Normally, when you see code like this in a production system, you should duck your head and run:
SELECT NVL( MAX( id ), 0 ) + 1
INTO :new_id
FROM mytable;
What’s wrong with this code?
I hope the first answer that rolls off your tongue has something to do with concurrency – i.e. two sessions that run this around the same time will not see uncommitted rows from each other, and so are likely to try to insert rows with conflicting identifiers.
I hope the second answer that you might mention has to do with performance – even considering there’s a unique index on the column, this code will still need to read at least one index block to get the latest ID (assuming the query optimiser chooses to do a MIN/MAX index scan so that it doesn’t have to scan the entire index before returning a result). In a high load system this cost might be unacceptable.
Of course, the first problem (concurrency) could be solved by serializing access to the “get the next ID” function, e.g. with a DBMS_LOCK. We all know, however, that there’s no sane reason to serialize this when Oracle already provides a perfectly good mechanism for generating unique IDs, with virtually no serialization – sequences.
CREATE SEQUENCE my_id_seq;
SELECT my_id_seq.NEXTVAL INTO :new_id FROM DUAL;
Sequences have the benefits of guaranteeing uniqueness, and if their cache setting is set appropriately, will add a negligible amount of overhead for serialization.
Problem solved. Easy, right? I bet you’re wondering why I added the word “Normally” to my first sentence in this post….
Question: When might using “SELECT MAX(id) + 1” ever be an acceptable source of unique identifiers?
Answer: Global Temporary tables.
If I’ve inserted any rows into a global temporary table, by definition no other session can see my data, so the first consideration, concurrency, is not an issue.
Also, if I’m not expecting to ever insert many rows into my global temporary table, I can be reasonably confident that performance will not be an issue either. Plus, if I put an index on the ID column, that query will be quite inexpensive.
Conclusion: if you are using global temporary tables, you don’t have to use sequences to generate unique identifiers for them. I’m not saying you shouldn’t, of course – a sequence may be faster, and may even lead to simpler code in some cases – but in other cases you might decide to forego a sequence – one less object, with perhaps its role grants and synonyms, to deploy.
…
Now, of course, you have to ask yourself, why query the table at all? Why not store that latest ID in a private global variable in a package? In fact, we can create a simple package to replace the sequence, e.g.:
CREATE OR REPLACE PACKAGE my_table_pkg IS
FUNCTION next_id RETURN my_table.id%TYPE;
END my_table_pkg;
CREATE OR REPLACE PACKAGE BODY my_table_pkg IS
g_latest_id my_table.id%TYPE;
FUNCTION next_id RETURN my_table.id%TYPE IS
BEGIN
g_latest_id := NVL(g_latest_id, 0) + 1;
RETURN g_latest_id;
END next_id;
END my_table_pkg;
Well, now you know what to do. Whenever you need to generate a unique set of identifiers for a global temporary table, you’ve got a choice of options: sequence, package variable, or a “max(id)+1” query.
I needed a table that could only ever have one row – if anyone tried to insert a second row they’d get an error.
CREATE UNIQUE INDEX only_one_row_allowed ON mytable (1);
Testing it:
INSERT INTO mytable VALUES ('x');
ORA-00001: unique constraint (SCOTT.ONLY_ONE_ROW_ALLOWED) violated
I use this simple query quite often when exploring the data in a table in any Oracle database (from Oracle v8 onwards):
select q.*, 100 * ratio_to_report(c) over () rtr
from (select distinct v, count(*) over (partition by v) c from (
select MYCOLUMN v from MYTABLE
)) q order by c desc;
Just substitute the table name for “MYTABLE” and the column you’re interested in for “MYCOLUMN”. This gives a frequency analysis of values, e.g.:
V C RTR
======== ====== =============
INACTIVE 401001 92.9254049544
ACTIVE 30529 7.0745950455
V is the value from the column. C is the count of how many times that value appeared. RTR is the % ratio to the total. The first row indicates the most popular value.
If it’s a very large table and you want quicker results, you can run the analysis over a smaller sample easily, just by adding the SAMPLE keyword:
...
select MYCOLUMN v from MYTABLE SAMPLE(1)
...
It starts out as a fairly simple, innocent business requirement. Create a report to list records meeting some criteria, one of which is:
“List only records where today’s date is more than 35 business days after the due date from the record.”
When you delve deeper you find that querying the table with “DUE_DATE + 35 < SYSDATE” is not going to cut it – “business days” do not include weekends. You might start with something similar to this. But even that’s not good enough, because business days should not include public holidays. How do you code that?
So, here’s my solution.
1. We need to know what days are public holidays for the region. In our case this application is only applicable for a single region, so we use a simple table:
CREATE TABLE holidays (holiday_date DATE PRIMARY KEY);
We create a simple form for users to enter new holidays every year, and give someone the job of making sure it’s up-to-date every year when the public holidays are announced.
2. Create a view that lists all non-business days – i.e. list all weekends and public holidays. To retain reasonable performance, we limit our solution to dates in the years 2000 to 2050.
CREATE VIEW non_business_days AS
SELECT TO_DATE('01012000','DDMMYYYY') + ROWNUM * 7
AS day -- Saturdays 2000 to 2050
FROM DUAL CONNECT BY LEVEL <= 2661
UNION ALL
SELECT to_date('02012000','DDMMYYYY') + ROWNUM * 7
AS day -- Sundays 2000 to 2050
FROM DUAL CONNECT BY LEVEL <= 2661
UNION ALL
SELECT holiday_date FROM holidays;
3. Now, when we need to take a date and add x business days to it, we query this table to find all the non-business-days that are applicable, e.g.:
SELECT day
,COUNT(*) OVER (ORDER BY day
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW)
AS count_so_far
,(day - p_date) AS base_days
FROM NON_BUSINESS_DAYS
WHERE day > p_date;
If you run this query and examine each row in order of day, if you take base_days and subtract count_so_far, when the result is less than x, then base_days – count_so_far is the number of extra days we need to add to the holiday’s date to give us the answer. You’ll find this logic in the function below.
In our final solution, we’ll also need to UNION in the date parameter as well, for the case where there are no holidays between the starting date and the number of business days requested.
Here’s our function to take any date (at least, any date between 2000 and 2050) and add x business days (positive or negative):
FUNCTION add_working_days (p_date IN DATE, p_working_days IN NUMBER)
RETURN DATE IS
l_date DATE;
BEGIN
IF p_date IS NULL OR p_working_days IS NULL THEN
RETURN NULL;
END IF;
IF p_working_days != TRUNC(p_working_days) THEN
RAISE_APPLICATION_ERROR(-20000,
'add_working_days: cannot handle fractional p_working_days ('
|| p_working_days || ')');
END IF;
IF p_working_days > 0 THEN
SELECT MAX(day + p_working_days - (base_days - count_so_far))
INTO l_date
FROM (SELECT day
,COUNT(*) OVER (ORDER BY day
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW)
AS count_so_far
,(day - p_date) AS base_days
FROM NON_BUSINESS_DAYS
WHERE day > p_date
UNION
SELECT p_date, 0, 0 FROM DUAL
)
WHERE base_days - count_so_far < p_working_days;
ELSIF p_working_days < 0 THEN
SELECT MIN(day - (ABS(p_working_days) - (base_days - count_so_far)))
INTO l_date
FROM (SELECT day
,COUNT(*) OVER (ORDER BY day DESC
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW)
AS count_so_far
,(p_date - day) AS base_days
FROM NON_BUSINESS_DAYS
WHERE day < p_date
UNION
SELECT p_date, 0, 0 FROM DUAL
)
WHERE base_days - count_so_far < ABS(p_working_days);
ELSE
l_date := p_date;
END IF;
RETURN l_date;
END add_working_days;
Test cases (these are some public holidays in Western Australia):
insert into holidays values (to_date('27/12/2010','DD/MM/YYYY');
insert into holidays values (to_date('28/12/2010','DD/MM/YYYY');
insert into holidays values (to_date('03/01/2011','DD/MM/YYYY');
insert into holidays values (to_date('26/01/2011','DD/MM/YYYY');
— Expected: 06/01/2011
select cls_util.add_working_days(to_date('13/12/2010','DD/MM/YYYY')
,15) from dual;
— Expected: 31/01/2011
select cls_util.add_working_days(to_date('25/01/2011','DD/MM/YYYY')
,3) from dual;
— Expected: 13/12/2010
select cls_util.add_working_days(to_date('06/01/2011','DD/MM/YYYY')
,-15) from dual;
— Expected: 25/01/2011
select cls_util.add_working_days(to_date('31/01/2011','DD/MM/YYYY')
,-3) from dual;
I have two queries that need to be executed by a PL/SQL program. Both of them are quite complex, and both of them have a large section which is identical – because they are different views of the same underlying source data.
One option is to expand out both queries in full, e.g.:
Query 1:
SELECT <complicated expressions>
FROM (
<large complicated query>
), <other tables>
WHERE <complicated predicates>;
Query 2:
SELECT <different complicated expressions>
FROM (
<large complicated query>
), <other different tables>
WHERE <different complicated predicates>;
I don’t like the fact that my <large complicated query> is repeated in full in both cursor definitions. I’d rather have one place where that subquery is defined, because it should remain the same for both queries, since they are supposed to be different views of the same underlying data.
Another option is to create a view on the <large complicated query>, and refer to that in both queries. This is a perfectly acceptable option, and one which I often use. The only downside is if there are any parameters that need to be “fed” to the view. One way is for the view to expose the parameter as a column in the view, and for the calling query to simply query it on that column. This is not always the most efficient method, however, depending on the complexity of the view and how well Oracle can “push down” the predicate into the view at execution time. Another solution to the parameter problem is to use a user-defined context as described here.
The other downside which I don’t like for this case is that the view moves the query away from the package – I’d prefer to have the definitions close together and maintained in one location.
The solution which I used in this case is a pipelined function. For example:
FUNCTION large_complicated_query
RETURN source_data_table_type
PIPELINED IS
rc source_data_type;
BEGIN
FOR r IN (<large complicated query>) LOOP
rc.col1 := r.col1;
rc.col2 := r.col2;
-- etc.
PIPE ROW (rc);
END LOOP;
RETURN;
END;
Now, the two queries in my package can re-use it like this:
SELECT <complicated expressions>
FROM TABLE(my_package.large_complicated_query)
,<other tables>
WHERE <complicated predicates>;
In the package spec I have:
-- *** dev note: for internal use only ***
TYPE source_data_type IS
RECORD (col1 col1_data_type, etc....);
TYPE source_data_type_table IS TABLE OF source_data_type;
FUNCTION large_complicated_query
RETURN source_data_table_type PIPELINED;
-- *** ******************************* ***
Because the pipelined function is going to be called by SQL (in fact, two queries defined in the same package), its declaration must also be added to the package spec.
In the package body, I use private global variable(s) to hold the parameter for the large complicated query.
When the queries are run, the global variable(s) must first be set to the required parameter. The queries are run, then the global variables are cleared.
The pipelined function is deliberately not useful to other processes – if a developer tried to call it, they’d get no results because they can’t set the parameters (since they are declared as private globals).
A downside to this approach is that the optimizer will not be able to optimize the entire queries “as a whole” – it will execute the entire query in the pipelined function (at least, until the calling queries decide to stop fetching from it). For my case, however, this is not a problem. The entire process runs in less than a second – and this is 10 times faster than it needs to be. In other words, in this case maintainability is more important than performance.
There may be other ways to do this (in fact, I’m quite sure there are), but this way worked for me.
 A particular table in our system is a M:M link table between Bonds and Payments, imaginatively named BOND_PAYMENTS; and to make the Java devs’ jobs easier it has a surrogate key, BOND_PAYMENT_ID. Its structure, therefore, is basically:
A particular table in our system is a M:M link table between Bonds and Payments, imaginatively named BOND_PAYMENTS; and to make the Java devs’ jobs easier it has a surrogate key, BOND_PAYMENT_ID. Its structure, therefore, is basically:
BOND_PAYMENTS
(BOND_PAYMENT_ID,
BOND_NUMBER,
PAYMENT_ID)
This is a very simple design, quite common in relational database designs. There is a Primary key constraint on BOND_PAYMENT_ID, and we’ve also added a Unique constraint on (BOND_NUMBER, PAYMENT_ID) since it makes no sense to have more than one link between a Bond and a Payment.
The application allows a user to view all the Payments linked to a particular Bond; and it allows them to create new links, and delete existing links. Once they’ve made all their desired changes on the page, they hit “Save”, and Hibernate does its magic to run the required SQL on the database. Unfortunately, this was failing with ORA-00001: unique constraint violated.
Now, the way this page works is that it compares the old set of payments for the bond with the new target set, and Hibernate works out which records need to be deleted, which need to be inserted, and leaves the rest untouched. Unfortunately, in its infinite wisdom it does the INSERTs first, then it does the DELETEs. Apparently this order can’t be changed.
This is the cause of the unique constraint violation – if the user deletes a link to a payment, then changes their mind and re-inserts a link to the same payment, Hibernate quite happily tries to insert it then delete it. Since these inserts/deletes are running as separate SQL statements, Oracle validates the constraint immediately on the first insert.
We had only a few options:
- Make the constraint deferrable
- Remove the unique constraint
Option 2 was not very palatable, because the constraint provides excellent protection from nasty application bugs that might allow inconsistent data to be saved. We went with option 1.
ALTER TABLE bond_payments ADD
CONSTRAINT bond_payment_uk UNIQUE (bond_number, payment_id)
DEFERRABLE INITIALLY DEFERRED;
This solved it – and no changes required to the application. If a bug in the application were to cause it to try to insert a duplicate row, it will fail with ORA-02091 (transaction rolled back) and ORA-00001 (unique constraint violated) when the session COMMITs.
The only downside is that the index created to police this constraint is now a non-unique index, so may be somewhat less efficient for queries. We decided this is not as great a detriment for this particular case.
If you know of any other options that we should have considered, let me know 🙂
I was playing around with the layout of my APEX form, while at the same time upgrading the date items from the Classic date items to the new Date Picker items, and was rewarded with this:

The simplest way to fix this is to edit the Item, specifically the HTML Table Cell Attributes – set to NOWRAP:

Viola, problem solved:

June 2016: Update for APEX 5 Universal Theme
I was alerted by Evandro Giachetto that the above solution does not work with the Universal Theme in APEX 5.
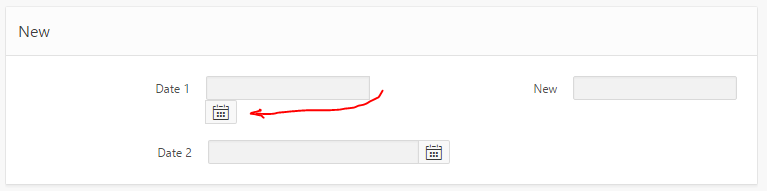
I had a go at trying to workaround it. I tried adding “white-space:nowrap” to various levels of divs around the item, which stopped it from wrapping the icon, but it kept hiding the icon behind the label div for the next item.
So through the magic of twitter we got a CSS solution proposed by Markus Hohloch:
.t-Form-inputContainer { white-space: nowrap; }
.ui-datepicker-trigger { right: 25px; }
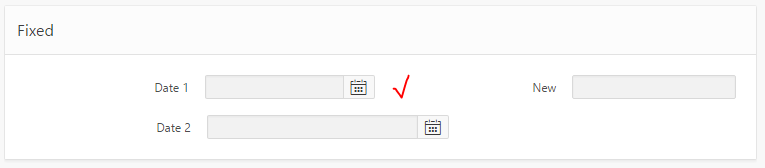
This takes care of the wrapping, and fixes the problem with the icon being hidden. The only downside is that when the screen is very slim, this css causes a gap to be shown on the right-hand side of the icon; this is not too big a deal but I suspect with the right media query syntax that could be fixed as well.
I was writing some scripts to drop all the objects in a particular schema on an 11gR2 database, and in querying the USER_OBJECTS view, came across a whole lot of tables with names like this:
SYS_IOT_OVER_152769
SYS_IOT_OVER_152772
SYS_IOT_OVER_152775
SYS_IOT_OVER_152778
...
What in the world are these? As it turns out, these are overflow tables for Index Organized Tables.
The following query on USER_TABLES (or ALL_TABLES or DBA_TABLES) will reveal all:
SQL> SELECT table_name, iot_type, iot_name FROM USER_TABLES
WHERE iot_type IS NOT NULL;
TABLE_NAME IOT_TYPE IOT_NAME
=================== ============ ==========================
SYS_IOT_OVER_152769 IOT_OVERFLOW TBMS_REF_ACCOUNT_TYPE
SYS_IOT_OVER_152772 IOT_OVERFLOW TBMS_REF_APPLICATION_TYPE
SYS_IOT_OVER_152775 IOT_OVERFLOW TBMS_REF_BOND_PAYMENT_TYPE
SYS_IOT_OVER_152778 IOT_OVERFLOW TBMS_REF_BOND_STATUS
...
The IOT_NAME reveals the table that owns the overflow table. The create command for TBMS_REF_ACCOUNT_TYPE was:
CREATE TABLE TBMS.TBMS_REF_ACCOUNT_TYPE
(
ACCOUNT_TYPE_CODE VARCHAR2(10 BYTE) NOT NULL,
DESCRIPTION VARCHAR2(50 BYTE),
COMMENTS VARCHAR2(4000),
DB_CREATED_BY VARCHAR2(50 BYTE) DEFAULT USER NOT NULL,
DB_CREATED_ON DATE DEFAULT SYSDATE NOT NULL,
DB_MODIFIED_BY VARCHAR2(50 BYTE),
DB_MODIFIED_ON DATE,
VERSION_ID NUMBER(12) DEFAULT 1 NOT NULL,
CONSTRAINT TBMS_REF_ACCOUNT_TYPE_PK
PRIMARY KEY (ACCOUNT_TYPE_CODE)
)
ORGANIZATION INDEX INCLUDING DESCRIPTION OVERFLOW;
This means that ACCOUNT_TYPE_CODE and DESCRIPTION will be kept in the index, since these are pretty much the only columns normally accessed; the rest, including the big comments field (which seems to be largely unused), will be stored in the overflow table if they are set.
Right. So I drop the REF table – that should take care of the overflow table, right? Wrong. The SYS_IOT_OVER table is still there! Ah – that’s because the REF table is sitting in the recyclebin. Purge it, and now the SYS_IOT_OVER table is gone. (Not that there was anything wrong with it, mind you – I just wanted to clean this schema out so I could recreate it.)
For more info: http://download.oracle.com/docs/cd/E11882_01/server.112/e16508/indexiot.htm#CNCPT911
My client has decided to design and build a completely new replacement system for an aging system running on Oracle Forms 6i on Oracle 8. The new system will have a web frontend, backed by Hibernate (don’t get me started) on top of an Oracle 11gR1 database. Crucially, due to changes to business practices and legislation, the new system has been designed “from scratch”, including a new data model.
My task is to write the ETL scripts which will take the data from the legacy database (an Oracle 8i schema), transform it to meet the requirements of the new model, and load it. If you’re looking at building scripts to transform data from one system to another, the method I used might be helpful for you too.
Making it more complicated is their desire that the data move be executed in two stages – (1) before the switch-over, transform and load all “historical” data; (2) at go-live, transform and load all “current” data, as well as any modifications to “historical” data.
Since the fundamental business being supported by this system hasn’t changed very much, the old and new data models have a lot in common – the differences between them are not very complex. In addition, the data volume is not that great (coming from someone who’s worked with terabyte-scale schemas) – the biggest table only had 2 million rows. For these reasons, the purchase of any specialised ETL tools was not considered. Instead, they asked me to write the ETL as scripts that can just be run on the database.
These scripts must be re-runnable: they should be able to be run without modification to pick up any changes in the legacy data, and automatically work out how to merge the changes into the new schema.
The first step for me was to analyse both data models, and work out a mapping for the data between them. The team for the project had a very good idea of what the tables in the new model meant (since they had designed it), but there was no-one available to me to explain how the old data model worked. It was down to me to learn how the legacy data model worked – by exploring it at the database level, examining the source for the forms and reports, and in some cases by talking to the users.
The outcome of this analysis was two spreadsheets: one was a list of every table and column in the legacy database, and the other was a list of every table and column in the new database. For each table in the legacy database, I recorded which table (or tables) the data would be migrated to in the new schema, or an explanation if the data could be safely disregarded. For each table in the new schema, I recorded which table (or tables) in the legacy database would feed into it. In the end, eleven of the tables in the new schema would be loaded.
Then, for each table in the legacy and new schemas, I worked through each column, identifying what it meant, and how it would be mapped from the old to the new. In some cases, the mapping was very 1:1 – perhaps some column names were different, or code values different, but relatively simple. In other cases, the mapping would require a more complex transformation, prehaps based on multiple tables. For example, both systems had a table named “ADDRESS” which stored street or postal addresses; in the old system, this table was a child table to the “PARTY” table; so PARTY was 1:M to ADDRESS. In the new model, however, there was a master “ADDRESS” table which was intended to store any particular address once and only once; the relationship of PARTY to ADDRESS is M:M. De-duplication of addresses hasn’t come up yet but it’s going to be fun when it does 🙂
Thankfully, in no cases was the mapping so complicated that I couldn’t envisage how it could be done using relatively simple SQL.
Once the spreadsheets were filled, I was finally able to start coding!
In order to meet the requirements, my scripts must:
- INSERT rows in the new tables based on any data in the source that hasn’t already been created in the destination
- UPDATE rows in the new tables based on any data in the source that has already been inserted in the destination
- DELETE rows in the new tables where the source data has been deleted
Now, instead of writing a whole lot of INSERT, UPDATE and DELETE statements, I thought “surely MERGE would be both faster and better” – and in fact, that has turned out to be the case. By writing all the transformations as MERGE statements, I’ve satisfied all the criteria, while also making my code very easily modified, updated, fixed and rerun. If I discover a bug or a change in requirements, I simply change the way the column is transformed in the MERGE statement, and re-run the statement. It then takes care of working out whether to insert, update or delete each row.
My next step was to design the architecture for my custom ETL solution. I went to the dba with the following design, which was approved and created for me:
- create two new schemas on the new 11g database: LEGACY and MIGRATE
- take a snapshot of all data in the legacy database, and load it as tables in the LEGACY schema
- grant read-only on all tables in LEGACY to MIGRATE
- grant CRUD on all tables in the target schema to MIGRATE.

All my scripts will run as the MIGRATE user. They will read the data from the LEGACY schema (without modifying) and load it into intermediary tables in the MIGRATE schema. Each intermediary table takes the structure of a target table, but adds additional columns based on the legacy data. This means that I can always map from legacy data to new data, and vice versa.
For example, in the legacy database we have a table:
LEGACY.BMS_PARTIES(
par_id NUMBER PRIMARY KEY,
par_domain VARCHAR2(10) NOT NULL,
par_first_name VARCHAR2(100) ,
par_last_name VARCHAR2(100),
par_dob DATE,
par_business_name VARCHAR2(250),
created_by VARCHAR2(30) NOT NULL,
creation_date DATE NOT NULL,
last_updated_by VARCHAR2(30),
last_update_date DATE)
In the new model, we have a new table that represents the same kind of information:
NEW.TBMS_PARTY(
party_id NUMBER(9) PRIMARY KEY,
party_type_code VARCHAR2(10) NOT NULL,
first_name VARCHAR2(50),
surname VARCHAR2(100),
date_of_birth DATE,
business_name VARCHAR2(300),
db_created_by VARCHAR2(50) NOT NULL,
db_created_on DATE DEFAULT SYSDATE NOT NULL,
db_modified_by VARCHAR2(50),
db_modified_on DATE,
version_id NUMBER(12) DEFAULT 1 NOT NULL)
This was the simplest transformation you could possibly think of – the mapping from one to the other is 1:1, and the columns almost mean the same thing.
The solution scripts start by creating an intermediary table:
MIGRATE.TBMS_PARTY(
old_par_id NUMBER PRIMARY KEY,
party_id NUMBER(9) NOT NULL,
party_type_code VARCHAR2(10) NOT NULL,
first_name VARCHAR2(50),
surname VARCHAR2(100),
date_of_birth DATE,
business_name VARCHAR2(300),
db_created_by VARCHAR2(50),
db_created_on DATE,
db_modified_by VARCHAR2(50),
db_modified_on DATE,
deleted CHAR(1))
You’ll notice that the intermediary table has the same columns of the new table (except for VERSION_ID, which will just be 1), along with the minimum necessary to link each row back to the source data – the primary key from the source table, PAR_ID.
You might also notice that there is no unique constraint on PARTY_ID – this is because we needed to do some merging and de-duplication on the party info. I won’t go into that here, but the outcome is that for a single PARTY_ID might be mapped from more than one OLD_PAR_ID.
The second step is the E and T parts of “ETL”: I query the legacy table, transform the data right there in the query, and insert it into the intermediary table. However, since I want to be able to re-run this script as often as I want, I wrote this as a MERGE statement:
MERGE INTO MIGRATE.TBMS_PARTY dest
USING (
SELECT par_id AS old_par_id,
par_id AS party_id,
CASE par_domain
WHEN 'P' THEN 'PE' /*Person*/
WHEN 'O' THEN 'BU' /*Business*/
END AS party_type_code,
par_first_name AS first_name,
par_last_name AS surname,
par_dob AS date_of_birth,
par_business_name AS business_name,
created_by AS db_created_by,
creation_date AS db_created_on,
last_updated_by AS db_modified_by,
last_update_date AS db_modified_on
FROM LEGACY.BMS_PARTIES s
WHERE NOT EXISTS (
SELECT null
FROM MIGRATE.TBMS_PARTY d
WHERE d.old_par_id = s.par_id
AND (d.db_modified_on = s.last_update_date
OR (d.db_modified_on IS NULL
AND s.last_update_date IS NULL))
)
) src
ON (src.OLD_PAR_ID = dest.OLD_PAR_ID)
WHEN MATCHED THEN UPDATE SET
party_id = src.party_id ,
party_type_code = src.party_type_code ,
first_name = src.first_name ,
surname = src.surname ,
date_of_birth = src.date_of_birth ,
business_name = src.business_name ,
db_created_by = src.db_created_by ,
db_created_on = src.db_created_on ,
db_modified_by = src.db_modified_by ,
db_modified_on = src.db_modified_on
WHEN NOT MATCHED THEN INSERT VALUES (
src.old_par_id ,
src.party_id ,
src.party_type_code ,
src.first_name ,
src.surname ,
src.date_of_birth ,
src.business_name ,
src.db_created_by ,
src.db_created_on ,
src.db_modified_by ,
src.db_modified_on ,
NULL );
You’ll notice that all the transformation logic happens right there in a single SELECT statement. This is an important part of how this system works – every transformation is defined in one place and one place only. If I need to change the logic for any column, all I have to do is update it in one place, and re-run the MERGE.
This is a simple example; for some of the tables, the SELECT statement is quite complex.
(Warning: you’ll note that I’ve omitted the column list from the INSERT clause; this can be dangerous if you’re not in complete control of the column order like I am for this particular table)
There is a follow-up UPDATE statement that for a couple of thousand records, changes the PARTY_ID to a different value; in effect, this performs the de-duplication.
Next, we look for any rows that have been deleted:
UPDATE MIGRATE.TBMS_PARTY dest
SET deleted = 'Y'
WHERE deleted IS NULL
AND NOT EXISTS (
SELECT null
FROM LEGACY.BMS_PARTIES src
WHERE src.par_id = dest.old_par_id);
The idea is that the data in the MIGRATE table is *exactly* what we will insert, unmodified, into the target schema. In a year’s time, we could go back to this MIGRATE schema and see what we actually inserted when the system went live. In addition, we’ll be able to go back to the LEGACY schema and see exactly how the data looked in the old system; and we’ll be able to use tables like MIGRATE.TBMS_PARTY to map back-and-forth between the old and new systems.
The final stage of the process is the “L” of “ETL”. This, again, uses a MERGE statement:
MERGE INTO NEW.TBMS_PARTY dest
USING (
SELECT *
FROM MIGRATE.TBMS_PARTY s
WHERE s.party_id = s.old_par_id /*i.e. not a duplicate*/
AND (s.deleted IS NOT NULL
OR NOT EXISTS (
SELECT null
FROM NEW.TBMS_PARTY d
WHERE d.party_id = s.party_id
AND (d.db_modified_on = s.db_modified_on
OR (d.db_modified_on IS NULL
AND s.db_modified_on IS NULL))
) )
) src
ON (src.party_id = dest.party_id)
WHEN MATCHED THEN UPDATE SET
party_type_code = src.party_type_code ,
first_name = src.first_name ,
surname = src.surname ,
date_of_birth = src.date_of_birth ,
business_name = src.business_name ,
db_created_by = src.db_created_by ,
db_created_on = src.db_created_on ,
db_modified_by = src.db_modified_by ,
db_modified_on = src.db_modified_on
DELETE WHERE (src.deleted IS NOT NULL)
WHEN NOT MATCHED THEN INSERT (
party_id ,
party_type_code ,
first_name ,
surname ,
date_of_birth ,
business_name ,
db_created_by ,
db_created_on ,
db_modified_by ,
db_modified_on )
VALUES (
src.party_type_code ,
src.first_name ,
src.surname ,
src.date_of_birth ,
src.business_name ,
src.db_created_by ,
src.db_created_on ,
src.db_modified_by ,
src.db_modified_on )
LOG ERRORS
INTO MIGRATE.ERR$_TBMS_PARTY
REJECT LIMIT UNLIMITED;
A few things to note here:
- The SELECT clause brings back each row from the intermediary table that has not been merged to a new record (by the way, those records are needed because they are used when transforming PAR_ID values in child tables) or that has not been modified since it was previously loaded.
- The MERGE inserts any new rows, updates all columns for modified rows, and deletes rows that have been marked for deletion.
- NO transformation of data happens here.
- If any data fails any validation, the MERGE logs the error and continues, using a table created using this:
BEGIN
DBMS_ERRLOG.create_error_log('NEW.TBMS_PARTY',
err_log_table_name => 'ERR$_TBMS_PARTY',
err_log_table_owner => 'MIGRATE');
END;
I can then query this error table to see if there were any problems, e.g.:
SELECT ORA_ERR_OPTYP$, ORA_ERR_MESG$, COUNT(*)
FROM MIGRATE.ERR$_TBMS_PARTY
GROUP BY ORA_ERR_OPTYP$, ORA_ERR_MESG$;
A common issue is a failed check constraint, e.g. where the old system failed to validate something correctly. We’d then go back and either change the transformation to work around the problem, or send the data back to the business and ask them to fix it in the source.
Each stage of this ETL solution can be restarted and re-run. In fact, that’s what we will be doing; a few weeks prior to go-live, we’ll get a preliminary extract of the old system into the LEGACY schema, and run all my scripts. Then, at go-live, when the old system is taken down, we’ll wipe the LEGACY schema and refresh it from Prod. We will then re-run the scripts to take changes through.
All the scripts for each table had the same structure: one script to create the intermediary table; one script to do the merge into the intermediary table; and one script to merge into the final destination. With the exception of the SELECT statement in the first merge script, which differed greatly for each table, these scripts were very similar, so I started by generating them all. For this I used queries on the data dictionary to generate all the SELECT lists and x = y lists, and after a bit of work I had a complete set of ETL scripts which just needed me to go in and make up the SELECT statement for the transformation.
For this case, a relatively simple data migration problem, this method seems to have worked well. It, or a variation on it, might very well work for you too.
I’m building a very simple set of Oracle Forms for a customer who has very simple requirements. The form will allow one set of users to enter “payments”, which eventually get turned into requests for cheques to be sent out from the organisation. Each payment must go through an approval process – another set of users will open another form which will list all the payments that have been entered, select some or all of them and mark them as “Approved”.
To implement this design, I have one form which allows the users to enter the payment details; this form allows users to both insert new payments and update existing ones. Once a payment has been marked as “Approved”, they can only view but not edit them.
I’ve created a second form for the approvers, which lists all the payments that have not yet been approved, and gives them a simple checkbox. They tick any or all of the payments that they wish to approve, and click the “Approve” button. The button just sends an array of payment IDs to a database procedure which does a bulk update on the payments, setting their status as appropriate. Simple, right?
The one complication here is that this is a multi-user system, and it is quite likely that a users might try to update a payment at the same time as the approver is trying to mark them as approved. My first test of the forms indicated that this would cause a record locking issue:
In session #1, I open the payments form, query an existing payment, and start editing one of the fields. Oracle Forms automatically locks the record for update.
In session #2, I open the approvals form, tick the same payment, and click the “Approve” button. The form complains that it cannot reserve the record for update and the error logged is “FRM-40735 WHEN-BUTTON-PRESSED trigger raised unhandled exception ORA-04068.”
To solve this, I go to the checkbox item in the approvals form and add this code to the when-checkbox-changed trigger (the checkbox item is called PAYMENTS.SELECTED):
IF :PAYMENTS.SELECTED = 'Y' THEN
LOCK_RECORD;
IF NOT FORM_SUCCESS THEN
:PAYMENTS.SELECTED := 'N';
RAISE FORM_TRIGGER_FAILURE;
END IF;
END IF;
Now, when the user tries to tick a payment that is currently locked, the LOCK_RECORD causes the form to attempt to lock the record. The “unable to reserve record for update” error still appears, after which the trigger un-ticks the record automatically.
If the approve gets to a payment first and ticks it, the record will now be locked until the form commits the status change; this ensures that other users cannot modify the record until the approver either approves the payment or cancels out of the form.
