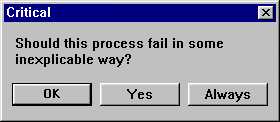
 What is the return value of SHOW_ALERT if the user doesn’t click one of the available buttons? According to the documentation (Forms 6i):
What is the return value of SHOW_ALERT if the user doesn’t click one of the available buttons? According to the documentation (Forms 6i):
SHOW_ALERT
Displays the given alert, and returns a numeric value when the operator selects one of three alert buttons.
Syntax:
SHOW_ALERT (alert_id Alert);
SHOW_ALERT (alert_name VARCHAR2);
Returns a numeric constant corresponding to the button the operator selected from the alert. Button mappings are specified in the alert design.
If the operator selects… Form Builder returns
Button 1 ALERT_BUTTON1
Button 2 ALERT_BUTTON2
Button 3 ALERT_BUTTON3
So for example, we can use this in code like this:
DECLARE
btn NUMBER(2);
BEGIN
btn := SHOW_ALERT('MY_ALERT');
IF btn = ALERT_BUTTON1 THEN
-- Yes was chosen
ELSIF btn = ALERT_BUTTON2 THEN
-- No was chosen
ELSIF btn = ALERT_BUTTON3 THEN
-- Cancel was chosen
END IF;
END;
The alert can have two or three buttons, depending on whether you set the Button 3 Label property. For example, you could have an alert named MY_ALERT with the following settings:
Message: Do you want to save the changes you have made?
Button 1 Label: Yes
Button 2 Label: No
Button 3 Label: Cancel
If the user clicks Yes, No or Cancel, the function returns one of the three ALERT_BUTTON constants. Simple enough. But what if the user decides to be different and clicks the “X” (close window button)? Alternatively, what if the user presses the “Esc” key on their keyboard?
Testing with Forms 6 (6.0.8.26.0) reveals that the answer depends on whether you have just two buttons defined, or all three. These results are probably the same on other versions, but you should test this on your version to make sure.
If you have three buttons, both the Close Window button and the “Esc” key cause SHOW_ALERT to return ALERT_BUTTON3. If you only have two buttons, the “Esc” key still returns ALERT_BUTTON3, for some reason, whereas the Close Window button returns ALERT_BUTTON2! The moral of the story is, make sure your code handles all three of the ALERT_BUTTON alternatives correctly! Also, make sure that the last button (2nd or 3rd) really does mean “cancel”. A very bad (hypothetical) example would be:
Message: What would you like to do?
Button 1 Label: Create a new record
Button 2 Label: Modify this record
Button 3 Label: Delete all these records
EDIT:
This post seems quite popular, so I thought I’d add what I think are good examples for handling alerts in Forms:
1. Two-button alert
Message: Do you want to XXX?
Button 1 Label: Yes
Button 2 Label: No
Button 3 Label: [blank]
DECLARE
btn NUMBER(2);
BEGIN
btn := SHOW_ALERT('MY_ALERT');
IF btn = ALERT_BUTTON1 THEN
-- Yes was chosen
ELSIF btn = ALERT_BUTTON2 THEN
-- No was chosen, or Close button clicked
ELSIF btn = ALERT_BUTTON3 THEN
-- ESC key pressed
END IF;
END;
2. Three-button alert
Message: Do you want to XXX?
Button 1 Label: Yes
Button 2 Label: No
Button 3 Label: Cancel
DECLARE
btn NUMBER(2);
BEGIN
btn := SHOW_ALERT('MY_ALERT');
IF btn = ALERT_BUTTON1 THEN
-- Yes was chosen
ELSIF btn = ALERT_BUTTON2 THEN
-- No was chosen
ELSIF btn = ALERT_BUTTON3 THEN
-- Cancel was chosen, or Close button clicked, or ESC key pressed
END IF;
END;
I’ve worked on some new PL/SQL packages and Forms which work quite well. They are efficient in their use of resources, and are easy for me to debug and maintain. After some other developers have had to do some changes (some from changes to requirements, some from bugs I didn’t find), I’ve learned that the highly modular style of code I use is difficult to modify without introducing new bugs.
The modular style is great while developing; it reduces duplication and provides useful abstractions. When it comes to maintaining that code, however, a new developer has to read all that code and follow its tortuous logic around in order to debug it. It’s much easier to just patch the existing code to force it to work.
This is obviously not the best outcome; more new code is added, instead of the existing code being fixed. The module thus becomes more complex and unmaintainable. After some time, a new developer confronts a hodge-podge of duplicated functionality and cut-and-paste monstrosities, and exclaims, “Who wrote this rubbish?” – perhaps with justification.
What I’ve learned is that after developing a new module, I must go back and refactor it to improve maintainability. This includes a number of steps (this list is not intended to be exhaustive):
- Delete simple wrappers for library functions/procedures, and replace all calls to them with calls to the original library functions/procedures.
- Don’t use constants for internal codes (e.g. names of items and blocks) – use literals instead.
- If a fairly simple function or procedure is only called once throughout the final code – delete it and move the code to where it was called from; the exception is if this would make the calling code more difficult to read or understand.
- Code that generates dynamic SQL should set the SQL in entirety in single statements if possible, instead of building it procedurally. Another developer should be able to easily find the exact SQL that will be generated just by looking at the code, instead of having to mentally build it procedurally, or having to printline the SQL and run it to see what it generates.
- Add comments that document the philosophy of how the code has been laid out.
Some examples to illustrate the above:
- We have a library procedure called lk_item.lp_show_item (pc_item, pn_visible, pn_enabled) which is used to show, hide, enable, and/or disable a form item. I wanted to write code like the following: lk_item.lp_show_item(‘my_item’, some_boolean_expression, another_boolean_expression) but I couldn’t because the parameters require PROPERTY_TRUE or PROPERTY_FALSE, which are numbers. My first cut included the following wrapper for lk_item.lp_show_item:
PROCEDURE cp_show_hide
(pc_item IN VARCHAR2
,pb_visible IN BOOLEAN
,pb_enabled IN BOOLEAN) IS
FUNCTION CF_PROPERTY_TF
(pb_value IN BOOLEAN) RETURN NUMBER IS
BEGIN
IF pb_value THEN
RETURN PROPERTY_TRUE;
ELSE
RETURN PROPERTY_FALSE;
END IF;
END;
BEGIN
lk_item.lp_show_item(pc_item,
CF_PROPERTY_TF(pb_visible),
CF_PROPERTY_TF(pb_enabled));
END;
In the end, however, I only called this procedure two times, and within a single procedure. So I deleted the wrapper procedure, and called lk_item.lp_show_item directly. I kept my Boolean expressions, but wrapped them in a locally declared function that did the translation.
FUNCTION CF_PROPERTY_TF
(pb_value IN BOOLEAN) RETURN NUMBER IS
BEGIN
IF pb_value THEN
RETURN PROPERTY_TRUE;
ELSE
RETURN PROPERTY_FALSE;
END IF;
END;
…
lk_item.lp_show_item(‘ITEM_NAME’,
CF_PROPERTY_TF(some expression),
CF_PROPERTY_TF(some other expression));
- I had a procedure that populated a large number of items in the block in response to the user selecting a new record. Because the user can select a new record using any of several different methods (effectively, different search criteria), I used a parameter called “search mode” that is set to various constant strings, e.g. “GNL_ID”, “OFF_ID_DETAILS”, “COLLAR_NO”. Some of these strings were named after significant database table columns, some were generic – they all, however, simply differentiated slightly different conditions under which the procedure must operate.
Initially I had a set of constants that took these values; however, because this code passed these values to a database package as well, the constants were defined in the database package as well. In the end the code was much simpler and easier to read by removing all the constants and just encoding the codes as literal strings.
- (no example)
- A first cut of the code might look like (this is a very simplified example):
cp_lexical := ‘SELECT aaa, bee, cee ‘;
IF (some expression) THEN
cp_lexical := cp_lexical || ‘, dee FROM bla ‘;
ELSE
cp_lexical := cp_lexical || ‘FROM dee, eff ‘;
END IF;
IF (some other expression) THEN
cp_lexical := cp_lexical
|| ‘, gee WHERE eee = eff AND gee = oh ‘;
ELSE
cp_lexical := cp_lexical
|| ‘, hat WHERE eee = oh AND ii = jay ‘;
END IF;
cp_lexical := cp_lexical
|| ‘ AND kay = ell AND emm = enn’;
The final, more easily maintained code would look something like:
IF (some expression)
AND (some other expression) THEN
cp_lexical := ‘SELECT aaa, bee, cee, dee ‘
|| ‘FROM bla, gee ‘
|| ‘WHERE eee = eff ‘
|| ‘AND gee = oh ‘
|| ‘AND kay = ell ‘
|| ‘AND emm = enn’;
ELSIF (some expression) THEN
cp_lexical := ‘SELECT aaa, bee, cee, dee ‘
|| ‘FROM bla, hat ‘
|| ‘WHERE eee = oh ‘
|| ‘AND ii = jay ‘
|| ‘AND kay = ell ‘
|| ‘AND emm = enn’;
ELSIF (some other expression) THEN
cp_lexical := ‘SELECT aaa, bee, cee ‘
|| ‘FROM dee, eff, gee ‘
|| ‘WHERE eee = eff ‘
|| ‘AND gee = oh ‘
|| ‘AND kay = ell ‘
|| ‘AND emm = enn’;
ELSE
cp_lexical := ‘SELECT aaa, bee, cee ‘
|| ‘FROM dee, eff, hat ‘
|| ‘WHERE eee = oh ‘
|| ‘AND ii = jay ‘
|| ‘AND kay = ell ‘
|| ‘AND emm = enn’;
END IF;
This doesn’t solve all the maintenance problems (i.e. if someone makes a change to one part of the code they might not know that they should make the same change everywhere else that code has been duplicated). However, it does make maintenance a bit easier because the code is easy to follow.
- I generally follow the following pattern when encapsulating logic in procedures and packages:
- Code that populates data in items (e.g. in response to changes in other items) is encapsulated in procedures or packages named POPULATE_xxx.
- Code that changes item properties (but not their values) is encapsulated in procedures or packages named SETUP_xxx.
- Code that checks data entry errors is encapsulated in procedures or packages named VALIDATE_xxx.
These conventions are documented so that another developer can more easily read the code; for example, a when-validate-item trigger might have code like this:
cp_validate_something;
cp_populate_something;
cp_setup_something;
The developer might still need to follow through all the code to debug it, but they might more easily see where the code should be. Hopefully they’ll recognise that validation code should go in cp_validate_something, rather than cp_populate_something.
Came across this in a form (6i) to be run on a 9i db. Not only is this code about 33 lines of code too long and issues any number of unnecessary database queries, its name is quite unrelated to its intended function. Needless to say it was easily replaced with a single call to INSTR.
PROCEDURE alpha_check
(ref_in IN VARCHAR2
,ref_out OUT VARCHAR2) IS
-- Procedure included to distinguish
-- ref_in between ID or reference.
l_alpha_char VARCHAR2 (1);
l_alpha_pos NUMBER;
l_found_pos NUMBER;
l_search_string VARCHAR2 (100) := ' ';
CURSOR cur_get_next_alpha(N NUMBER) IS
SELECT SUBSTR(l_search_string,N,1)
FROM dual;
CURSOR cur_check_for_alpha(C VARCHAR2)IS
SELECT INSTRB(ref_in,C, 1)
FROM dual;
BEGIN
IF ref_in IS NULL THEN
ref_out := 'X';
RETURN;
END IF;
FOR I IN 1..LENGTH(l_search_string) LOOP
OPEN cur_get_next_alpha(I);
FETCH cur_get_next_alpha
INTO l_alpha_char;
CLOSE cur_get_next_alpha;
FOR J IN 1..LENGTH(ref_in) LOOP
OPEN cur_check_for_alpha(l_alpha_char);
FETCH cur_check_for_alpha
INTO l_found_pos;
CLOSE cur_check_for_alpha;
IF l_found_pos > 0 THEN
ref_out := 'N';
RETURN;
END IF;
END LOOP;
END LOOP;
ref_out := 'Y';
EXCEPTION
WHEN OTHERS THEN
pc_ref_out := 'X';
END;
Looks like it may have been copied from the same source as “As bad as it gets”.
I’ve had to create test data a number of times, including data for tables that had mandatory foreign keys to existing tables. It was not feasible to just create new master rows for my test data; I wanted to refer to a random sample of existing data; but the code that generates the test data had to perform reasonably well, even though it had to pick out some random values from a very large table.
Solution? A combination of the new 10g SAMPLE operator, and DBMS_RANDOM. To illustrate:
(create a “very large table”)
SQL> create table t as
2 select rownum n, dbms_random.string(‘a’,30) v
3 from all_objects;
Table created.
SQL> select count(*) from t;
COUNT(*)
———-
40981
(get a random sample from the table)
SQL> select n, substr(v,1,30) from t sample(0.01)
2 order by dbms_random.value;
N SUBSTR(V,1,30)
———- ——————————
11852 xSsdmFtGqkymbKCFoZwUzNxpJAPwaV
8973 RGyNjqMfVayKdiKFGvLYuAFYUpIbCw
25295 eJJtoieSWtzUTIZXCbOLzmdmWHHPOy
297 hiTxUPYKzWKAjFRYTTfJSSCuOwGGmG
1924 yZucJWgkFviAIeXiSCuNeUuDjClvxt
40646 wMTumPxfBMoAcNtVMptoPchILHTXJa
6 rows selected.
SQL> set serveroutput on
(Get a single value chosen at random)
SQL> declare
2 cursor cur_t is
3 select n from t sample(0.01)
4 order by dbms_random.value;
5 l number;
6 begin
7 open cur_t;
8 fetch cur_t into l;
9 dbms_output.put_line(l);
10 close cur_t;
11* end;
SQL> /
21098
PL/SQL procedure successfully completed.
My test code would open the cursor, fetch as many values as it needed, and then close it. If the cursor ran out of values (e.g. the sample was too small for the desired amount of test data, which varied), my code just re-opened the cursor to fetch another set of random values from the large table.
The reason I sort the sample by dbms_random.value is so that if I only want one value, it is not weighted towards rows found nearer the start of the table.
Note: If I didn’t really care about the sample being picked at random from throughout the table, I could have just selected from the table “where rownum < n".
Seen in the wild:
SELECT ROWID
BULK COLLECT INTO t_rowids
FROM my_table
WHERE ...
FOR UPDATE NOWAIT;
IF t_rowids.COUNT > 0 THEN
FORALL i IN t_rowids.FIRST..t_rowids.LAST
DELETE FROM my_table
WHERE ROWID = t_rowids(i);
END IF;
Of course, we couldn’t just do a “DELETE FROM my_table WHERE …”, could we…
Answer this in your head before trying it out or looking it up. Assume the following script is run in a single session on an Oracle database:
CREATE SEQUENCE seq START WITH 1 INCREMENT BY 1;
CREATE TABLE t (a INTEGER, b INTEGER);
-- Statement #1
INSERT INTO t VALUES (seq.NEXTVAL, seq.NEXTVAL);
-- Statement #2
INSERT INTO t VALUES (seq.CURRVAL, seq.NEXTVAL);
-- Statement #3
INSERT INTO t VALUES (seq.CURRVAL, seq.CURRVAL);
Which of the following is/are true?
- The inserted rows will be {1,2}, {2,3} and {3,3}.
- The inserted rows will be {1,1}, {2,2} and {2,2}.
- The inserted rows will be {1,1}, {1,2} and {2,2}.
- Statements #2 and #3 will each raise “ORA-08002: sequence SEQ.CURRVAL is not yet defined in this session”.
Oracle Database SQL Reference 10g Release 1 (10.1): Datatype Comparison Rules – Numeric Values
“A larger value is considered greater than a smaller one.”
“All negative numbers are less than zero and all positive numbers.”
“-1 is less than 100; -100 is less than -1.”
On first reading these statements seem obvious. The more you read them, however, the more they take on a deeper meaning, a deeper structure and beauty that transcends this, sublimates that and begins subtly but inexorably to change the way you view the world. You start to question their simplicity – are they perhaps over-simplifications of a more complex reality? Well, perhaps not.
I guess they had to include these statements for completeness, since later they get into the more complicated cases of comparison rules for dates and strings, which are not (necessarily) so obvious. For example, I haven’t come across anyone who thinks 12 April 1961 is greater than 20 July 1969, but I’m sure there are some.
I came across this at dbdebunk (ON THE NOTHING THAT’S WRONG WITH NULLS with Hugh Darwen, Fabian Pascal). Couldn’t let that go so I tested it under 9i (9.1) and 10g (10.2) and got identical results. The last two statements are logically equivalent, but gives different results!
SQL> create type point as object (x real, y real);/
Type created.
SQL> create table t (p point);
Table created.
SQL> insert into t values (point(null, null));
1 row created.
SQL> insert into t values (point(1, null));
1 row created.
SQL> insert into t values (point(1, 2));
1 row created.
SQL> select * from t;
P(X, Y)
——————————————————————————–
POINT(NULL, NULL)
POINT(1, NULL)
POINT(1, 2)
SQL> select * from t where p=p or not p=p;
P(X, Y)
——————————————————————————–
POINT(1, 2)
SQL> select * from t where not p=p or p=p;
P(X, Y)
——————————————————————————–
POINT(1, NULL)
POINT(1, 2)
According to CM, it looks like a bug. The filter predicates seem to be applied incorrectly by the optimiser:
where ( p=p ) or ( not p=p );
filter(“T”.”SYS_NC00003$”=”T”.”SYS_NC00003$” AND
“T”.”SYS_NC00002$”=”T”.”SYS_NC00002$” OR T.”P”T.”P”)
where ( not p=p ) or ( p=p );
filter(T.”P”T.”P” OR “T”.”SYS_NC00002$”=”T”.”SYS_NC00002$”)
Jeffrey Kemp
11 February 2006
bug / SQL /
PL/SQL User’s Guide and Reference (10.2): “4 Using PL/SQL Control Structures – Using the NULL Statement”
“…Note that the use of the NULL statement might raise an unreachable code warning if warnings are enabled.”
Example 4-23 Using NULL as a Placeholder When Creating a Subprogram
CREATE OR REPLACE PROCEDURE award_bonus (emp_id NUMBER, bonus NUMBER) AS
BEGIN — executable part starts here
NULL; — use NULL as placeholder, raises “unreachable code” if warnings enabled
END award_bonus;
/
Indeed, when I compile the above in 10.2 with PL/SQL warnings on, I get PLW-06002 as expected (due to bug 3680132 I get “Message 6002 not found; No message file for product=plsql, facility=PLW” but at least I can look it up in the reference).
“PLW-06002: Unreachable code”
“Cause: Static program analysis determined that some code on the specified line would never be reached during execution.”
I agree that a PL/SQL warning would be desirable in the case where a procedure has nothing but a NULL in it (probably a stub). Correct me if I’m wrong, but if I were to call award_bonus, surely the NULL is “executed” – therefore, it is reachable! A more appropriate warning would be something like “function/procedure does nothing”, or “get back to work you silly mug, you’ve forgotten to finish the code”. Maybe they just couldn’t be bothered making up another warning code.
Jeffrey Kemp
11 February 2006
PL/SQL /
PL/SQL User’s Guide and Reference (9.2 and 10.2): “NULL Statement”
“The NULL statement and Boolean value NULL are unrelated.”
I can understand that this is to draw a distinction between “NULL” as a procedural statement and “NULL” as a literal. But why is NULL specifically identified as Boolean? So, the NULL statement is somehow related to NULL strings, NULL numbers, and NULL dates?
(I won’t even mention the problem with calling NULL a value, something which is prevalent throughout the literature, including the SQL standard.)
