOW_API is an undocumented package so this is not supported.
The opposite script to make the application available again is:
declare PRAGMA AUTONOMOUS_TRANSACTION;
v_workspace CONSTANT VARCHAR2(100) := 'MYSCHEMA';
v_workspace_id NUMBER;
begin
select workspace_id into v_workspace_id
from apex_workspaces where workspace = v_workspace;
apex_application_install.set_workspace_id (v_workspace_id);
apex_util.set_security_group_id
(p_security_group_id => apex_application_install.get_workspace_id);
wwv_flow_api.set_flow_status
(p_flow_id => 100
,p_flow_status => 'AVAILABLE'
);
commit;
end;
/
However, if we run the f100.sql script to deploy a new version of the application, we don’t need to run the “set available” script since the redeployment of the application (which would have been exported in an “available” state already) will effectively make it available straight away.
UPDATE FOR APEX 5.1 and later
The APEX API has been updated with a documented and supported call – APEX_UTIL.set_application_status to do this which should be used in APEX 5.1 or later.
You’ve finished the design for an Apex application, and the manager asks you “when will you have it ready to test”. You resist the temptation to respond snarkily “how long is a piece of string” – which, by the way, is often the only appropriate answer if they ask for an estimate before the design work has started.

Since you have a design and a clear idea of what exactly this application will do, you can build a reasonable estimate of development time. The starting point is to break down the design into small chunks of discrete modules of work, where each chunk is something you can realistically estimate to take between half a day up to a maximum of three days. In cases where it’s something you haven’t done before, you can reduce uncertainty by creating a small Proof-of-Concept application or code snippet and seeing how the abstract ideas in the design might work in reality. This is where Apex comes in handy – by the time the design has completed, you’ll have a database schema (you created the schema in a tool like SQL Developer, didn’t you – so you can generate the DDL for that in a jiffy) and you can just point Apex to that and use the New Application wizard to create a simple application.
I plan all my projects using Trello, recording estimates using the Scrum for Trello extension. I don’t know much about the “Scrum” method but this extension allows me to assign “points” to each task (blue numbers on each card, with a total at the top of each list). I used to use a 1 point = 1 day (8 hours) convention, but I was finding most of the tasks were more fine grained (I was assigning 0.5 and 0.25 points to most tasks) so I’ve now switched to a convention of 1 point = 1 hour (more or less). In other words, I’d report my estimates with the assumption that my “velocity” would be 8 points per day.
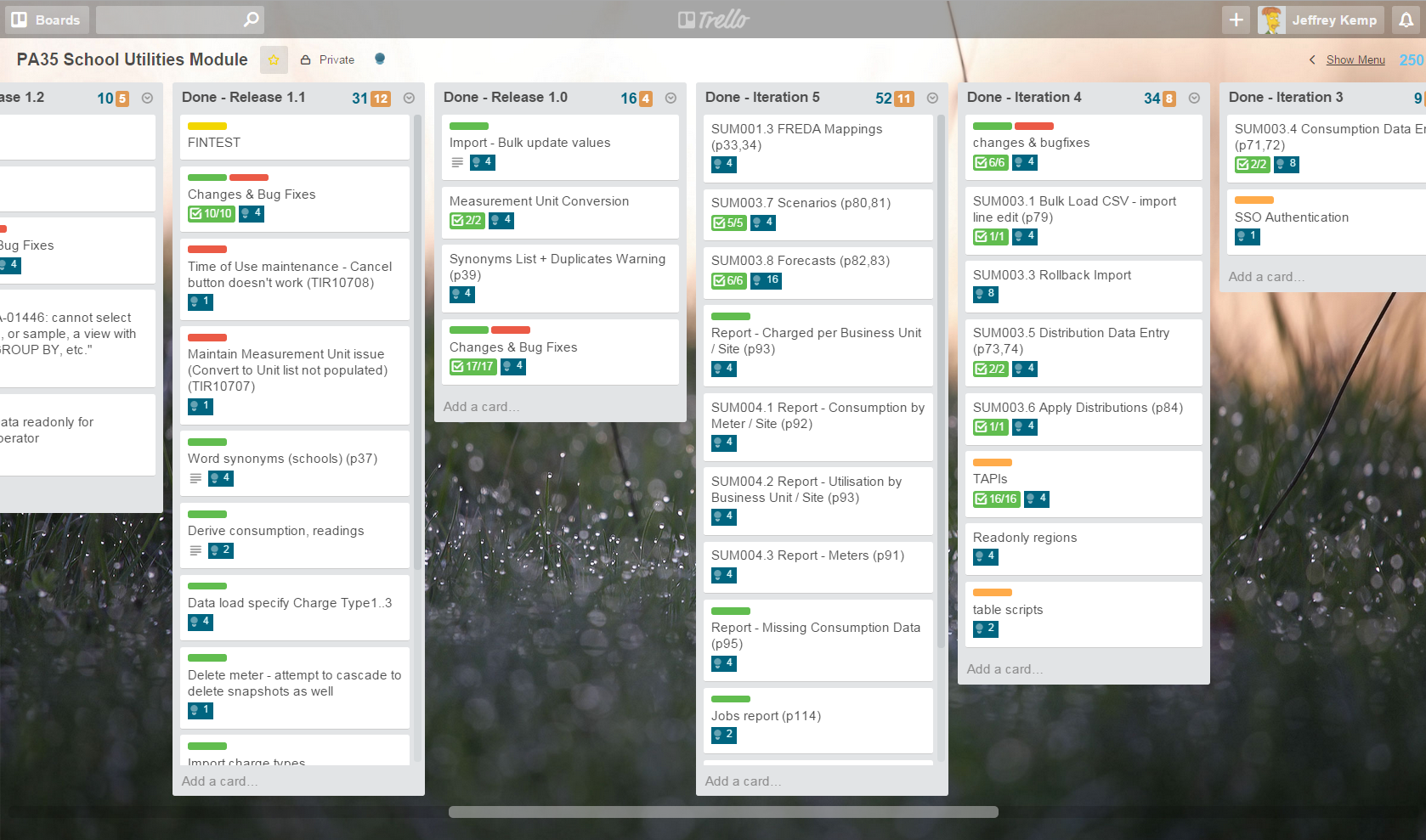
(note: the blue numbers are the Scrum for Trello points, and the orange numbers are simply the number of cards in the list)
My points system looks roughly like this:
- Simple report, form or process = 4 points
- Complex report or form or process = 8 points
- Very complex form or process = 24 points
- Simple bug fix / tweak = 1 point
- Complex bug fix / enhancement = 2 to 8 points depending on complexity
In addition to that, I keep a daily diary of work done in Evernote which has allowed me to do what I’ve wanted to do for a while now: measure my actuals vs. estimates for my projects, in order to calibrate my estimates for future projects. I made up a quick spreadsheet showing the development work for two projects, showing the original estimate, the start and finish dates, and actual development days worked (accurate roughly to the nearest half day, not counting non-development time like meetings and other project work). This allows me to see how my actual development time compares to my original estimates.
SAM Development (16 Jun 2014 to 11 Dec 2014):
- Estimate: 715 points (“18 weeks”)
- Actual: 103.5 days (21 weeks)
- Avg. points per day (“velocity”): 6.9
SAM Support (12 Dec 2014 to 29 Jul 2015):
- Estimate: 460 points (“12 weeks”)
- Actual: 64.5 days (13 weeks)
- Avg. points per day (“velocity”): 7.1
SUM Development (4 Jun 2015 to present):
- Estimate: 238 points (“6 weeks”)
- Actual: 31 days (6 weeks)
- Avg. points per day (“velocity”): 7.7
Details: EstimatesCalibration.xlsx
Since my reported estimates were roughly 8 points = 1 day, it seems I tend to underestimate. It may seem that my estimates are getting better (since my Points per Day is approaching 8), but that trend is more likely a result of SUM involving a lot less uncertainty and risk and being a smaller project overall. SAM was in a new environment and new client, whereas SUM is merely an additional application in the same environment for the same client. I was also able to re-use or adapt a lot of infrastructure-type code and Apex components from SAM in SUM.
The other thing that I can see from the details is that my “velocity” (points per day) is higher in the earlier stages of development, probably because I have plenty of work planned out, and I can work for several days in a row, uninterrupted by meetings and other distractions. In later stages, my attention gets divided by bug fixes, enhancement requests, meetings, doing design work for the next project, and general waiting-for-other-people-to-do-their-jobs.
For my next project I’ll estimate using the same points system as above, but factor in a 7 points-per-day to the estimates that I report.
Do you have a system of your own you use to create estimates and measure their accuracy? If not, why not try this for yourself? Do you keep track of your estimates and progress? If not, I recommend you start 🙂

