I’ve been aware of some of the ways that Oracle database optimises index accesses for queries, but I’m also aware that you have to test each critical query to ensure that the expected optimisations are taking effect.
I had this simple query, the requirement of which is to get the “previous status” for a record from a journal table. Since the journal table records all inserts, updates and deletes, and this query is called immediately after an update, to get the previous status we need to query the journal for the record most recently prior to the most recent record. Since the “version_id” column is incremented for each update, we can use that as the sort order.
select status_code
from (select rownum rn, status_code
from xxtim_requests$jn jn
where jn.trq_id = :trq_id
order by version_id desc)
where rn = 2;
The xxtim_requests$jn table has an ordinary index on (trq_id, version_id). This query is embedded in some PL/SQL with an INTO clause – so it will only fetch one record (plus a 2nd fetch to detect TOO_MANY_ROWS which we know won’t happen).
The table is relatively small (in dev it only has 6K records, and production data volumes are expected to grow very slowly) but regardless, I was pleased to find that (at least, in Oracle 12.1) it uses a nice optimisation so that it not only uses the index, it is choosing to use a Descending scan on it – which means it avoids a SORT operation, and should very quickly return the 2nd record that we desire.
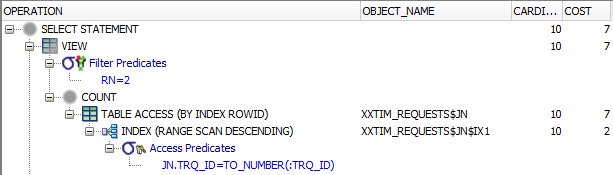
It looks quite similar in effect to the “COUNT STOPKEY” optimisation you can see on “ROWNUM=1” queries. If this was a much larger table and this query needed to be faster or was being run more frequently, I’d probably consider appending status_code to the index in order to avoid the table access. In this case, however, I don’t think it’s necessary.
Oracle 12c introduced the ability to specify sequence.nextval as the default on a column, which is really nice – including the fact that it eliminates one of your excuses why you don’t decommission those old triggers.
Unfortunately it doesn’t work as you might expect if you use an INSERT ALL statement; it evaluates the default expression once per statement, instead of once per row.
Test case:
create sequence test_seq;
create table test_tab
( id number default test_seq.nextval primary key
, dummy varchar2(100) not null );
insert into test_tab (dummy) values ('xyz');
1 row inserted.
insert all
into test_tab (dummy) values ('abc')
into test_tab (dummy) values ('def')
select null from dual;
Error report -
SQL Error: ORA-00001: unique constraint
(SCOTT.SYS_C00123456) violated
A minor issue, usually, but something to be aware of – especially if you’re not in the habit of declaring your unique constraints to the database!
create sequence test_seq;
create table test_stupid_tab
( id number default test_seq.nextval
, dummy varchar2(100) not null );
insert into test_tab (dummy) values ('xyz');
1 row inserted.
insert all
into test_tab (dummy) values ('abc')
into test_tab (dummy) values ('def')
select null from dual;
2 rows inserted.
select * from test_tab;
i dummy
= =====
1 xyz
2 abc
2 def
ADDENDUM 28/10/2016
Another similar scenario which might trip you up is where you are inserting from a UNION view:
create sequence test_seq;
create table test_tab
( id number default test_seq.nextval primary key
, dummy varchar2(100) not null
);
insert into test_tab (dummy) select 'x' from dual;
-- success
insert into test_tab (dummy)
select 'y' from dual union all select 'z' from dual;
-- fails with ORA-01400 "cannot insert NULL into id"
insert into test_tab (dummy) select c from (
select 'y' c from dual union all select 'z' from dual
);
-- success
Yesterday I published a SQL problem (that I I had solved – or at least, thought I had solved!) and invited readers to submit their own solutions.
SPOILER ALERT: if you haven’t had a chance to have a go yourself, go back, don’t read the comments (yet), but see if you can solve it yourself.
I was very pleased to see two excellent submissions that were both correct as far as I could tell, and are (in my opinion) sufficiently simple, elegant and efficient. Note that this was not a competition and I will not be ranking or rating or anything like that. If you need to solve a similar problem, I would suggest you try all of these solutions out and pick the one that seems to work the best for you.
Solution #1
Stew Ashton supplied the first solution which was very simple and elegant:
with dates as (
select distinct deptid, dte from (
select deptid, from_date, to_date+1 to_date from t1
union all
select deptid, from_date, to_date+1 to_date from t2
)
unpivot(dte for col in(from_date, to_date))
)
select * from (
select distinct a.deptid, dte from_date,
lead(dte) over(partition by a.deptid order by dte) - 1 to_date,
data1, data2 from dates a
left join t1 b on a.deptid = b.deptid and a.dte between b.from_date and b.to_date
left join t2 c on a.deptid = c.deptid and a.dte between c.from_date and c.to_date
)
where data1 is not null or data2 is not null
order by 1,2;
SQL Fiddle
Stew’s solution does a quick pass over the two tables and generates a “date dimension” table in memory; it then does left joins to each table to generate each row. It may have a disadvantage due to the requirement to make two passes over the tables, which might be mitigated by suitable indexing. As pointed out by Matthias Rogel, this solution can be easily generalised to more than two tables, which is a plus.
Solution #2
The second solution was provided by Kim Berg Hansen which was a bit longer but in my opinion, still simple and elegant:
with v1 as (
select t.deptid
, case r.l
when 1 then t.from_date
when 2 then date '0001-01-01'
when 3 then t.max_to + 1
end from_date
, case r.l
when 1 then t.to_date
when 2 then t.min_from -1
when 3 then date '9999-01-01'
end to_date
, case r.l
when 1 then t.data1
end data1
from (
select deptid
, from_date
, to_date
, data1
, row_number() over (partition by deptid order by from_date) rn
, min(from_date) over (partition by deptid) min_from
, max(to_date) over (partition by deptid) max_to
from t1
) t, lateral(
select level l
from dual
connect by level <= case t.rn when 1 then 3 else 1 end
) r
), v2 as (
select t.deptid
, case r.l
when 1 then t.from_date
when 2 then date '0001-01-01'
when 3 then t.max_to + 1
end from_date
, case r.l
when 1 then t.to_date
when 2 then t.min_from -1
when 3 then date '9999-01-01'
end to_date
, case r.l
when 1 then t.data2
end data2
from (
select deptid
, from_date
, to_date
, data2
, row_number() over (partition by deptid order by from_date) rn
, min(from_date) over (partition by deptid) min_from
, max(to_date) over (partition by deptid) max_to
from t2
) t, lateral(
select level l
from dual
connect by level <= case t.rn when 1 then 3 else 1 end
) r
)
select v1.deptid
, greatest(v1.from_date, v2.from_date) from_date
, least(v1.to_date, v2.to_date) to_date
, v1.data1
, v2.data2
from v1
join v2
on v2.deptid = v1.deptid
and v2.to_date >= v1.from_date
and v2.from_date <= v1.to_date
where v2.data2 is not null or v1.data1 is not null
order by v1.deptid
, greatest(v1.from_date, v2.from_date)
Since it takes advantage of 12c’s new LATERAL feature, I wasn’t able to test it on my system, but I was able to test it on Oracle’s new Live SQL and it passed with flying colours. I backported it to 11g and it worked just fine on my system as well. An advantage of Kim’s solution is that it should only make one pass over each of the two tables.
Oracle Live SQL: merge-history-kimberghansen (this is the 12c version – Oracle login required)
SQL Fiddle (this is my attempt to backport to 11g – you can judge for yourself if I was faithful to the original)
Solution #3
When my colleague came to me with this problem, I started by creating a test suite including as many test cases as we could think of. Developing and testing the solution against these test cases proved invaluable and allowed a number of ideas to be tested and thrown away. Big thanks go to Kim Berg Hansen for providing an additional test case, which revealed a small bug in my original solution.
with q1 as (
select nvl(t1.deptid, t2.deptid) as deptid
,greatest(nvl(t1.from_date, t2.from_date), nvl(t2.from_date, t1.from_date)) as gt_from_date
,least(nvl(t1.to_date, t2.to_date), nvl(t2.to_date, t1.to_date)) as lt_to_date
,t1.from_date AS t1_from_date
,t1.to_date AS t1_to_date
,t2.from_date AS t2_from_date
,t2.to_date AS t2_to_date
,min(greatest(t1.from_date, t2.from_date)) over (partition by t1.deptid) - 1 as fr_to_date
,max(least(t1.to_date, t2.to_date)) over (partition by t2.deptid) + 1 as lr_from_date
,t1.data1
,t2.data2
,row_number() over (partition by t1.deptid, t2.deptid order by t1.from_date) as rn_fr1
,row_number() over (partition by t1.deptid, t2.deptid order by t2.from_date) as rn_fr2
,row_number() over (partition by t1.deptid, t2.deptid order by t1.to_date desc) as rn_lr1
,row_number() over (partition by t1.deptid, t2.deptid order by t2.to_date desc) as rn_lr2
from t1
full outer join t2
on t1.deptid = t2.deptid
and (t1.from_date between t2.from_date and t2.to_date
or t1.to_date between t2.from_date and t2.to_date
or t2.from_date between t1.from_date and t1.to_date
or t2.to_date between t1.from_date and t1.to_date)
order by 1, 2
)
select deptid
,gt_from_date AS from_date
,lt_to_date AS to_date
,data1
,data2
from q1
union all
select deptid
,t1_from_date as from_date
,fr_to_date AS to_date
,data1
,'' AS data2
from q1
where fr_to_date between t1_from_date and t1_to_date
and rn_fr1 = 1
union all
select deptid
,t2_from_date as from_date
,fr_to_date AS to_date
,'' AS data1
,data2
from q1
where fr_to_date between t2_from_date and t2_to_date
and rn_fr2 = 1
union all
select deptid
,lr_from_date as from_date
,t2_to_date AS to_date
,'' AS data1
,data2
from q1
where lr_from_date between t2_from_date and t2_to_date
and rn_lr2 = 1
union all
select deptid
,lr_from_date as from_date
,t1_to_date AS to_date
,data1
,'' AS data2
from q1
where lr_from_date between t1_from_date and t1_to_date
and rn_lr1 = 1
order by deptid, from_date
SQL Fiddle
This solution is probably the ugliest of the three, and though it only requires one pass over the two tables, it materializes all the data in a temp table so probably requires a fair amount of memory for large data sets.
I’m so glad I posted this problem – I received help in the form of two quite different solutions, which help to show different ways of approaching problems like this. Not only that, but it highlighted the value of test-driven development – instead of groping in the dark to come up with a quick-and-dirty solution (that might or might not work), starting with comprehensive test cases is invaluable for both developing and validating potential solutions.
A colleague asked me if I could help solve a problem in SQL, and I was grateful because I love solving problems in SQL! So we sat down, built a test suite, and worked together to solve it.
I will first present the problem and invite you to have a go at solving it for yourself; tomorrow I will post the solution we came up with. I think our solution is reasonably simple and elegant, but I’m certain there are other solutions as well, some of which may be more elegant or efficient.
I have two “record history” tables, from different data sources, that record the history of changes to two sets of columns describing the same entity. Here are the example tables:
T1 (deptid, from_date, to_date, data1)
T2 (deptid, from_date, to_date, data2)
So T1 records the changes in the column “data1” over time for each deptid; and T2 records the changes in the column “data2” over time for each deptid.
Assumptions/Constraints on T1 and T2:
- All columns are not Null.
- All dates are just dates (no time values).
- All date ranges are valid (i.e. from_date <- to_date).
- Within each table, all date ranges for a particular deptid are gap-free and have no overlaps.
We want to produce a query that returns the following structure:
T3 (deptid, from_date, to_date, data1, data2)
Where the dates for a particular deptid overlap between T1 and T2, we want to see the corresponding data1 and data2 values. Where the dates do not overlap (e.g. where we have a value for data1 in T1 but not in T2), we want to see the corresponding data1 but NULL for data2; and vice versa.
Below is the setup and test cases you can use if you wish. Alternatively, you can use the SQL Fiddle here.
create table t1
(deptid number not null
,from_date date not null
,to_date date not null
,data1 varchar2(30) not null
,primary key (deptid, from_date)
);
create table t2
(deptid number not null
,from_date date not null
,to_date date not null
,data2 varchar2(30) not null
,primary key (deptid, from_date)
);
--Test Case 1 (4001)
--T1 |-------------||-------------|
--T2 |-------------||-------------||-------------|
insert into t1 values (4001, date'2015-01-01', date'2015-01-31', 'jan data 1');
insert into t1 values (4001, date'2015-02-01', date'2015-02-28', 'feb data 1');
insert into t2 values (4001, date'2015-01-15', date'2015-02-14', 'jan-feb data 2');
insert into t2 values (4001, date'2015-02-15', date'2015-03-14', 'feb-mar data 2');
insert into t2 values (4001, date'2015-03-15', date'2015-04-14', 'mar-apr data 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4001 01-JAN-2015 14-JAN-2015 jan data 1
--4001 15-JAN-2015 31-JAN-2015 jan data 1 jan-feb data 2
--4001 01-FEB-2015 14-FEB-2015 feb data 1 jan-feb data 2
--4001 15-FEB-2015 28-FEB-2015 feb data 1 feb-mar data 2
--4001 01-MAR-2015 14-MAR-2015 feb-mar data 2
--4001 15-MAR-2015 14-APR-2015 mar-apr data 2
--Test Case 2 (4002)
--T1 |-------------||-------------||-------------|
--T2 |-------------||-------------|
insert into t1 values (4002, date'2015-01-15', date'2015-02-14', 'jan-feb data 1');
insert into t1 values (4002, date'2015-02-15', date'2015-03-14', 'feb-mar data 1');
insert into t1 values (4002, date'2015-03-15', date'2015-04-14', 'mar-apr data 1');
insert into t2 values (4002, date'2015-01-01', date'2015-01-31', 'jan data 2');
insert into t2 values (4002, date'2015-02-01', date'2015-02-28', 'feb data 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4002 01-JAN-2015 14-JAN-2015 jan data 2
--4002 15-JAN-2015 31-JAN-2015 jan-feb data 1 jan data 2
--4002 01-FEB-2015 14-FEB-2015 jan-feb data 1 feb data 2
--4002 15-FEB-2015 28-FEB-2015 feb-mar data 1 feb data 2
--4002 01-MAR-2015 14-MAR-2015 feb-mar data 1
--4002 15-MAR-2015 14-APR-2015 mar-apr data 1
--Test Case 3 (4003)
--T1 |-------------|
--T2 |-------------|
insert into t1 values (4003, date'2015-01-01', date'2015-01-31', 'jan data 1');
insert into t2 values (4003, date'2015-01-01', date'2015-01-31', 'jan data 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4003 01-JAN-2015 31-JAN-2015 jan data 1 jan data 2
--Test Case 4 (4004)
--T1 |-------------|
--T2 |-----|
insert into t1 values (4004, date'2015-01-01', date'2015-01-31', 'jan data 1');
insert into t2 values (4004, date'2015-01-10', date'2015-01-20', 'jan data int 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4004 01-JAN-2015 09-JAN-2015 jan data 1
--4004 10-JAN-2015 20-JAN-2015 jan data 1 jan data int 2
--4004 21-JAN-2015 31-JAN-2015 jan data 1
--Test Case 5 (4005)
--T1 |-----|
--T2 |-------------|
insert into t1 values (4005, date'2015-01-10', date'2015-01-20', 'jan data int 1');
insert into t2 values (4005, date'2015-01-01', date'2015-01-31', 'jan data 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4005 01-JAN-2015 09-JAN-2015 jan data 2
--4005 10-JAN-2015 20-JAN-2015 jan data int 1 jan data 2
--4005 21-JAN-2015 31-JAN-2015 jan data 2
--Test Case 6 (4006)
--T1 ||------------|
--T2 |-------------|
insert into t1 values (4006, date'2015-01-01', date'2015-01-01', 'jan data a 1');
insert into t1 values (4006, date'2015-01-02', date'2015-01-31', 'jan data b 1');
insert into t2 values (4006, date'2015-01-01', date'2015-01-31', 'jan data 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4006 01-JAN-2015 01-JAN-2015 jan data a 1 jan data 2
--4006 02-JAN-2015 31-JAN-2015 jan data b 1 jan data 2
--Test Case 7 (4007)
--T1 |-------------|
--T2 ||------------|
insert into t1 values (4007, date'2015-01-01', date'2015-01-31', 'jan data 1');
insert into t2 values (4007, date'2015-01-01', date'2015-01-01', 'jan data a 2');
insert into t2 values (4007, date'2015-01-02', date'2015-01-31', 'jan data b 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4007 01-JAN-2015 01-JAN-2015 jan data 1 jan data a 2
--4007 02-JAN-2015 31-JAN-2015 jan data 1 jan data b 2
--Test Case 8 (4008)
--T1 |-------------|
--T2 |---||---||---|
insert into t1 values (4008, date'2015-01-01', date'2015-01-31', 'jan data 1');
insert into t2 values (4008, date'2015-01-09', date'2015-01-17', 'jan data a 2');
insert into t2 values (4008, date'2015-01-18', date'2015-01-26', 'jan data b 2');
insert into t2 values (4008, date'2015-01-27', date'2015-02-04', 'jan-feb data 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4008 01-JAN-2015 08-JAN-2015 jan data 1
--4008 09-JAN-2015 17-JAN-2015 jan data 1 jan data a 2
--4008 18-JAN-2015 26-JAN-2015 jan data 1 jan data b 2
--4008 27-JAN-2015 31-JAN-2015 jan data 1 jan-feb data 2
--4008 01-FEB-2015 04-FEB-2015 jan-feb data 2
--Test Case 9 (4009)
--T1 |---||---||---|
--T2 |-------------|
insert into t1 values (4009, date'2015-01-09', date'2015-01-17', 'jan data a 1');
insert into t1 values (4009, date'2015-01-18', date'2015-01-26', 'jan data b 1');
insert into t1 values (4009, date'2015-01-27', date'2015-02-04', 'jan-feb data 1');
insert into t2 values (4009, date'2015-01-01', date'2015-01-31', 'jan data 2');
--Expected Output:
--DEPTID FROM_DATE TO_DATE DATA1 DATA2
--====== =========== =========== ============== ==============
--4009 01-JAN-2015 08-JAN-2015 jan data 2
--4009 09-JAN-2015 17-JAN-2015 jan data a 1 jan data 2
--4009 18-JAN-2015 26-JAN-2015 jan data b 1 jan data 2
--4009 27-JAN-2015 31-JAN-2015 jan-feb data 1 jan data 2
--4009 01-FEB-2015 04-FEB-2015 jan-feb data 1
EDIT 15/10/2015: added Kim Berg Hansen’s test cases
UPDATE 15/10/2015: solutions (spoiler alert!)
I have an Oracle database (10g or 11g, doesn’t matter) with an empty schema. I am the only user on the system and I only have one session open.
I create a single table (FOO) and run a few simple SQL commands. Then, I run this, twice in a row without any intermediate steps:
DROP TABLE foo;
The first time, some errors are raised and the table is not dropped.
The second time, it succeeds – the table is dropped without error.
Q. What did I do to cause this behaviour (which is 100% reproducible) – and what errors were reported?
A. Congratulations to Kirill Leontiev, Matthias Rogel, Charles Hooper and Mette who all found the answer!
Spoiler Alert: Don’t read the comments if you don’t want to know the answer straight away.
When you deploy a procedure, function or package that has a compilation error, the object is still created, and you can still apply grants on them. This is convenient when deploying a large number of objects, meaning you don’t have to get them all in the right order. After deploying your schema, you can just recompile the invalid objects.
Unfortunately, this doesn’t work for views. Now, normally if you create a view with compilation errors, the view will not be created at all; for a deployment script, however, you could use CREATE FORCE VIEW that means the view will be created (but marked invalid).
Let’s say you have a view that depends on a table that doesn’t exist yet – and won’t exist until much later in your deployment scripts. So you create the view with the FORCE option – success. Then, you apply the GRANTs for the view, and get this:
ORA-04063: view "x" has errors
Why? If you try to grant on a procedure, function or package that has errors, it works fine. For views, apparently, this is not allowed.
Obviously, to solve this you might do the hard work and reorder your deployment scripts so that they create every object in the perfectly correct order, avoiding compilation errors entirely. If you have a large number of objects to deploy, this might be more trouble than you want. Well, there is a workaround:
1. Create the view, minus the bit that causes a compilation error.
2. Apply the grant.
3. Recreate the view, compilation error and all. The grant will remain.
Why might this be useful? In my case, we have two databases connected by database links (on both sides); and we need to deploy a large number of objects to both instances. They are managed by different teams, so we want to be able to deploy the changes to each independently. For the most part, the objects on “our side” compile fine, except for some views that refer to objects on the other side of the database link; but they won’t exist until the other team deploys their changes. We could even have a chicken-and-egg problem, when their views refer to objects on our instance; either way, some of the objects cannot be created error-free until both deployments have been completed.
As it stands, we have two options: deploy everything as best we can, then afterwards (when both deployments have completed), recompile the invalid objects and apply the view grants. An alternative is to use this workaround.
Demonstration
TEST CASE #1: cannot grant on a view with errors
SQL> create or replace force view testview as
select 1 as col from bla;
Warning: View created with compilation errors.
SQL> grant select on testview to someone;
ORA-04063: view "USER.TESTVIEW" has errors
SQL> select grantee, privilege from user_tab_privs
where table_name = 'TESTVIEW';
no rows selected
TEST CASE #2: grant on a view with errors
SQL> create or replace view testview as
select 1 as col from dual;
View created.
SQL> grant select on testview to someone;
Grant succeeded.
SQL> create or replace force view testview as
select 1 as col from bla;
Warning: View created with compilation errors.
SQL> select grantee, privilege from user_tab_privs
where table_name = 'TESTVIEW';
GRANTEE PRIVILEGE
======= =========
SOMEONE SELECT
The above has been tested on Oracle 10gR2 and 11gR2. Should this mean that Oracle should not really raise ORA-04063 in this case? I think so.
Every mature language, platform or system has little quirks, eccentricities, and anachronisms that afficionados just accept as “that’s the way it is” and that look weird, or outlandishly strange to newbies and outsiders. The more mature, and more widely used is the product, the more resistance to change there will be – causing friction that helps to ensure these misfeatures survive.
Oracle, due to the priority placed on backwards compatibility, and its wide adoption, is not immune to this phenomenon. Unless a feature is actively causing things to break, as long as there are a significant number of sites using it, it’s not going to change. In some cases, the feature might be replaced and the original deprecated and eventually removed; but for core features such as SQL and PL/SQL syntax, especially the semantics of the basic data types, it is highly unlikely these will ever change.
So here I’d like to list what I believe are the things in Oracle that most frequently confuse people. These are not necessarily intrinsically complicated – just merely unintuitive, especially to a child of the 90’s or 00’s who was not around when these things were first implemented, when the idea of “best practice” had barely been invented; or to someone more experienced in other technologies like SQL Server or Java. These are things I see questions about over and over again – both online and in real life. Oh, and before I get flamed – another disclaimer: some of these are not unique to Oracle – some of them are more to do with the SQL standard; some of them are caused by a lack of understanding of the relational model of data.
Once you know them, they’re easy – you come to understand the reasons (often historical) behind them; eventually, the knowledge becomes so ingrained, it’s difficult to remember what it was like beforehand.
Top 10 Confusing Things in Oracle
-
-
-
-
-
-
-
-
-
-
Got something to add to the list? Drop me a note below.
More resources:
If you have a table that represents time-varying info, e.g. with From and To date/time columns, you have a few options with regards to the problem of overlapping dates:
1. Check for overlapping dates in the application layer.
2. Use an off-the-shelf product to generate the appropriate triggers, e.g. Oracle CDM*RuleFrame or Toon Koppelaars’ RuleGen.
3. Roll your own, in the database.
4. Use a different data model that can use a unique constraint.
5. Forget about it.
One reason it’s difficult is that this is an example of a cross-row constraint, i.e. one that cannot merely be checked for the current row by itself. Oracle supports a few cross-row constraints, i.e. Primary Key, Unique and Foreign Key constraints; but it doesn’t natively support arbitrary assertions, which would allow us to easily declare this sort of constraint.
The real challenge comes from the fact that Oracle is a multi-user system and concurrent sessions cannot see the uncommitted data from other sessions; so some form of serialization will be required to ensure that when one session wishes to insert/update the data for a particular entity, no other session is allowed to start working on the same entity until the first session commits (or issues a rollback).
The problem is not new; it’s been around for a long time, and tripped many a new (and old) programmer.
There are two problems with option #1 (code in the application layer): firstly, you have to repeat the code for each different type of client (e.g. you might have a Java UI on one side, as well as some batch script somewhere else); secondly, usually the programmer involved will not understand the concurrency problem mentioned above and will not take it into account.
Option #2 is probably the best, most of the time. The solution is implemented at the database level, and is more likely to work correctly and efficiently.
Option #4 (change the data model) involves not storing the From and To dates, but instead dividing up all time ranges into discrete chunks, and each row represents a single chunk of time. This solution is valid if the desired booking ranges are at predictable discrete ranges, e.g. daily. You can then use an ordinary unique constraint to ensure that each chunk of time is only booked by one entity at any one time. This is the solution described here.
Option #5 (forget about it) is also a viable option, in my opinion. Basically it entails designing the rest of the application around the fact that overlapping date ranges might exist in the table – e.g. a report might simply merge the date ranges together prior to output.
Option #3, where you implement the triggers yourself on the database, has the same advantage as Option #2, where it doesn’t matter which application the data is coming from, the constraint will hold true. However, you have to be really careful because it’s much easier to get it wrong than it is to get right, due to concurrency.
I hear you scoffing, “Triggers?!?”. I won’t comment except to refer you to this opinion, which I couldn’t say it better myself: The fourth use-case for Triggers.
There is another Option #3 using a materialized view instead of triggers; I’ll describe this alternative at the end of this post.
So, here is a small example showing how an overlapping date constraint may be implemented. It is intentionally simple to illustrate the approach: it assumes that the From and To dates cannot be NULL, and its rule for detecting overlapping dates requires that the dates not overlap at all, to the nearest second.
- Create the tables
CREATE TABLE room
(room_no NUMBER NOT NULL
,CONSTRAINT room_pk PRIMARY KEY (room_no)
);
CREATE TABLE room_booking
(room_no NUMBER NOT NULL
,booked_from DATE NOT NULL
,booked_to DATE NOT NULL
,CONSTRAINT room_booking_pk
PRIMARY KEY (room_no, booked_from)
,CONSTRAINT room_booking_fk
FOREIGN KEY (room_no) REFERENCES room (room_no)
);
- Create the validation trigger (note – I’ve used an Oracle 11g compound trigger here, but it could easily be rewritten for earlier versions by using two triggers + a database package):
CREATE OR REPLACE TRIGGER room_booking_trg
FOR INSERT OR UPDATE OF room_no, booked_from, booked_to
ON room_booking
COMPOUND TRIGGER
TYPE room_no_array IS TABLE OF CHAR(1)
INDEX BY BINARY_INTEGER;
room_nos room_no_array;
PROCEDURE lock_room (room_no IN room.room_no%TYPE) IS
dummy room.room_no%TYPE;
BEGIN
SELECT r.room_no
INTO dummy
FROM room r
WHERE r.room_no = lock_room.room_no
FOR UPDATE;
END lock_room;
PROCEDURE validate_room (room_no IN room.room_no%TYPE) IS
overlapping_booking EXCEPTION;
dummy CHAR(1);
BEGIN
-- check for overlapping date/time ranges
BEGIN
SELECT 'X' INTO dummy
FROM room_booking rb1
,room_booking rb2
WHERE rb1.room_no = validate_room.room_no
AND rb2.room_no = validate_room.room_no
AND rb1.booked_from != rb2.booked_from
AND (
rb1.booked_from BETWEEN rb2.booked_from
AND rb2.booked_to
OR
rb1.booked_to BETWEEN rb2.booked_from
AND rb2.booked_to
)
AND ROWNUM = 1;
RAISE overlapping_booking;
EXCEPTION
WHEN NO_DATA_FOUND THEN
-- good, no constraint violations
NULL;
END;
EXCEPTION
WHEN overlapping_booking THEN
RAISE_APPLICATION_ERROR(-20000,
'Overlapping booking for room #' || room_no);
END validate_room;
PROCEDURE validate_rooms IS
room_no room.room_no%TYPE;
BEGIN
room_no := room_nos.FIRST;
LOOP
EXIT WHEN room_no IS NULL;
validate_room (room_no);
room_no := room_nos.NEXT(room_no);
END LOOP;
room_nos.DELETE;
EXCEPTION
WHEN OTHERS THEN
room_nos.DELETE;
RAISE;
END validate_rooms;
BEFORE EACH ROW IS
BEGIN
-- lock the header record (so other sessions
-- can't modify the bookings for this room
-- at the same time)
lock_room(:NEW.room_no);
-- remember the room_no to validate later
room_nos(:NEW.room_no) := 'Y';
END BEFORE EACH ROW;
AFTER STATEMENT IS
BEGIN
validate_rooms;
END AFTER STATEMENT;
END room_booking_trg;
/
That’s all you need. The trigger locks the header record for the room, so only one session can modify the bookings for a particular room at any one time. If you don’t have a table like “room” in your database that you can use for this purpose, you could use DBMS_LOCK instead (similarly to that proposed in the OTN forum discussion here).
It would not be difficult to adapt this example for alternative requirements, e.g. where the From and To dates may be NULL, or where the overlapping criteria should allow date/time ranges that coincide at their endpoints (e.g. so that the date ranges (1-Feb-2000 to 2-Feb-2000) and (2-Feb-2000 to 3-Feb-2000) would not be considered to overlap). You’d just need to modify the comparison in the query in validate_room to take these requirements into account.
Test case #1
INSERT INTO room (room_no) VALUES (101);
INSERT INTO room (room_no) VALUES (201);
INSERT INTO room (room_no) VALUES (301);
INSERT INTO room_booking (room_no, booked_from, booked_to)
VALUES (101, DATE '2000-01-01', DATE '2000-01-02' - 0.00001);
INSERT INTO room_booking (room_no, booked_from, booked_to)
VALUES (101, DATE '2000-01-02', DATE '2000-01-03' - 0.00001);
INSERT INTO room_booking (room_no, booked_from, booked_to)
VALUES (201, DATE '2000-02-01', DATE '2000-02-05' - 0.00001);
Expected: no errors
Test case #2
INSERT INTO room_booking (room_no, booked_from, booked_to)
VALUES (201, DATE '2000-02-01', DATE '2000-02-02' - 0.00001);
INSERT INTO room_booking (room_no, booked_from, booked_to)
VALUES (201, DATE '2000-02-02', DATE '2000-02-04' - 0.00001);
INSERT INTO room_booking (room_no, booked_from, booked_to)
VALUES (201, DATE '2000-02-03', DATE '2000-02-05' - 0.00001);
INSERT INTO room_booking (room_no, booked_from, booked_to)
VALUES (201, DATE '2000-02-03', DATE '2000-02-06' - 0.00001);
INSERT INTO room_booking (room_no, booked_from, booked_to)
VALUES (201, DATE '2000-01-31', DATE '2000-02-01');
INSERT INTO room_booking (room_no, booked_from, booked_to)
VALUES (201, DATE '2000-01-31', DATE '2000-02-02' - 0.00001);
INSERT INTO room_booking (room_no, booked_from, booked_to)
VALUES (201, DATE '2000-01-31', DATE '2000-02-06' - 0.00001);
INSERT INTO room_booking (room_no, booked_from, booked_to)
VALUES (201, DATE '2000-02-05' - 0.00001, DATE '2000-02-06' - 0.00001);
UPDATE room_booking SET booked_to = '2000-01-02' - 0.00001
WHERE room_no = 101 AND booked_from = DATE '2000-01-02';
Expected: constraint violation on each statement
Test case #3
in session #1:
INSERT INTO room_booking (room_no, booked_from, booked_to)
VALUES (301, DATE '2000-01-01', DATE '2000-02-01' - 0.00001);
in session #2:
INSERT INTO room_booking (room_no, booked_from, booked_to)
VALUES (301, DATE '2000-01-15', DATE '2000-01-16' - 0.00001);
Expected: session #2 will wait until session #1 issues a COMMIT or ROLLBACK. If session #1 COMMITs, session #2 will then report a constraint violation. If session #2 rolls back, session #2 will complete without error.
The No-Trigger option #3: Materialized View
This is similar to a solution proposed by Rob Van Wijk. It uses a constraint on a materialized view to stop overlapping date ranges.
So, instead of the trigger, you would do something like this:
CREATE MATERIALIZED VIEW LOG ON room_booking WITH ROWID;
CREATE MATERIALIZED VIEW room_booking_date_ranges
REFRESH FORCE ON COMMIT
AS SELECT 'X' AS dummy
FROM room_booking rb1
,room_booking rb2
WHERE rb1.room_no = rb2.room_no
AND rb1.booked_from != rb2.booked_from
AND (
rb1.booked_from BETWEEN rb2.booked_from
AND rb2.booked_to
OR
rb1.booked_to BETWEEN rb2.booked_from
AND rb2.booked_to
);
ALTER TABLE room_booking_date_ranges
ADD CONSTRAINT no_overlapping_dates_ck
CHECK ( dummy = 'Z' );
The nice thing about this solution is that it is simpler to code, and seems more “declarative” in nature. Also, you don’t have to worry about concurrency at all.
The constraint is checked at COMMIT-time when the materialized view is refreshed; so it behaves like a deferred constraint, which may be an advantage for some scenarios.
I believe it may perform better than the trigger-based option when large volumes of data are inserted or updated; however it may perform worse than the trigger-based option when you have lots of small transactions. This is because, unfortunately, the query here cannot be a “REFRESH FAST ON COMMIT” (if you know how this could be changed into a REFRESH FAST MV, please let me know!).
What do you think? If you see any potential issues with the above solutions please feel free to comment.
EDIT 30/8: added some more test cases
Consider:
DATE is not a date.DATE '2012-06-22' is not a date.CURRENT_DATE is not a date.SYSDATE is not a date.TRUNC(SYSDATE) is not a date.TO_DATE('22/06/2012','DD/MM/YYYY') is not a date.
Oracle SQL does not have a native date datatype.
Explanation: the datatype called “DATE” actually represents a Date+Time. It always has a time portion. For example, the literal expression DATE '2012-06-22'has a time component that means midnight, to the nearest second. It is only by convention that a DATE with a time of 00:00:00 is used to represent the whole day, rather than exactly midnight; but this convention only works if the developer carefully writes his code to ensure this is true.

It is theorized that the ancients solved “once and for all” the problem with dates vs. times.
To an experienced Oracle developer, this is not a problem, it feels perfectly natural to say “DATE” but internally to be thinking in terms of time values. It’s easy to forget that we’re even doing this subconsciously. To an outsider (e.g. business analysts, testers, Java developers), it can be confusing – and it is often not immediately obvious that the confusion exists. It’s not until you start explaining why SYSDATE <= DATE '2012-06-22' evaluates to FALSE, even if today is the 22nd day of the month of June in the year of our Lord 2012 that you realise they have been labouring under a false assumption: that a DATE is a date, that it represents the full 24-hour period that a normal human would call “22 June 2012”.
If I was invited to change the name of just one thing in Oracle (and everyone was willing to make all the changes necessary to their code to accommodate my whim) it would be to change “DATE” to “DATETIME”.
I ask you: is there anything else in Oracle that confuses outsiders more often than this misnomer?
P.S. Now for a freebie: here is a summary of a number of transformations that may be done to remove the TRUNC function call around a date column (a and b are all of type DATE):
TRUNC(a) = TRUNC(b) => (a BETWEEN TRUNC(b) AND TRUNC(b)+0.99999)
TRUNC(a) < TRUNC(b) => a < TRUNC(b)
TRUNC(a) <= TRUNC(b) => a < TRUNC(b)+1
TRUNC(a) > TRUNC(b) => a >= TRUNC(b)+1
TRUNC(a) >= TRUNC(b) => a >= TRUNC(b)
TRUNC(a) = b => (a BETWEEN b AND b+0.99999
AND b = TRUNC(b))
TRUNC(a) < b => (a < TRUNC(b)+1
AND NOT (a=TRUNC(a) AND b=TRUNC(b)))
TRUNC(a) <= b => a < TRUNC(b)+1
TRUNC(a) > b => a >= TRUNC(b)+1
TRUNC(a) >= b => (a >= TRUNC(b)
AND NOT (b=TRUNC(b)))
What’s the biggest clue you can give that your database is vulnerable to SQL injection? When your list of “forbidden words” looks suspiciously like a sample of SQL / PL/SQL keywords:
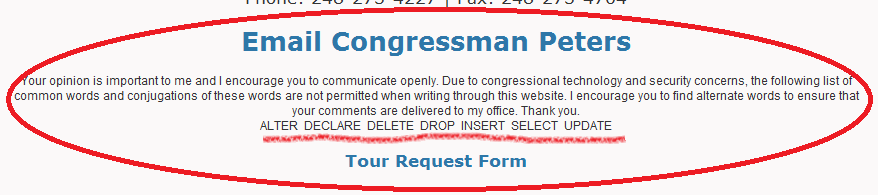
I notice that they haven’t forbidden BEGIN, CREATE, MERGE, or TRUNCATE …
Congressman Peters, your IT staff are doing it wrong.
Via: http://thedailywtf.com/Articles/Out-of-Service.aspx#pic4

