DISCLAIMER: this article is based on Early Adopter 1.
I’ve finally got back to looking at my reference TAPI APEX application. I’ve greatly simplified it (e.g. removed the dependency on Logger, much as I wanted to keep it) and included one dependency (CSV_UTIL_PKG) to make it much simpler to install and try. The notice about compilation errors still applies: it is provided for information/entertainment purposes only and is not intended to be a fully working system. The online demo for APEX 5.0 has been updated accordingly.
I next turned my attention to APEX 5.1 Early Adopter, in which the most exciting feature is the all-new Interactive Grid which may replace IRs and tabular forms. I have installed my reference TAPI APEX application, everything still works fine without changes.
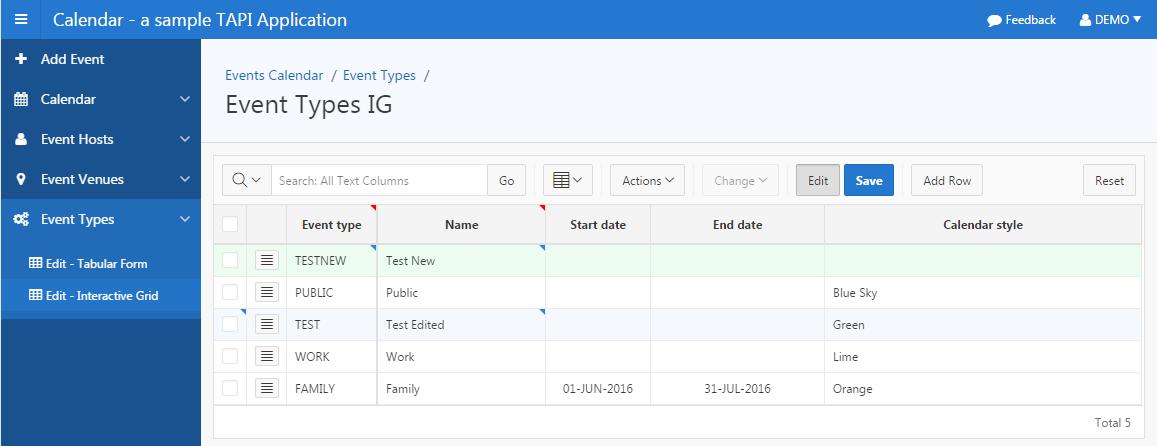
I wanted my sample application to include both the old Tabular Forms as well as the new Interactive Grid, so I started by making copies of some of my old “Grid Edit” (tabular form) pages. You will find these under the “Venues” and “Event Types” menus in the sample application. I then converted the tabular form regions to Interactive Grids, and after some fiddling have found that I need to make a small change to my APEX API to suit them. The code I wrote for the tabular forms doesn’t work for IGs; in fact, the new code is simpler, e.g.:
PROCEDURE apply_ig (rv IN VENUES$TAPI.rvtype) IS
r VENUES$TAPI.rowtype;
BEGIN
CASE v('APEX$ROW_STATUS')
WHEN 'I' THEN
r := VENUES$TAPI.ins (rv => rv);
sv('VENUE_ID', r.venue_id);
WHEN 'U' THEN
r := VENUES$TAPI.upd (rv => rv);
WHEN 'D' THEN
VENUES$TAPI.del (rv => rv);
END CASE;
END apply_ig;
You may notice a few things here:
(1) APEX$ROW_STATUS for inserted rows is ‘I’ instead of ‘C’; also, it is set to ‘D’ (unlike under tabular forms, where it isn’t set for deleted rows).
(2) After inserting a new record, the session state for the Primary Key column(s) must be set if the insert might have set them – including if the “Primary Key” in the region is ROWID. Otherwise, Apex 5.1 raises No Data Found when it tries to retrieve the new row.
(3) I did not have to make any changes to my TAPI at all 🙂
Here’s the example from my Event Types table, which doesn’t have a surrogate key, so we use ROWID instead:
PROCEDURE apply_ig (rv IN EVENT_TYPES$TAPI.rvtype) IS
r EVENT_TYPES$TAPI.rowtype;
BEGIN
CASE v('APEX$ROW_STATUS')
WHEN 'I' THEN
r := EVENT_TYPES$TAPI.ins (rv => rv);
sv('ROWID', r.p_rowid);
WHEN 'U' THEN
r := EVENT_TYPES$TAPI.upd (rv => rv);
WHEN 'D' THEN
EVENT_TYPES$TAPI.del (rv => rv);
END CASE;
END apply_ig;
Converting Tabular Form to Interactive Grid
The steps needed to convert a Tabular Form based on my APEX API / TAPI system are relatively straightforward, and only needed a small change to my APEX API.
- Select the Tabular Form region
- Change Type from “Tabular Form [Legacy]” to “Interactive Grid”
- Delete any Region Buttons that were associated with the Tabular form, such as CANCEL, MULTI_ROW_DELETE, SUBMIT, ADD
- Set the Page attribute Advanced > Reload on Submit = “Only for Success”
- Under region Attributes, set Edit > Enabled to “Yes”
- Set Edit > Lost Update Type = “Row Version Column”
- Set Edit > Row Version Column = “VERSION_ID”
- Set Edit > Add Row If Empty = “No”
- If your query already included ROWID, you will need to remove this (as the IG includes the ROWID automatically).
- If the table has a Surrogate Key, set the following attributes on the surrogate key column:
Identification > Type = “Hidden”
Source > Primary Key = “Yes”
- Also, if the table has a Surrogate Key, delete the generated ROWID column. Otherwise, leave it (it will be treated as the Primary Key by both the Interactive Grid as well as the TAPI).
- Set any columns Type = “Hidden” where appropriate (e.g. for Surrogate Key columns and VERSION_ID).
- Under Validating, create a Validation:
Editable Region = (your interactive grid region)
Type = “PL/SQL Function (returning Error Text)”
PL/SQL = (copy the suggested code from the generated Apex API package) e.g.
RETURN VENUES$TAPI.val (rv =>
VENUES$TAPI.rv
(venue_id => :VENUE_ID
,name => :NAME
,map_position => :MAP_POSITION
,version_id => :VERSION_ID
));
- Under Processing, edit the automatically generated “Save Interactive Grid Data” process:
Target Type = PL/SQL Code
PL/SQL = (copy the suggested code from the generated Apex API package) e.g.
VENUES$APEX.apply_ig (rv =>
VENUES$TAPI.rv
(venue_id => :VENUE_ID
,name => :NAME
,map_position => :MAP_POSITION
,version_id => :VERSION_ID
));
I like how the new Interactive Grid provides all the extra knobs and dials needed to interface cleanly with an existing TAPI implementation. For example, you can control whether it will attempt to Lock each Row for editing – and even allows you to supply Custom PL/SQL to implement the locking. Note that the lock is still only taken when the page is submitted (unlike Oracle Forms, which locks the record as soon as the user starts editing it) – which is why we need to prevent lost updates:
Preventing Lost Updates
The Interactive Grid allows the developer to choose the type of Lost Update protection (Row Values or Row Version Column). The help text for this attribute should be required reading for any database developer. In my case, I might choose to turn this off (by setting Prevent Lost Updates = “No” in the Save Interactive Grid Data process) since my TAPI already does this; in my testing, however, it didn’t hurt to include it.
Other little bits and pieces
I found it interesting that the converted Interactive Grid includes some extra columns automatically: APEX$ROW_SELECTOR (Type = Row Selector), APEX$ROW_ACTION (Type = Actions Menu), and ROWID. These give greater control over what gets included, and you can delete these if they are not required.
Another little gem is the new Column attribute Heading > Alternative Label: “Enter the alternative label to use in dialogs and in the Single Row View. Use an alternative label when the heading contains extra formatting, such as HTML tags, which do not display properly.”.
Demo
If you’d like to play with a working version of the reference application, it’s here (at least, until the EA is refreshed) (login as demo / demo):
http://apexea.oracle.com/pls/apex/f?p=SAMPLE560&c=JK64
I’ve checked in an export of this application to the bitbucket repository (f9674_ea1.sql).
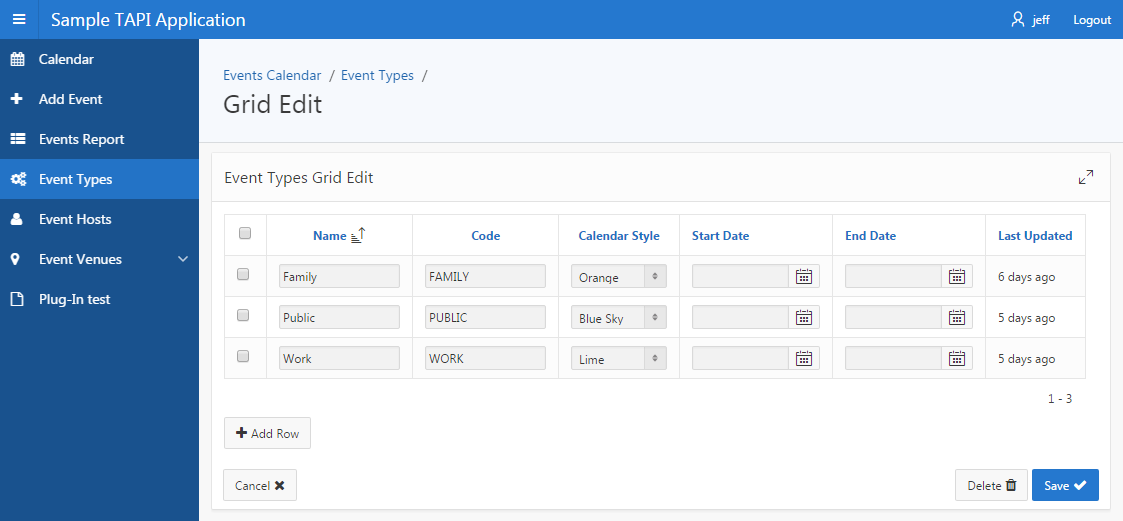
Ever since I started exploring the idea of using a TAPI approach with APEX, something I was never quite satisfied with was Tabular Forms.
They can be a bit finicky to work with, and if you’re not careful you can break them to the point where it’s easier to recreate them from scratch rather than try to fix them (although if you understand the underlying mechanics you can fix them [there was an article about this I read recently but I can’t find it now]).
I wanted to use the stock-standard APEX tabular form, rather than something like Martin D’Souza’s approach – although I have used that a number of times with good results.
In the last week or so while making numerous improvements to my TAPI generator, and creating the new APEX API generator, I tackled again the issue of tabular forms. I had a form that was still using the built-in APEX ApplyMRU and ApplyMRD processes (which, of course, bypass my TAPI). I found that if I deleted both of these processes, and replaced them with a single process that loops over the APEX_APPLICATION.g_f0x arrays, I lose a number of Tabular Form features such as detecting which records were changed.
Instead, what ended up working (while retaining all the benefits of a standard APEX tabular form) was to create a row-level process instead. Here’s some example code that I put in this APEX process that interfaces with my APEX API:
VENUES$APEX.apply_mr (rv =>
VENUES$TAPI.rv
(venue_id => :VENUE_ID
,name => :NAME
,version_id => :VERSION_ID
));
The process has Execution Scope set to For Created and Modified Rows. It first calls my TAPI.rv function to convert the individual columns from the row into an rvtype record, which it then passes to the APEX API apply_mr procedure. The downside to this approach is that each record is processed separately – no bulk updates; however, tabular forms are rarely used to insert or update significant volumes of data anyway so I doubt this would be of practical concern. The advantage of using the rv function is that it means I don’t need to repeat all the column parameters for all my API procedures, making maintenance easier.
The other change that I had to make was ensure that any Hidden columns referred to in my Apply process must be set to Hidden Column (saves state) – in this case, the VERSION_ID column.
Here’s the generated APEX API apply_mr procedure:
PROCEDURE apply_mr (rv IN VENUES$TAPI.rvtype) IS
r VENUES$TAPI.rowtype;
BEGIN
log_start('apply_mr');
UTIL.check_authorization('Operator');
IF APEX_APPLICATION.g_request = 'MULTI_ROW_DELETE' THEN
IF v('APEX$ROW_SELECTOR') = 'X' THEN
VENUES$TAPI.del (rv => rv);
END IF;
ELSE
CASE v('APEX$ROW_STATUS')
WHEN 'C' THEN
r := VENUES$TAPI.ins (rv => rv);
WHEN 'U' THEN
r := VENUES$TAPI.upd (rv => rv);
ELSE
NULL;
END CASE;
END IF;
log_end;
EXCEPTION
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END apply_mr;
The code uses APEX$ROW_STATUS to determine whether to insert or update each record. If the Delete button was pressed, it checks APEX$ROW_SELECTOR to check that the record had been selected for delete – although it could skip that check since APEX seems to call the procedure for only the selected records anyway. The debug logs show APEX skipping the records that weren’t selected.
Now, before we run off gleefully inserting and updating records we should really think about validating them and reporting any errors to the user in a nice way. The TAPI ins and upd functions do run the validation routine, but they don’t set up UTIL with the mappings so that the APEX errors are registered as we need them to. So, we add a per-record validation in the APEX page that runs this:
VENUES$APEX.val_row (rv =>
VENUES$TAPI.rv
(venue_id => :VENUE_ID
,name => :NAME
,version_id => :VERSION_ID
)
,region_static_id => 'venues');
RETURN null;
As for the single-record page, this validation step is of type PL/SQL Function (returning Error Text). Its Execution Scope is the same as for the apply_mr process – For Created and Modified Rows.
Note that we need to set a static ID on the tabular form region (the generator assumes it is the table name in lowercase – e.g. venues – but this can be changed if desired).
The val_row procedure is as follows:
PROCEDURE val_row
(rv IN VENUES$TAPI.rvtype
,region_static_id IN VARCHAR2
) IS
dummy VARCHAR2(32767);
column_alias_map UTIL.str_map;
BEGIN
log_start('val_row');
UTIL.pre_val_row
(label_map => VENUES$TAPI.label_map
,region_static_id => region_static_id
,column_alias_map => column_alias_map);
dummy := VENUES$TAPI.val (rv => rv);
UTIL.post_val;
log_end;
EXCEPTION
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END val_row;
The pre_val_row procedure tells all the validation handlers how to register any error message with APEX_ERROR. In this case, column_alias_map is empty, which causes them to assume that each column name in the tabular form is named the same as the column name on the database. If this default mapping is not correct for a particular column, we can declare the mapping, e.g. column_alias_map('DB_COLUMN_NAME') := 'TABULAR_FORM_COLUMN_NAME';. This way, when the errors are registered with APEX_ERROR they will be shown correctly on the APEX page.
Things got a little complicated when I tried using this approach for a table that didn’t have any surrogate key, where my TAPI uses ROWID instead to uniquely identify a row for update. In this case, I had to change the generated query to include the ROWID, e.g.:
SELECT t.event_type
,t.name
,t.calendar_css
,t.start_date
,t.end_date
,t.last_updated_dt
,t.version_id
,t.ROWID AS p_rowid
FROM event_types t
I found if I didn’t give a different alias for ROWID, the tabular form would not be rendered at runtime as it conflicted with APEX trying to get its own version of ROWID from the query. Note that the P_ROWID must also be set to Hidden Column (saves state). I found it strange that APEX would worry about it because when I removed* the ApplyMRU and ApplyMRD processes, it stopped emitting the ROWID in the frowid_000n hidden items. Anyway, giving it the alias meant that it all worked fine in the end.
* CORRECTION (7/11/2016): Don’t remove the ApplyMRU process, instead mark it with a Condition of “Never” – otherwise APEX will be unable to map errors to the right rows in the tabular form.
The Add Rows button works; also, the Save button correctly calls my TAPI only for inserted and updated records, and shows error messages correctly. I can use APEX’s builtin Tabular Form feature, integrated neatly with my TAPI instead of manipulating the table directly. Mission accomplished.
Source code/download: http://bitbucket.org/jk64/jk64-sample-apex-tapi
 Some time back, Connor rightly pointed out that triggers that modify data can get in the way when you need to do out-of-the-ordinary data maintenance, e.g. when you need to fix up a row here or re-insert a row over there. You can’t just disable the trigger or else make your users suffer down-time.
Some time back, Connor rightly pointed out that triggers that modify data can get in the way when you need to do out-of-the-ordinary data maintenance, e.g. when you need to fix up a row here or re-insert a row over there. You can’t just disable the trigger or else make your users suffer down-time.
Now, the only purpose for which I use triggers is to do common things like setting audit columns and incrementing a VERSION_ID column, and in certain special cases for carefully implementing cross-row constraints; also, I use them to populate a journal table with all changes to the table. Mind you, in recent times features have been added and improved in the Oracle database (such as Flashback Query and Flashback Data Archive) to the point where I’m almost ready to stop doing this. However, there are still some minor use-cases where having a separate “journal” table can be useful. Any argument about that assertion is ruled “out of scope” for this article! 🙂
So, assuming we’re sticking with triggers that might change data, a solution to this problem is already built-in to the journal triggers and Table APIs (TAPI) that my PL/SQL code generator creates. This allows me to disable the trigger on any table, just for my current session without affecting any other concurrent activity – and no DDL required.
UPDATED 16/2/2016: now uses a context variable (thanks Connor for the idea)
In the trigger I have this code:
create or replace TRIGGER EMPS$TRG
FOR INSERT OR UPDATE OR DELETE ON EMPS
COMPOUND TRIGGER
BEFORE EACH ROW IS
BEGIN
IF SYS_CONTEXT('SAMPLE_CTX','EMPS$TRG') IS NULL THEN
...etc...
END IF;
END BEFORE EACH ROW;
AFTER EACH ROW IS
BEGIN
IF SYS_CONTEXT('SAMPLE_CTX','EMPS$TRG') IS NULL THEN
...etc...
END IF;
END AFTER EACH ROW;
END EMPS$TRG;
The trigger takes advantage of some extra code that is generated in the Table API:
create or replace PACKAGE EMPS$TAPI AS
/***********************************************
Table API for emps
10-FEB-2016 - Generated by SAMPLE
***********************************************/
...
-- Use these procedures to disable and re-enable the
-- journal trigger just for this session (to disable for
-- all sessions, just disable the database trigger
-- instead).
PROCEDURE disable_journal_trigger;
PROCEDURE enable_journal_trigger;
END EMPS$TAPI;
The package body code is quite simple:
create or replace PACKAGE BODY EMPS$TAPI AS
/***********************************************
Table API for emps
10-FEB-2016 - Generated by SAMPLE
***********************************************/
...
-- may be used to disable and re-enable the journal trigger for this session
PROCEDURE disable_journal_trigger IS
BEGIN
log_start('disable_journal_trigger');
SECURITY.disable_journal_trigger('EMPS$TRG');
log_end;
EXCEPTION
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END disable_journal_trigger;
PROCEDURE enable_journal_trigger IS
BEGIN
log_start('enable_journal_trigger');
SECURITY.enable_journal_trigger('EMPS$TRG');
log_end;
EXCEPTION
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END enable_journal_trigger;
END EMPS$TAPI;
A context variable is set with the name of the trigger to disable it – the default state for a new session (i.e. the context variable not set) means the trigger is enabled.
create or replace PACKAGE BODY SECURITY AS
...
PROCEDURE disable_journal_trigger
(trigger_name IN VARCHAR2
,client_id IN VARCHAR2 := NULL) IS
BEGIN
-- set the context to any non-null value
DBMS_SESSION.set_context
(namespace => 'SAMPLE_CTX'
,attribute => trigger_name
,value => 'DISABLED'
,client_id => NVL(client_id, SYS_CONTEXT('USERENV','CLIENT_IDENTIFIER')));
END disable_journal_trigger;
PROCEDURE enable_journal_trigger
(trigger_name IN VARCHAR2
,client_id IN VARCHAR2 := NULL) IS
BEGIN
-- clear the context
DBMS_SESSION.clear_context
(namespace => 'SAMPLE_CTX'
,attribute => trigger_name
,client_id => NVL(client_id, SYS_CONTEXT('USERENV','CLIENT_IDENTIFIER')));
END enable_journal_trigger;
END SECURITY;
So now, to run some data maintenance, I can simply call the TAPI to disable, then re-enable, the trigger:
BEGIN EMPS$TAPI.disable_journal_trigger; END;
/
... do the data maintenance...
BEGIN EMPS$TAPI.enable_journal_trigger; END;
/
Unless the data maintenance is doing something very unusual, this script should be safe to run while the system is still up and running for users.
Also, it would be a trivial exercise to write a routine which disables or enables all the journal triggers at once.
The point of this, of course, is that you should be able to do all this sort of thing without writing a lot of code for each table in your schema – solve it for one table, and then generate the code for all your tables.
Source code/download: http://bitbucket.org/jk64/jk64-sample-apex-tapi
If you create an APEX form based on a table, APEX automatically creates processes of type Automatic Row Fetch and Automatic Row Processing (DML) as well as one item for each column in the table, each bound to the database column via its Source Type. This design is excellent as it’s fully declarative and is very quick and easy to build a data entry page for all your tables.
The downside to this approach is that if you want to use a Table API (TAPI) to encapsulate all DML activity on your tables, you need to write a whole lot of code to replace the processes that Apex created for you. In order to mitigate this as much as possible, I’ve augmented my code generator with an “APEX API” generator. This generates a second package for each table which can be called from APEX, which in turn calls the TAPI to run the actual DML. In addition, the validations that are performed by the TAPI are translated back into APEX Errors so that they are rendered in much the same way as built-in APEX validations.
Probably the best way to explain this is to show an example. Here’s my EMPS table (same as from my last article):
CREATE TABLE emps
(emp_id NUMBER NOT NULL
,name VARCHAR2(100 CHAR) NOT NULL
,emp_type VARCHAR2(20 CHAR) DEFAULT 'SALARIED' NOT NULL
,start_date DATE NOT NULL
,end_date DATE
,dummy_ts TIMESTAMP(6)
,dummy_tsz TIMESTAMP(6) WITH TIME ZONE
,life_history CLOB
,CONSTRAINT emps_pk PRIMARY KEY ( emp_id )
,CONSTRAINT emps_name_uk UNIQUE ( name )
,CONSTRAINT emp_type_ck
CHECK ( emp_type IN ('SALARIED','CONTRACTOR')
);
CREATE SEQUENCE emp_id_seq;
By the way, my table creation script calls DEPLOY.create_table to do this, which automatically adds my standard audit columns to the table – CREATED_BY, CREATED_DT, LAST_UPDATED_BY, LAST_UPDATED_DT, and VERSION_ID. My script also calls GENERATE.journal for the table which creates a journal table (EMPS$JN) and a trigger (EMPS$TRG) to log all DML activity against the table.
I then call GENERATE.tapi which creates the Table API (EMPS$TAPI) which has routines for validating, inserting, updating and deleting rows (or arrays of rows using bulk binds) of the EMPS table.
Finally, I call GENERATE.apexapi which creates the APEX API (EMPS$APEX) which looks like this:
Package Spec: EMPS$APEX
create or replace PACKAGE EMPS$APEX AS
/**************************************************
Apex API for emps
10-FEB-2016 - Generated by SAMPLE
**************************************************/
-- page load process
PROCEDURE load;
-- single-record page validation
PROCEDURE val;
-- page submit process
PROCEDURE process;
END EMPS$APEX;
Notice that these routines require no parameters; the API gets all the data it needs directly from APEX.
Package Body: EMPS$APEX
create or replace PACKAGE BODY EMPS$APEX AS
/*******************************************************************************
Table API for emps
10-FEB-2016 - Generated by SAMPLE
*******************************************************************************/
PROCEDURE apex_set (r IN EMPS$TAPI.rowtype) IS
p VARCHAR2(10) := 'P' || UTIL.apex_page_id || '_';
BEGIN
log_start('apex_set');
sv(p||'EMP_ID', r.emp_id);
sv(p||'NAME', r.name);
sv(p||'EMP_TYPE', r.emp_type);
sd(p||'START_DATE', r.start_date);
sd(p||'END_DATE', r.end_date);
st(p||'BLA_TSZ', r.bla_tsz);
st(p||'DUMMY_TS', r.dummy_ts);
sv(p||'CREATED_BY', r.created_by);
sd(p||'CREATED_DT', r.created_dt);
sv(p||'LAST_UPDATED_BY', r.last_updated_by);
sd(p||'LAST_UPDATED_DT', r.last_updated_dt);
sv(p||'VERSION_ID', r.version_id);
log_end;
EXCEPTION
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END apex_set;
FUNCTION apex_get RETURN EMPS$TAPI.rvtype IS
p VARCHAR2(10) := 'P' || UTIL.apex_page_id || '_';
rv EMPS$TAPI.rvtype;
BEGIN
log_start('apex_get');
rv.emp_id := nv(p||'EMP_ID');
rv.name := v(p||'NAME');
rv.emp_type := v(p||'EMP_TYPE');
rv.start_date := v(p||'START_DATE');
rv.end_date := v(p||'END_DATE');
rv.bla_tsz := v(p||'BLA_TSZ');
rv.dummy_ts := v(p||'DUMMY_TS');
rv.version_id := nv(p||'VERSION_ID');
log_end;
RETURN rv;
EXCEPTION
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END apex_get;
FUNCTION apex_get_pk RETURN EMPS$TAPI.rvtype IS
p VARCHAR2(10) := 'P' || UTIL.apex_page_id || '_';
rv EMPS$TAPI.rvtype;
BEGIN
log_start('apex_get_pk');
IF APEX_APPLICATION.g_request = 'COPY' THEN
rv.emp_id := v(p||'COPY_EMP_ID');
ELSE
rv.emp_id := nv(p||'EMP_ID');
rv.version_id := nv(p||'VERSION_ID');
END IF;
log_end;
RETURN rv;
EXCEPTION
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END apex_get_pk;
/*******************************************************************************
PUBLIC INTERFACE
*******************************************************************************/
PROCEDURE load IS
p VARCHAR2(10) := 'P' || UTIL.apex_page_id || '_';
rv EMPS$TAPI.rvtype;
r EMPS$TAPI.rowtype;
BEGIN
log_start('load');
UTIL.check_authorization('Reporting');
rv := apex_get_pk;
r := EMPS$TAPI.get (emp_id => rv.emp_id);
IF APEX_APPLICATION.g_request = 'COPY' THEN
r := EMPS$TAPI.copy(r);
END IF;
apex_set (r => r);
log_end;
EXCEPTION
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END load;
PROCEDURE val IS
p VARCHAR2(10) := 'P' || UTIL.apex_page_id || '_';
rv EMPS$TAPI.rvtype;
dummy VARCHAR2(32767);
item_name_map UTIL.str_map;
BEGIN
log_start('val');
IF APEX_APPLICATION.g_request = 'CREATE'
OR APEX_APPLICATION.g_request LIKE 'SAVE%' THEN
rv := apex_get;
UTIL.pre_val
(label_map => EMPS$TAPI.label_map
,item_name_map => item_name_map);
dummy := EMPS$TAPI.val (rv => rv);
UTIL.post_val;
END IF;
log_end;
EXCEPTION
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END val;
PROCEDURE process IS
p VARCHAR2(10) := 'P' || UTIL.apex_page_id || '_';
rv EMPS$TAPI.rvtype;
r EMPS$TAPI.rowtype;
BEGIN
log_start('process');
UTIL.check_authorization('Operator');
CASE
WHEN APEX_APPLICATION.g_request = 'CREATE' THEN
rv := apex_get;
r := EMPS$TAPI.ins (rv => rv);
apex_set (r => r);
UTIL.success('Emp created.');
WHEN APEX_APPLICATION.g_request LIKE 'SAVE%' THEN
rv := apex_get;
r := EMPS$TAPI.upd (rv => rv);
apex_set (r => r);
UTIL.success('Emp updated.'
|| CASE WHEN APEX_APPLICATION.g_request = 'SAVE_COPY'
THEN ' Ready to create new emp.'
END);
WHEN APEX_APPLICATION.g_request = 'DELETE' THEN
rv := apex_get_pk;
EMPS$TAPI.del (rv => rv);
UTIL.clear_page_cache;
UTIL.success('Emp deleted.');
END CASE;
log_end;
EXCEPTION
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END process;
END EMPS$APEX;
Now, given the above package, we can create an APEX page that allows users to view, create, update, copy and delete a record from the EMPS table, using all the features provided by our TAPI.
- Create Page, select Form, select Form on a Table or view, select the table EMPS.
- Accept the defaults, or change them to taste, and click Next, Next.
- On the Primary Key wizard step, change type to Select Primary Key Column(s) and it should pick up the EMP_ID column automatically. Click Next.*
- For Source Type, leave the default (Existing trigger).** Click Next, Next, Next.
- For Branching, enter page numbers as required. Click Next, then Create.
* the APEX API and Table API generator also handles tables with no surrogate key by using ROWID instead; in this case, you would leave the default option selected (Managed by Database (ROWID)) here.
** note however that our TAPI will handle the sequence generation, not a trigger.
The page should look something like this:
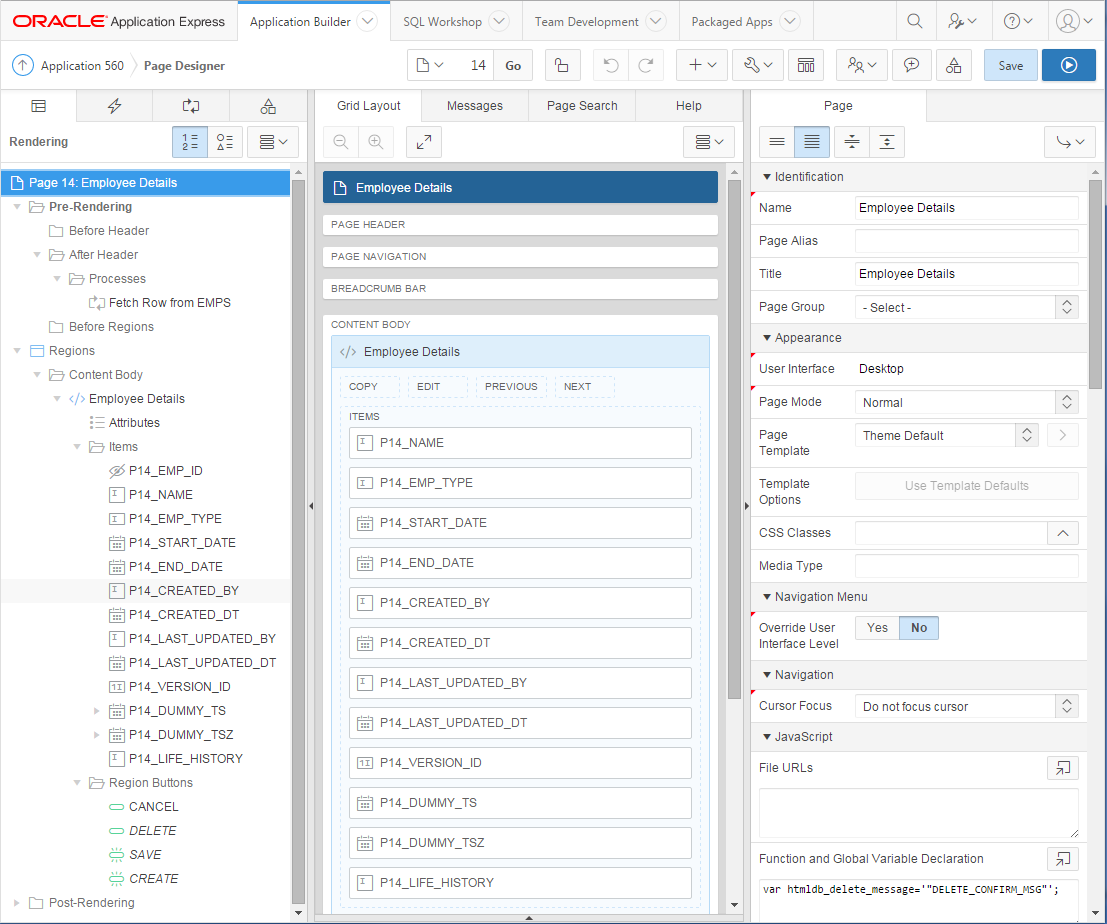
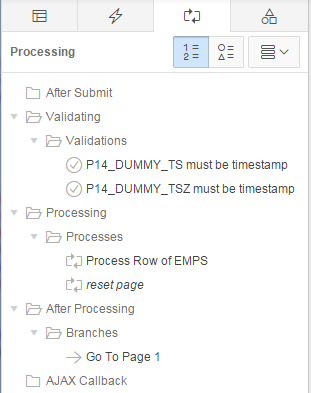
Notice that it has created a Fetch Row from EMPS process for when the page is loaded, as well as the Process Row of EMPS and reset page processes for when the page is submitted. It has also created a few validations.
Notice also that all the items are named consistently with the column names; this is important as my APEX API package generator relies on this one-to-one mapping. You can, of course, add additional non-database items to the page – they won’t be affected by the generator unless the table is altered with columns that match.
Now, this page will work fine, except that it bypasses our TAPI. To change the page so that it uses our TAPI instead, edit the page as follows:
- Delete all the Fetch Row from EMPS, Process Row of EMPS and reset page processes.
- Delete all the validations.
- For all the page items, set Source Type to Null. In Apex 5 this is easy – just Ctrl+Click each item, then make the change to all of them in one step!
- Make the audit column items (CREATED_BY, CREATED_DT, LAST_UPDATED_BY, LAST_UPDATED_DT) Display Only.
- Make the VERSION_ID item Hidden.
- Under Pre-Rendering, add an After Header process that calls
EMPS$APEX.load;.
- In the Page Processing tab, under Validating, add a validation with Type = PL/SQL Function (returning Error Text).
- Set the PL/SQL Function Body Returning Error Text to
EMPS$APEX.val; RETURN null;.
- Set Error Message to “bla” (this is a mandatory field but is never used – I think this is a small bug in Apex 5).
- Under Processing, add a process that calls
EMPS$APEX.process;.
- Set Error Message to
#SQLERRM_TEXT#.
Run the page – you should find that it works just as well as before, with all the TAPI goodness working behind the scenes. Even the validations work, and they will point at the right items on the page.
But that’s not all! You can easily add a useful “Copy” function that your users will thank you for because (depending on the use case) it can reduce the amount of typing they have to do.
- Add a button to the region, named SAVE_COPY (this name is important) with the label Copy. Tip: if you want an icon set the Icon CSS Classes to fa-copy.
- Add a hidden item named after the PK item prefixed with “COPY_”, e.g.
P14_COPY_EMP_ID.
- Under After Processing, add a Branch that goes to this same page (e.g. 14, in this example).
- On the branch, set Request (under Advanced) to COPY and assign
&P14_EMP_ID. to the item P14_COPY_EMP_ID.
- Set When Button Pressed to SAVE_COPY.
- Change the order of the branches so that the Copy branch is evaluated before the other branches (see below)
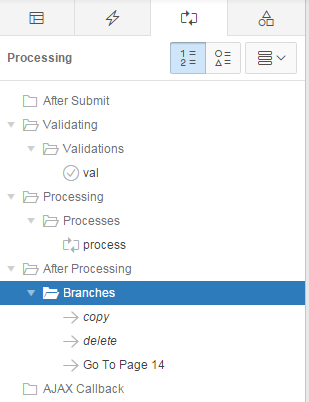
Now, when they click Copy, the page will first save any changes they had made to the record, then go back to the same page with a copy of all the details from the original record. The user can then edit the new record and Create it if they so desire, or Cancel.
An advantage of this design is that, if you want to add a validation that applies whether someone is updating the table from APEX or from some other UI or interface, you can add it in one place – the TAPI (specifically, you would add it to the TAPI template). If you add a column, just add an item to the APEX page and regenerate the TAPI and Apex API. It’s a nice DRY-compliant solution.
Addendum: you may be wondering why we need a P14_COPY_EMP_ID item, instead of simply reusing the P14_EMP_ID item that’s already there. The reason for this is that after saving a copied record, in some cases we may want to copy some or all the child records from the original record to the copy, or do some other operation that needs both the old and the new ID.
Source code/download: https://github.com/jeffreykemp/jk64-sample-apex-xapi
 The last few weeks I’ve made quite a few improvements to my TAPI generator which I thought I’d share. I’ve also added an Apex API generator which generates code suitable for interfacing between simple Apex applications and my TAPIs. This reduces the volume of PL/SQL required within Apex to a bare minimum.
The last few weeks I’ve made quite a few improvements to my TAPI generator which I thought I’d share. I’ve also added an Apex API generator which generates code suitable for interfacing between simple Apex applications and my TAPIs. This reduces the volume of PL/SQL required within Apex to a bare minimum.
- Templates are now defined in a package spec, so they are easier to edit in a tool with syntax highlighting (more or less)
- Most dynamic code generation is defined within the template using a simple syntax
- Makes inferences from schema metadata to generate code, including some guesses based on object and column naming conventions.
- Ability to insert table-specific code into the template so that it is retained after re-generating the TAPI.
- As much as possible, allow generated code to follow my preferred code formatting rules as possible.
- The Table API (“TAPI”) package defines two record types; one (rowtype) is based on the table, the other (rvtype) uses mostly VARCHAR2(4000) columns in order to hold a pre-validated record.
Assumptions
My generator makes the following assumptions:
- All tables and columns are named non-case-sensitive, i.e. no double-quote delimiters required.
- (APEX API) All columns are max 26 chars long (in order to accommodate the Apex “P99_…” naming convention)
- (APEX API) Table has no more than 1 CLOB, 1 BLOB and 1 XMLTYPE column (in order to support conversion to/from Apex collections)
If any of the above do not hold true, the TAPI will probably need to be manually adjusted to work. All TAPIs generated should be reviewed prior to use anyway.
Example
For example, given the following schema:
CREATE TABLE emps
(emp_id NUMBER NOT NULL
,name VARCHAR2(100 CHAR) NOT NULL
,emp_type VARCHAR2(20 CHAR) DEFAULT 'SALARIED' NOT NULL
,start_date DATE NOT NULL
,end_date DATE
,dummy_ts TIMESTAMP(6)
,dummy_tsz TIMESTAMP(6) WITH TIME ZONE
,life_history CLOB
,CONSTRAINT emps_pk PRIMARY KEY ( emp_id )
,CONSTRAINT emps_name_uk UNIQUE ( name )
,CONSTRAINT emp_type_ck
CHECK ( emp_type IN ('SALARIED','CONTRACTOR')
);
CREATE SEQUENCE emp_id_seq;
I can run this:
BEGIN GENERATE.tapi('emps'); END;
/
This generates the following package (I’ve removed large portions, the full version is linked below):
create or replace PACKAGE EMPS$TAPI AS
/**********************************************************
Table API for emps
10-FEB-2016 - Generated by SAMPLE
**********************************************************/
SUBTYPE rowtype IS emps%ROWTYPE;
TYPE arraytype IS TABLE OF rowtype INDEX BY BINARY_INTEGER;
TYPE rvtype IS RECORD
(emp_id emps.emp_id%TYPE
,name VARCHAR2(4000)
,emp_type VARCHAR2(4000)
,start_date VARCHAR2(4000)
,end_date VARCHAR2(4000)
,dummy_ts VARCHAR2(4000)
,dummy_tsz VARCHAR2(4000)
,life_history emps.life_history%TYPE
,version_id emps.version_id%TYPE
);
TYPE rvarraytype IS TABLE OF rvtype INDEX BY BINARY_INTEGER;
-- validate the row (returns an error message if invalid)
FUNCTION val (rv IN rvtype) RETURN VARCHAR2;
-- insert a row
FUNCTION ins (rv IN rvtype) RETURN rowtype;
-- insert multiple rows, array may be sparse
-- returns no. records inserted
FUNCTION bulk_ins (arr IN rvarraytype) RETURN NUMBER;
$if false $then/*need to grant DBMS_CRYPTO*/
-- generate a hash for the record
FUNCTION hash (r IN rowtype) RETURN VARCHAR2;
$end
...
END EMPS$TAPI;
create or replace PACKAGE BODY EMPS$TAPI AS
/**********************************************************
Table API for emps
10-FEB-2016 - Generated by SAMPLE
**********************************************************/
FUNCTION val (rv IN rvtype) RETURN VARCHAR2 IS
-- Validates the record but without reference to any other rows or tables
-- (i.e. avoid any queries in here).
-- Unique and referential integrity should be validated via suitable db
-- constraints (violations will be raised when the ins/upd/del is attempted).
-- Complex cross-record validations should usually be performed by a XAPI
-- prior to the call to the TAPI.
BEGIN
log_start('val');
UTIL.val_not_null (val => rv.name, column_name => 'NAME');
UTIL.val_not_null (val => rv.emp_type, column_name => 'EMP_TYPE');
UTIL.val_not_null (val => rv.start_date, column_name => 'START_DATE');
UTIL.val_max_len (val => rv.name, len => 100, column_name => 'NAME');
UTIL.val_max_len (val => rv.emp_type, len => 20, column_name => 'EMP_TYPE');
UTIL.val_date (val => rv.start_date, column_name => 'START_DATE');
UTIL.val_date (val => rv.end_date, column_name => 'END_DATE');
UTIL.val_timestamp (val => rv.dummy_ts, column_name => 'DUMMY_TS');
UTIL.val_timestamp_tz (val => rv.dummy_tsz, column_name => 'DUMMY_TSZ');
--TODO: add more validations if necessary
log_end;
RETURN UTIL.first_error;
EXCEPTION
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END val;
FUNCTION ins (rv IN rvtype) RETURN rowtype IS
r rowtype;
error_msg VARCHAR2(32767);
BEGIN
log_start('ins');
error_msg := val (rv => rv);
IF error_msg IS NOT NULL THEN
raise_error(error_msg);
END IF;
INSERT INTO emps
(emp_id
,name
,emp_type
,start_date
,end_date
,dummy_ts
,dummy_tsz
,life_history)
VALUES(emp_id_seq.NEXTVAL
,rv.name
,rv.emp_type
,UTIL.date_val(rv.start_date)
,UTIL.date_val(rv.end_date)
,UTIL.timestamp_val(rv.dummy_ts)
,UTIL.timestamp_tz_val(rv.dummy_tsz)
,rv.life_history)
RETURNING
emp_id
,name
,emp_type
,start_date
,end_date
,dummy_ts
,dummy_tsz
,life_history
,created_by
,created_dt
,last_updated_by
,last_updated_dt
,version_id
INTO r.emp_id
,r.name
,r.emp_type
,r.start_date
,r.end_date
,r.dummy_ts
,r.dummy_tsz
,r.life_history
,r.created_by
,r.created_dt
,r.last_updated_by
,r.last_updated_dt
,r.version_id;
msg('INSERT emps: ' || SQL%ROWCOUNT);
log_end;
RETURN r;
EXCEPTION
WHEN DUP_VAL_ON_INDEX THEN
UTIL.raise_dup_val_on_index;
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END ins;
FUNCTION bulk_ins (arr IN rvarraytype) RETURN NUMBER IS
rowcount NUMBER;
BEGIN
log_start('bulk_ins');
bulk_val(arr);
FORALL i IN INDICES OF arr
INSERT INTO emps
(emp_id
,name
,emp_type
,start_date
,end_date
,dummy_ts
,dummy_tsz
,life_history)
VALUES (emp_id_seq.NEXTVAL
,arr(i).name
,arr(i).emp_type
,UTIL.date_val(arr(i).start_date)
,UTIL.date_val(arr(i).end_date)
,UTIL.timestamp_val(arr(i).dummy_ts)
,UTIL.timestamp_tz_val(arr(i).dummy_tsz)
,arr(i).life_history);
rowcount := SQL%ROWCOUNT;
msg('INSERT emps: ' || rowcount);
log_end('rowcount=' || rowcount);
RETURN rowcount;
EXCEPTION
WHEN DUP_VAL_ON_INDEX THEN
UTIL.raise_dup_val_on_index;
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END bulk_ins;
$if false $then/*need to grant DBMS_CRYPTO*/
FUNCTION hash (r IN rowtype) RETURN VARCHAR2 IS
sep CONSTANT VARCHAR2(1) := '|';
digest CLOB;
ret RAW(2000);
BEGIN
log_start('hash');
digest := digest || sep || r.emp_id;
digest := digest || sep || r.name;
digest := digest || sep || r.emp_type;
digest := digest || sep || TO_CHAR(r.start_date, UTIL.DATE_FORMAT);
digest := digest || sep || TO_CHAR(r.end_date, UTIL.DATE_FORMAT);
digest := digest || sep || TO_CHAR(r.dummy_ts, UTIL.TIMESTAMP_FORMAT);
digest := digest || sep || TO_CHAR(r.dummy_tsz, UTIL.TIMESTAMP_TZ_FORMAT);
ret := DBMS_CRYPTO.hash(digest, DBMS_CRYPTO.hash_sh1);
log_end(ret);
RETURN ret;
EXCEPTION
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END hash;
$end
...
END EMPS$TAPI;
Example Template
The following is a template which provides the source used to generate the above TAPI. The syntax may look very strange, but if you read on you can read my explanation of the syntax below. My goal was not to invent an all-singing all-dancing general-purpose syntax for code generation – but to have “just enough” expressive power to generate the kind of code I require.
create or replace PACKAGE TEMPLATES AS
$if false $then
<%TEMPLATE TAPI_PACKAGE_SPEC>
CREATE OR REPLACE PACKAGE #TAPI# AS
/**********************************************************
Table API for #table#
#SYSDATE# - Generated by #USER#
**********************************************************/
<%IF EVENTS>
/*Repeat Types*/
DAILY CONSTANT VARCHAR2(100) := 'DAILY';
WEEKLY CONSTANT VARCHAR2(100) := 'WEEKLY';
MONTHLY CONSTANT VARCHAR2(100) := 'MONTHLY';
ANNUALLY CONSTANT VARCHAR2(100) := 'ANNUALLY';
<%END IF>
SUBTYPE rowtype IS #table#%ROWTYPE;
TYPE arraytype IS TABLE OF rowtype INDEX BY BINARY_INTEGER;
TYPE rvtype IS RECORD
(<%COLUMNS EXCLUDING AUDIT INCLUDING ROWID,EVENTS.REPEAT_IND>
#col#--- VARCHAR2(4000)~
#col#--- #table#.#col#%TYPE{ID}~
#col#--- #table#.#col#%TYPE{LOB}~
#col#--- VARCHAR2(20){ROWID}~
#col#--- VARCHAR2(1){EVENTS.REPEAT_IND}~
,<%END>
);
TYPE rvarraytype IS TABLE OF rvtype INDEX BY BINARY_INTEGER;
-- validate the row (returns an error message if invalid)
FUNCTION val (rv IN rvtype) RETURN VARCHAR2;
-- insert a row
FUNCTION ins (rv IN rvtype) RETURN rowtype;
-- insert multiple rows, array may be sparse; returns no. records inserted
FUNCTION bulk_ins (arr IN rvarraytype) RETURN NUMBER;
...
<%IF DBMS_CRYPTO><%ELSE>$if false $then/*need to grant DBMS_CRYPTO*/<%END IF>
-- generate a hash for the record
FUNCTION hash (r IN rowtype) RETURN VARCHAR2;
<%IF DBMS_CRYPTO><%ELSE>$end<%END IF>
END #TAPI#;
<%END TEMPLATE>
<%TEMPLATE TAPI_PACKAGE_BODY>
CREATE OR REPLACE PACKAGE BODY #TAPI# AS
/**********************************************************
Table API for #table#
#SYSDATE# - Generated by #USER#
**********************************************************/
FUNCTION val (rv IN rvtype) RETURN VARCHAR2 IS
-- Validates the record but without reference to any other rows or tables
-- (i.e. avoid any queries in here).
-- Unique and referential integrity should be validated via suitable db
-- constraints (violations will be raised when the ins/upd/del is attempted).
-- Complex cross-record validations should usually be performed by a XAPI
-- prior to the call to the TAPI.
BEGIN
log_start('val');
<%COLUMNS EXCLUDING GENERATED,SURROGATE_KEY,NULLABLE>
UTIL.val_not_null (val => rv.#col#, column_name => '#COL#');~
<%END>
<%IF EVENTS>
IF rv.repeat_ind = 'Y' THEN
UTIL.val_not_null (val => rv.repeat, column_name => 'REPEAT');
UTIL.val_not_null (val => rv.repeat_interval, column_name => 'REPEAT_INTERVAL');
END IF;
<%END IF>
<%COLUMNS EXCLUDING GENERATED,SURROGATE_KEY,LOBS INCLUDING EVENTS.REPEAT_IND>
UTIL.val_ind (val => rv.#col#, column_name => '#COL#');{IND}~
UTIL.val_yn (val => rv.#col#, column_name => '#COL#');{YN}~
UTIL.val_max_len (val => rv.#col#, len => #MAXLEN#, column_name => '#COL#');{VARCHAR2}~
UTIL.val_numeric (val => rv.#col#, column_name => '#COL#');{NUMBER}~
UTIL.val_date (val => rv.#col#, column_name => '#COL#');{DATE}~
UTIL.val_datetime (val => rv.#col#, column_name => '#COL#');{DATETIME}~
UTIL.val_timestamp (val => rv.#col#, column_name => '#COL#');{TIMESTAMP}~
UTIL.val_timestamp_tz (val => rv.#col#, column_name => '#COL#');{TIMESTAMP_TZ}~
UTIL.val_integer (val => rv.#col#, range_low => 1, column_name => '#COL#');{EVENTS.REPEAT_INTERVAL}~
UTIL.val_domain
(val => rv.#col#
,valid_values => t_str_array(DAILY, WEEKLY, MONTHLY, ANNUALLY)
,column_name => '#COL#');{EVENTS.REPEAT}~
~
<%END>
<%IF EVENTS>
UTIL.val_datetime_range
(start_dt => rv.start_dt
,end_dt => rv.end_dt
,label => 'Event Date/Time Range');
<%END IF>
<%IF EVENT_TYPES>
UTIL.val_cond
(cond => rv.event_type = UPPER(rv.event_type)
,msg => 'Event Type Code must be all uppercase'
,column_name => 'EVENT_TYPE');
UTIL.val_cond
(cond => rv.event_type = TRANSLATE(rv.event_type,'X -:','X___')
,msg => 'Event Type Code cannot include spaces, dashes (-) or colons (:)'
,column_name => 'EVENT_TYPE');
UTIL.val_date_range
(start_date => rv.start_date
,end_date => rv.end_date
,label => 'Event Types Date Range');
<%END IF>
--TODO: add more validations if necessary
log_end;
RETURN UTIL.first_error;
EXCEPTION
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END val;
FUNCTION ins (rv IN rvtype) RETURN rowtype IS
r rowtype;
error_msg VARCHAR2(32767);
BEGIN
log_start('ins');
error_msg := val (rv => rv);
IF error_msg IS NOT NULL THEN
raise_error(error_msg);
END IF;
INSERT INTO #table#
(<%COLUMNS EXCLUDING GENERATED>
#col#~
,<%END>)
VALUES(<%COLUMNS EXCLUDING GENERATED>
#seq#.NEXTVAL{SURROGATE_KEY}~
rv.#col#~
UTIL.num_val(rv.#col#){NUMBER}~
UTIL.date_val(rv.#col#){DATE}~
UTIL.datetime_val(rv.#col#){DATETIME}~
UTIL.timestamp_val(rv.#col#){TIMESTAMP}~
UTIL.timestamp_tz_val(rv.#col#){TIMESTAMP_TZ}~
,<%END>)
RETURNING
<%COLUMNS INCLUDING VIRTUAL>
#col#~
,<%END>
INTO <%COLUMNS INCLUDING VIRTUAL>
r.#col#~
,<%END>;
msg('INSERT #table#: ' || SQL%ROWCOUNT);
log_end;
RETURN r;
EXCEPTION
WHEN DUP_VAL_ON_INDEX THEN
UTIL.raise_dup_val_on_index;
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END ins;
FUNCTION bulk_ins (arr IN rvarraytype) RETURN NUMBER IS
rowcount NUMBER;
BEGIN
log_start('bulk_ins');
bulk_val(arr);
FORALL i IN INDICES OF arr
INSERT INTO #table#
(<%COLUMNS EXCLUDING GENERATED>
#col#~
,<%END>)
VALUES (<%COLUMNS EXCLUDING GENERATED>
#seq#.NEXTVAL{SURROGATE_KEY}~
arr(i).#col#~
UTIL.num_val(arr(i).#col#){NUMBER}~
UTIL.date_val(arr(i).#col#){DATE}~
UTIL.datetime_val(arr(i).#col#){DATETIME}~
UTIL.timestamp_val(arr(i).#col#){TIMESTAMP}~
UTIL.timestamp_tz_val(arr(i).#col#){TIMESTAMP_TZ}~
,<%END>);
rowcount := SQL%ROWCOUNT;
msg('INSERT #table#: ' || rowcount);
log_end('rowcount=' || rowcount);
RETURN rowcount;
EXCEPTION
WHEN DUP_VAL_ON_INDEX THEN
UTIL.raise_dup_val_on_index;
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END bulk_ins;
<%IF DBMS_CRYPTO><%ELSE>$if false $then/*need to grant DBMS_CRYPTO*/<%END IF>
FUNCTION hash (r IN rowtype) RETURN VARCHAR2 IS
sep CONSTANT VARCHAR2(1) := '|';
digest CLOB;
ret RAW(2000);
BEGIN
log_start('hash');
<%COLUMNS EXCLUDING GENERATED,LOBS>
digest := digest || sep || r.#col#;~
digest := digest || sep || TO_CHAR(r.#col#, UTIL.DATE_FORMAT);{DATE}~
digest := digest || sep || TO_CHAR(r.#col#, UTIL.DATETIME_FORMAT);{DATETIME}~
digest := digest || sep || TO_CHAR(r.#col#, UTIL.TIMESTAMP_FORMAT);{TIMESTAMP}~
digest := digest || sep || TO_CHAR(r.#col#, UTIL.TIMESTAMP_TZ_FORMAT);{TIMESTAMP_TZ}~
<%END>
ret := DBMS_CRYPTO.hash(digest, DBMS_CRYPTO.hash_sh1);
log_end(ret);
RETURN ret;
EXCEPTION
WHEN UTIL.application_error THEN
log_end('application_error');
RAISE;
WHEN OTHERS THEN
UTIL.log_sqlerrm;
RAISE;
END hash;
<%IF DBMS_CRYPTO><%ELSE>$end<%END IF>
END #TAPI#;
<%END TEMPLATE>
$end
END TEMPLATES;
Template Syntax
You may be wondering what all the <%bla> and #bla# tags mean. These are the controlling elements for my code generator.
All template code is embedded within $if false $then ... $end so that the template package spec can be compiled without error in the schema, while still allowing most syntax highlighters to make the template easy to read and edit. This source is then read by the generator from the TEMPLATES database package.
Each template within the TEMPLATES package is delineated by the following structural codes, each of which must appear at the start of a line:
&amp;amp;amp;amp;lt;%TEMPLATE template_name&amp;amp;amp;amp;gt;
...
&amp;amp;amp;amp;lt;%END TEMPLATE&amp;amp;amp;amp;gt;
Anything in the TEMPLATES package not within these structural elements is ignored by the generator.
Some simple placeholders are supported anywhere in a template:
#SYSDATE# – Today’s date in DD-MON-YYYY format#TABLE# – Table name in uppercase#table# – Table name in lowercase#USER# – User name who executed the procedure#Entity# – User-friendly name based on table name, singular (e.g. EVENTS -> Event)#Entities# – User-friendly name based on table name#TAPI# – Table API package name#APEXAPI# – Apex API package name\n – Insert a linefeed (not often required, since actual linefeeds in the template are usually retained)
These are all case-sensitive; in some cases an UPPERCASE, lowercase and Initcap version is supported for a placeholder.
Code portions that are only required in certain cases may be surrounded with the IF/ELSE/END IF structure:
&amp;amp;amp;amp;lt;%IF condition&amp;amp;amp;amp;gt;
...
&amp;amp;amp;amp;lt;%ELSE&amp;amp;amp;amp;gt;
...
&amp;amp;amp;amp;lt;%END IF&amp;amp;amp;amp;gt;
Currently the list of conditions are limited to LOBS (true if the table has any LOB-type columns), ROWID (true if the table does NOT have a surrogate key (i.e. a primary key matched by name to a sequence), or the name of a table (useful to have some code that is only generated for a specific table), or the name of a DBMS_xxx package (useful to have code that is only generated if the owner has been granted EXECUTE on the named DBMS_xxx package).
To negate a condition, simply leave the first part of the IF/ELSE part empty, e.g.:
&amp;amp;amp;amp;lt;%IF LOBS&amp;amp;amp;amp;gt;&amp;amp;amp;amp;lt;%ELSE&amp;amp;amp;amp;gt; /*this table has no LOBS*/ &amp;amp;amp;amp;lt;%END IF&amp;amp;amp;amp;gt;
Code portions that need to be repeated for each column (or a subset of columns) in the table use the COLUMNS structure:
(&amp;amp;amp;amp;lt;%COLUMNS&amp;amp;amp;amp;gt;
#col#--- =&amp;amp;amp;amp;gt; :#COL#~
,&amp;amp;amp;amp;lt;%END&amp;amp;amp;amp;gt;)
The COLUMNS structure looks very weird and might take a while to get used to, but basically it contains a list of sub-templates, delimited by tildes (~). The first sub-template (e.g. #col#--- => :#COL#) is used for each column, and the second sub-template (e.g. ,) is inserted between each column (if there is more than one column). In the above example, our emps table would result in the following generated:
(emp_id =&amp;amp;amp;amp;gt; :EMP_ID
,name =&amp;amp;amp;amp;gt; :NAME
,emp_type =&amp;amp;amp;amp;gt; :EMP_TYPE
,start_date =&amp;amp;amp;amp;gt; :START_DATE
,end_date =&amp;amp;amp;amp;gt; :END_DATE
,dummy_ts =&amp;amp;amp;amp;gt; :DUMMY_TS
,dummy_tsz =&amp;amp;amp;amp;gt; :DUMMY_TSZ
,life_history =&amp;amp;amp;amp;gt; :LIFE_HISTORY)
Notice that #col# is replaced with the column name in lowercase, and #COL# is replaced with the column name in uppercase. In addition, the --- is a special code that causes the generator to insert additional spaces so that the code is aligned vertically. Notice also that the second sub-template (the separator bit with the comma) also includes a carriage return (after ~ and before ,). If we had instead used the following template:
&amp;amp;amp;amp;lt;%COLUMNS&amp;amp;amp;amp;gt;
#col#--- =&amp;amp;amp;amp;gt; :#COL#~,&amp;amp;amp;amp;lt;%END&amp;amp;amp;amp;gt;
This would have been the result:
emp_id =&amp;amp;amp;amp;gt; :EMP_ID,name =&amp;amp;amp;amp;gt; :NAME,emp_type =&amp;amp;amp;amp;gt; :EMP_TYPE,start_date =&amp;amp;amp;amp;gt; :START_DATE,end_date =&amp;amp;amp;amp;gt; :END_DATE,dummy_ts =&amp;amp;amp;amp;gt; :DUMMY_TS,dummy_tsz =&amp;amp;amp;amp;gt; :DUMMY_TSZ,life_history =&amp;amp;amp;amp;gt; :LIFE_HISTORY
The generator gives you a great deal of control over which columns are included. The COLUMNS structure supports three optional clauses: INCLUDING, EXCLUDING and ONLY.
&amp;amp;amp;amp;lt;%COLUMNS&amp;amp;amp;amp;gt;
(all columns in the table, EXCEPT for virtual columns)
&amp;amp;amp;amp;lt;%END&amp;amp;amp;amp;gt;
&amp;amp;amp;amp;lt;%COLUMNS INCLUDING VIRTUAL&amp;amp;amp;amp;gt;
(all columns in the table, including virtual columns)
&amp;amp;amp;amp;lt;%END&amp;amp;amp;amp;gt;
&amp;amp;amp;amp;lt;%COLUMNS EXCLUDING PK&amp;amp;amp;amp;gt;
(all columns except for Primary Key columns)
&amp;amp;amp;amp;lt;%END&amp;amp;amp;amp;gt;
&amp;amp;amp;amp;lt;%COLUMNS EXCLUDING LOBS&amp;amp;amp;amp;gt;
(all columns except for LOB-type columns)
&amp;amp;amp;amp;lt;%END&amp;amp;amp;amp;gt;
&amp;amp;amp;amp;lt;%COLUMNS EXCLUDING EMPS.NAME&amp;amp;amp;amp;gt;
(all columns - except for the specified column)
&amp;amp;amp;amp;lt;%END&amp;amp;amp;amp;gt;
&amp;amp;amp;amp;lt;%COLUMNS EXCLUDING AUDIT&amp;amp;amp;amp;gt;
(all columns except for the audit columns such as CREATED_BY, etc.)
&amp;amp;amp;amp;lt;%END&amp;amp;amp;amp;gt;
&amp;amp;amp;amp;lt;%COLUMNS ONLY PK&amp;amp;amp;amp;gt;
(only Primary Key columns)
&amp;amp;amp;amp;lt;%END&amp;amp;amp;amp;gt;
&amp;amp;amp;amp;lt;%COLUMNS ONLY PK,NAME&amp;amp;amp;amp;gt;
(only Primary Key columns and columns named NAME)
&amp;amp;amp;amp;lt;%END&amp;amp;amp;amp;gt;
&amp;amp;amp;amp;lt;%COLUMNS INCLUDING ROWID&amp;amp;amp;amp;gt;
(all columns in the table, plus the pseudocolumn ROWID)
&amp;amp;amp;amp;lt;%END&amp;amp;amp;amp;gt;
&amp;amp;amp;amp;lt;%COLUMNS INCLUDING MADEUPNAME&amp;amp;amp;amp;gt;
(all columns in the table, plus a fake column)
&amp;amp;amp;amp;lt;%END&amp;amp;amp;amp;gt;
&amp;amp;amp;amp;lt;%COLUMNS INCLUDING EMPS.MADEUPNAME&amp;amp;amp;amp;gt;
(all columns in the table, plus a fake column for the specified table)
&amp;amp;amp;amp;lt;%END&amp;amp;amp;amp;gt;
&amp;amp;amp;amp;lt;%COLUMNS ONLY SURROGATE_KEY,VERSION_ID INCLUDING ROWID&amp;amp;amp;amp;gt;
(multiple criteria may be combined)
&amp;amp;amp;amp;lt;%END&amp;amp;amp;amp;gt;
Within a sub-template the following placeholders are recognised:
#COL# – column name in uppercase#col# – column name in lowercase#Label# – generated user-friendly label based on column name#MAXLEN# – max length for a CHAR-type column#DATA_DEFAULT# – column default value#SEQ# – surrogate key sequence name#00i# – 001, 002, 003 etc. in order of column id--- – padding (inserts just enough extra spaces depending on length of column name so that code is aligned vertically)
For example, the following generates a comma-delimited list of user-friendly labels for each column in the table:
&amp;amp;amp;amp;lt;%COLUMNS&amp;amp;amp;amp;gt;#Label#~, &amp;amp;amp;amp;lt;%END&amp;amp;amp;amp;gt;
Emp, Name, Emp Type, Start, End, Dummy, Dummy, Life History
Side Note: it’s noteworthy that I have no need for a “#datatype#” placeholder; in most cases my templates will anchor to the column’s datatype anyway, so a template just needs to use #col#%TYPE.
Multiple additional sub-templates may be provided within a <%COLUMNS> structure, to be used for certain columns. These must end with a {X} indicator, where X can be a data type or column name. Other indicators are supported for special cases as well.
&amp;amp;amp;amp;lt;%COLUMNS&amp;amp;amp;amp;gt;
Default subtemplate ~
ID column {ID}~
NUMBER column {NUMBER}~
Date/time column {DATETIME}~
Date column {DATE}~
Timestamp column {TIMESTAMP}~
Timestamp with time zone {TIMESTAMP_TZ}~
Indicator (Y or null) column {IND}~
Yes/No (Y or N) column {YN}~
Any other VARCHAR2 column {VARCHAR2}~
Any LOB-type column (e.g. BLOB, CLOB) {LOB}~
Any specific datatype {CLOB}~
Primary key matched to a sequence {SURROGATE_KEY}~
Special case for a specific column {TABLE.COLUMN}~
Extra code to be used if NO columns match {NONE}~
,&amp;amp;amp;amp;lt;%END&amp;amp;amp;amp;gt;
The “data type” for a column is usually just the data type from the schema data dictionary; however, there are some special cases where a special data type is derived from the column name:
- ID: a NUMBER column with a name ending with
_ID
- DATETIME: a DATE column with name ending with
_DT
- IND: a VARCHAR2 column with a name ending with
_IND
- YN: a VARCHAR2 column with a name ending with
_YN
Within a template it is possible to import the code from another template (e.g. to share code between multiple templates, or to facilitate a nested-IF structure) using this structure:
&amp;amp;amp;amp;lt;%INCLUDE OTHERTEMPLATE&amp;amp;amp;amp;gt;
This will cause the generator to find a template named OTHERTEMPLATE, evaluate it, then insert it at the given position.
This method has allowed my code generator to be quite flexible and powerful, makes it easy to add additional code to all my API packages and other generated code, and makes it easy to find and fix errors.
You can download all the source for the template and generator below. Note that a new Sample Apex application is included (f560.sql) which works in Apex 5 and uses the new Apex API. Disclaimer:This is a work in progress!
If you find it useful or you have suggestions for improvement please comment.
Source code/download: https://github.com/jeffreykemp/jk64-sample-apex-xapi
If you attended my presentation at AUSOUG Perth earlier this month, or if you’ve had a peek at the slides, you may be interested in a more concrete demonstration of the ideas presented. So if you’d like to install and play with a sample application that includes a TAPI generator, feel free to download this (EDIT: updated, see below).
Disclaimer: this is provided for information (and entertainment) purposes only.
Prerequisites:
Oracle Application Express 4.2.2 or later
Read the README file for installation instructions.
If you’re only interested in the schema-level TAPI and not the APEX application, the zip file includes the DDL script that you can run directly in a schema without requiring Apex.
EDIT (18/11/2014): updated sample code to do the right thing in WHEN OTHERS triggers.
EDIT (20/11/2014): updated sample code with a further example for a FK to a table, which doesn’t use a surrogate key. Also added an exception handler to the Apex application.
EDIT (2/12/2014): added Grid Edit for event types, as an example of how a tabular form might work with a TAPI; added deployment package; moved code to Bitbucket.
EDIT (16/02/2014): upgraded to APEX 5, plus numerous improvements – refer to:
More updates and improvements will be added in the future – watch this space.
I recently saw this approach used in a complex Apex application built for my current client, and I liked what I saw – so I used a similar one in another project of mine, with good results.
- Pages load and process faster
- Less PL/SQL compilation at runtime
- Code is more maintainable and reusable
- Database object dependency analysis is much more reliable
- Apex application export files are smaller – faster to deploy
- Apex pages can be copied and adapted (e.g. for different interfaces) easier

How did all this happen? Nothing earth-shattering or terribly original. I made the following simple changes – and they only took about a week for a moderately complex 100-page application (that had been built haphazardly over the period of a few years):
- All PL/SQL Process actions moved to database packages
- Each page only has a single Before Header Process, which calls a procedure (e.g.
CTRL_PKG.p1_load;)
- Each page only has a single Processing Process, which calls a procedure (e.g.
CTRL_PKG.p1_process;)
- Computations are all removed, they are now done in the database package
The only changes I needed to make to the PL/SQL to make it work in a database package were that bind variable references (e.g. :P1_CUSTOMER_NAME) needed to be changed to use the V() (for strings and dates) or NV() (for numbers) functions; and I had to convert the Conditions on the Processes into the equivalent logic in PL/SQL. Generally, I would retrieve the values of page items into a local variable before using it in a query.
My “p1_load” procedure typically looked something like this:
PROCEDURE p1_load IS
BEGIN
msg('p1_load');
member_load;
msg('p1_load Finished');
END p1_load;
My “p1_process” procedure typically looked something like this:
PROCEDURE p1_process IS
request VARCHAR2(100) := APEX_APPLICATION.g_request;
BEGIN
msg('p1_process ' || request);
CASE request
WHEN 'CREATE' THEN
member_insert;
WHEN 'SUBMIT' THEN
member_update;
WHEN 'DELETE' THEN
member_delete;
APEX_UTIL.clear_page_cache
(APEX_APPLICATION.g_flow_step_id);
WHEN 'COPY' THEN
member_update;
-- clear the member ID for a new record
sv('P1_MEMBER_ID');
ELSE
NULL;
END CASE;
msg('p1_process Finished');
END p1_process;
I left Validations and Branches in the application. I will come back to the Validations later – this is made easier in Apex 4.1 which provides an API for error messages.
It wasn’t until I went through this exercise that I realised what a great volume of PL/SQL logic I had in my application – and that PL/SQL was being dynamically compiled every time a page was loaded or processed. Moving it to the database meant that it was compiled once; it meant that I could more easily see duplicated code (and therefore modularise it so that the same routine would now be called from multiple pages). I found a number of places where the Apex application was forced to re-evaluate a condition multiple times (as it had been copied to multiple Processes on the page) – now, all those processes could be put together into one IF .. END IF block.
Once all that code is compiled on the database, I can now make a change to a schema object (e.g. drop a column from a table, or modify a view definition) and see immediately what impact it will have across the application. No more time bombs waiting to go off in the middle of a customer demo. I can also query ALL_DEPENDENCIES to see where an object is being used.
I then wanted to make a Mobile version of a set of seven pages. This was made much easier now – all I had to do was copy the pages, set their interface to Mobile, and then on the database, call the same procedures. Note that when you do a page copy, that Apex automatically updates all references to use the new page ID – e.g. if you copy Page 1 to Page 2, a Process that calls “CTRL_PKG.p1_load;” will be changed to call “CTRL_PKG.p2_load;” in the new page. This required no further work since my p1_load and p1_process procedures merely had a one-line call to another procedure, which used the APEX_APPLICATION.g_flow_step_id global to determine the page number when using page items. For example:
PROCEDURE member_load IS
p VARCHAR2(10) := 'P' || APEX_APPLICATION.g_flow_step_id;
member members%ROWTYPE;
BEGIN
msg('member_load ' || p);
member.member_id := nv(p || '_MEMBER_ID');
msg('member_id=' || member.member_id);
IF member.member_id IS NOT NULL THEN
SELECT *
INTO member_page_load.member
FROM members m
WHERE m.member_id = member_load.member.member_id;
sv(p || '_GIVEN_NAME', member.given_name);
sv(p || '_SURNAME', member.surname);
sv(p || '_SEX', member.sex);
sv(p || '_ADDRESS_LINE', member.address_line);
sv(p || '_STATE', member.state);
sv(p || '_SUBURB', member.suburb);
sv(p || '_POSTCODE', member.postcode);
sv(p || '_HOME_PHONE', member.home_phone);
sv(p || '_MOBILE_PHONE', member.mobile_phone);
sv(p || '_EMAIL_ADDRESS', member.email_address);
sv(p || '_VERSION_ID', member.version_id);
END IF;
msg('member_load Finished');
END member_load;
Aside: Note here the use of SELECT * INTO [rowtype-variable]. This is IMO the one exception to the “never SELECT *” rule of thumb. The compromise here is that the procedure will query the entire record every time, even if it doesn’t use some of the columns; however, this pattern makes the code leaner and more easily understood; also, I usually need almost all the columns anyway.
In my database package, I included the following helper functions at the top, and used them throughout the package:
DATE_FORMAT CONSTANT VARCHAR2(30) := 'DD-Mon-YYYY';
PROCEDURE msg (i_msg IN VARCHAR2) IS
BEGIN
APEX_DEBUG_MESSAGE.LOG_MESSAGE
($$PLSQL_UNIT || ': ' || i_msg);
END msg;
-- get date value
FUNCTION dv
(i_name IN VARCHAR2
,i_fmt IN VARCHAR2 := DATE_FORMAT
) RETURN DATE IS
BEGIN
RETURN TO_DATE(v(i_name), i_fmt);
END dv;
-- set value
PROCEDURE sv
(i_name IN VARCHAR2
,i_value IN VARCHAR2 := NULL
) IS
BEGIN
APEX_UTIL.set_session_state(i_name, i_value);
END sv;
-- set date
PROCEDURE sd
(i_name IN VARCHAR2
,i_value IN DATE := NULL
,i_fmt IN VARCHAR2 := DATE_FORMAT
) IS
BEGIN
APEX_UTIL.set_session_state
(i_name, TO_CHAR(i_value, i_fmt));
END sd;
PROCEDURE success (i_msg IN VARCHAR2) IS
BEGIN
msg('success: ' || i_msg);
IF apex_application.g_print_success_message IS NOT NULL THEN
apex_application.g_print_success_message :=
:= apex_application.g_print_success_message || '<br>';
END IF;
apex_application.g_print_success_message
:= apex_application.g_print_success_message || i_msg;
END success;
Another change I made was to move most of the logic embedded in report queries into views on the database. This led to more efficiencies as logic used in a few pages here and there could now be consolidated in a single view.
The challenges remaining were record view/edit pages generated by the Apex wizard – these used DML processes to load and insert/update/delete records. In most cases these were on simple pages with no other processing added; so I left them alone for now.
On a particularly complex page, I removed the DML processes and replaced them with my own package procedure which did the query, insert, update and delete. This greatly simplified things because I now had better control over exactly how these operations are done. The only downside to this approach is that I lose the built-in Apex lost update protection mechanism, which detects changes to a record done by multiple concurrent sessions. I had to ensure I built that logic into my package myself – I did this with a simple VERSION_ID column on the table (c.f. Version Compare in “Avoiding Lost Updates”).
The only downsides with this approach I’ve noted so far are:
- a little extra work when initially creating a page
- page item references are now strings (e.g. “
v('P1_RECORD_ID')“) instead of bind variables – so a typo here and there can result in somewhat harder-to-find bugs
However, my application is now faster, more efficient, and on the whole easier to debug and maintain – so the benefits seem to outweigh the downsides.

I just wanted to bring attention to some very interesting discussion (that’s been going on for years now) regarding Table APIs (TAPI) versus Transactional APIs (XAPI). Some very nice answers, as well as a bit of controversy 🙂