Your ‘PL/SQL Code’

Am I the only one who finds this help message vaguely insulting?


Am I the only one who finds this help message vaguely insulting?
AUSOUG is holding a series of conferences this year right across the country – starting in Sydney on 15-16 August, touring the other major city centres, and ending in Perth on 12-13 November.
The Perth program is still being finalized but the lineup is looking good. You can see the current list here: http://www.ausoug.org.au/insync13/insync13-perth-program.html
I’ll be talking about Oracle Virtual Private Database or RLS and its use in APEX applications. I’ve made good use of this technology in a recent project which is now live and I’m looking forward to presenting what I’ve learned. Abstract
Make sure you register soon – pre-registrations close soon for some locations.
UPDATE: The Perth program is now published: INSYNC13_Program_Perth.pdf
UPDATE 2: The slide deck if you’re interested can be seen here.
 If you’re interested in my presentation on the Function Result Cache, it’s now available from my presentations page. It was given this morning at Oracle’s offices in Perth to the local AUSOUG branch and seemed to go down well and I got some good feedback. It was only a little overshadowed by all the hoopla over the release of 12c 🙂
If you’re interested in my presentation on the Function Result Cache, it’s now available from my presentations page. It was given this morning at Oracle’s offices in Perth to the local AUSOUG branch and seemed to go down well and I got some good feedback. It was only a little overshadowed by all the hoopla over the release of 12c 🙂
If you’re in Perth on Wednesday the 26th, come for breakfast at the Oracle offices and hear me talk about my experiences with the PL/SQL Function Result Cache.
More details here: www.ausoug.org.au/cms/rest/event/1936

The Australian Oracle User Group is holding the Oracle with 20:20 Foresight National Conference in Perth, 29-30 October. Yikes, that’s only 3 weeks away – if you’re in Perth, you have to sign up right now. If you’re not in Perth, grab your skateboard or canoe (depending on the intervening terrain) and get over here!
We’re going to be treated with talks by Tom Kyte, Connor McDonald, Chris Muir, Scott Wesley, Graham Wood and many others. Check out the conference program to see what’s on offer. A lot of the topics seem to be very Mobile and Cloudy…
I’ll be presenting twice, if you’re interested I’d love to see you there:
1. Alexandria – A Guided Tour – an overview of just a few of the goodies that you’ll find in the Alexandria PL/SQL Library, and how you can use them out-of-the-box to do things that you might have thought could not be done in PL/SQL.
2. Top 20 Gotchas with Old Database Versions – most probably you’ll be working with Oracle 10g or 11g nowadays – but sometimes you don’t have a choice but to deal with older versions like 8i or 9i. If so you may very well pick up a few hints and tips that will save you time and headaches.
If you missed out on that “open world” conference, you’ll have to come and hear about the new features planned for Oracle 12c. Even if you did manage to get to that big conference, you’ll want to come to this one as well, not least because it’s in beautiful sunny Perth 🙂
EDIT: Slide decks and demo scripts for the presentations are available from here: http://jeffkemponoracle.com/presentations/
 In Perth this morning, at a breakfast courtesy of the local AUSOUG, I spoke about using the Alexandria PL/SQL Library to automate various tasks with Amazon’s Simple Storage (S3) service. If you haven’t used Amazon Web Services before, or haven’t looked at Alexandria yet, and you enjoy discovering new capabilities with PL/SQL I think you’ll find this interesting.
In Perth this morning, at a breakfast courtesy of the local AUSOUG, I spoke about using the Alexandria PL/SQL Library to automate various tasks with Amazon’s Simple Storage (S3) service. If you haven’t used Amazon Web Services before, or haven’t looked at Alexandria yet, and you enjoy discovering new capabilities with PL/SQL I think you’ll find this interesting.
The powerpoint slides and demo script are now available on my Presentations page.
In late October I’ll be speaking at the 20:20 Foresight Perth Conference – more details later.
What’s the biggest clue you can give that your database is vulnerable to SQL injection? When your list of “forbidden words” looks suspiciously like a sample of SQL / PL/SQL keywords:
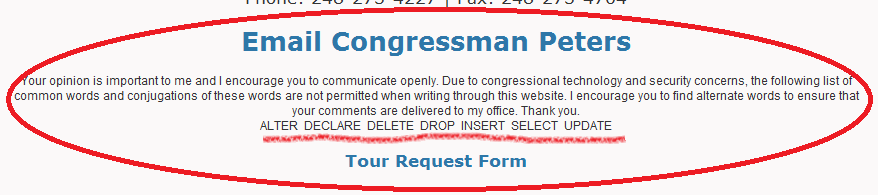
I notice that they haven’t forbidden BEGIN, CREATE, MERGE, or TRUNCATE …
Congressman Peters, your IT staff are doing it wrong.
Via: http://thedailywtf.com/Articles/Out-of-Service.aspx#pic4
The final day at Burswood was just as enjoyable as day one. Well done to all the AUSOUG committee!
I started with two APEX talks – first, Scott Wesley on APEX 4.1 Security. Personally I very much enjoyed the unique presentation style. You can experience it for yourself here. After that, Mark Lancaster from Queensland gave his analysis of the changes from APEX 4.0 to 4.1, and commented on a number of new features that have been added or improved.
Just before lunch I caught “Tips and Best Practices for DBAs” by Francisco Munoz Alvarez, who spoke less about actual DBA tasks (as I was expecting) but more about the “soft” skills – attitude, professionalism, working in a team, delegating tasks, and automating everything.
After lunch Vinod Patel moderated a discussion panel comprising Debra Lilley, Tim Hall, Connor McDonald, Penny Cookson, Chris Muir, and a guy from Oracle (whose name escapes me for the moment) – and they were plied with many questions about the art of presenting. It was encouraging to hear what they had to say, both about their success and their failure stories. I think I got away with taking this photo without them noticing 🙂

I took in Graham Wood‘s final presentation, a live demo of Exadata. He demonstrated how blazingly fast it is for loading huge amounts of data in a very short time (e.g. 500GB in about 10 minutes IIRC) and running horrible queries even faster (e.g. multiple full table scans with self joins, running in mere seconds). It was very impressive, although it did highlight that to get the full benefit of Exadata, some queries may need to be rewritten. For example, a big report you’re running now might get a modest x10 or x20 speed improvement on Exadata, but after rewriting you could get on the order of x100 to x200 speed improvements! If you don’t believe me, go ask Graham yourself 🙂
The day ended with Connor McDonald‘s talk, A Year in Purgatory – Diary of an 11.2 RAC Upgrade. It held a lot of promise, but unfortunately I was called away to an emergency at work so I missed most of it. I was quite disappointed to miss that one. By the way, Connor is now blogging – at connormcdonald.wordpress.com. Finally!
I’ve enjoyed each AUSOUG conference since 2000, and this year was one of the best in my opinion. It was great to catch up with colleagues, network with Oracle nerds and professionals, and get inspired by a variety of talks on topics I’m interested in.
In addition, the last few years I’ve also presented. This has been a good experience which I intend to continue. I hope that with practice I’ll get much better at it.
I had a most enjoyable* day today at the Oracle conference at Burswood, Perth.
* This is significant in light of the fact that the start of the day was quite hectic, having had to drop the car off to get a new alternator (the electrics died on the way home from work yesterday, so this morning I called RAC out to get the car started and charge the battery up a bit. I managed to drive the car within 100m of Ultratune, then it died completely. So I left the car in the traffic and walked the rest of the way, borrowed some kind of block box that was like a CPR machine for cars.), thereafter going with Rosalie to drop the eldest at her school, so she could then gift me a lift to Burswood.
I got to the conference in time to hear Graham Wood from Oracle talk about DB Time-based Oracle Performance Tuning, which was excellent, then Tim Hall on Edition-Based Redefinition which led to some excellent discussions with both Tim and colleagues from my current client.
My talk on a simple ETL method using just SQL seemed to go well and there were some good questions, comments and suggestions. If you missed something it was probably because I talk too fast – if you want to look something up from the talk you can look at the slides here, or have a play with a full SQL*Plus demo [ETL-by-SQL-sqlplus-demo.zip]. I also blogged about this technique back in February.
I finished the day with Graham Wood’s second talk, on Oracle Hidden Features – which indeed included info on some Oracle features that I’d either not yet come across, or had forgotten about. Doug Burns blogged about this presentation earlier. The bit about external tables, especially the new 11g feature for running the source file through a preprocessor, was particularly interesting.
I’m looking forward to the second day tomorrow.
 Just a quick note to draw attention to the lineup for AUSOUG National Conference – 3-4 November at the luxurious Burswood Resort here in Perth. The usual suspects will be there, for example:
Just a quick note to draw attention to the lineup for AUSOUG National Conference – 3-4 November at the luxurious Burswood Resort here in Perth. The usual suspects will be there, for example:
Signs of the coming Apocalypse? Who knows….
Plan your trip (and arrange your accommodation early, if you need it) and your conference schedule today!