I have an editable tabular form using APEX’s old greyscale edit link icons:
The users complained that they currently have to click each link to drill down to the detail records to find and fix any errors; they wanted the screen to indicate which detail records were already fine and which ones needed attention.
Since screen real-estate is limited here, I wanted to indicate the problems by showing a red edit link instead of the default greyscale one; since this application is using an old theme I didn’t feel like converting it to use Font Awesome (not yet, at least) and neither did I want to create a whole new image and upload it. Instead, I tried a CSS trick to convert the greyscale image to a red shade.
I used this informative post to work out what I needed: http://css-tricks.com/color-filters-can-turn-your-gray-skies-blue/
WARNING: Unfortunately this trick does NOT work in IE (tested in IE11). Blast.
Firstly, I added a column to the underlying query that determines if the error needs to be indicated or not:
select ...,
case when {error condition}
then 'btnerr' end as year1_err
from mytable...
I set the new column type to Hidden Column.
The link column is rendered using a Link-type column, with Link Text set to:
<img src="#IMAGE_PREFIX#e2.gif" alt="">
I changed this to:
<img src="#IMAGE_PREFIX#e2.gif" alt="" class="#YEAR1_ERR#">
What this does is if there is an error for a particular record, the class "btnerr" is added to the img tag. Rows with no error will simply have class="" which does nothing.
Now, to make the greyscale image show up as red, I need to add an SVG filter to the HTML Header in the page:
<svg style="display:none"><defs>
<filter id="redshader">
<feColorMatrix type="matrix"
values="0.7 0.7 0.7 0 0
0.2 0.2 0.2 0 0
0.2 0.2 0.2 0 0
0 0 0 1 0"/>
</filter>
</defs></svg>
I made up the values for the R G B lines with some trial and error. The filter is applied to the buttons with the btnerr class with this CSS in the Inline CSS property of the page:
img.btnerr {filter:url(#redshader);}
The result is quite effective:
But, as I noted earlier, this solution does not work in IE, so that’s a big fail.
NOTE: if this application was using the Universal Theme I would simply apply a simple font color style to the icon since it would be using a font instead of an image icon.
I’ve been aware of some of the ways that Oracle database optimises index accesses for queries, but I’m also aware that you have to test each critical query to ensure that the expected optimisations are taking effect.
I had this simple query, the requirement of which is to get the “previous status” for a record from a journal table. Since the journal table records all inserts, updates and deletes, and this query is called immediately after an update, to get the previous status we need to query the journal for the record most recently prior to the most recent record. Since the “version_id” column is incremented for each update, we can use that as the sort order.
select status_code
from (select rownum rn, status_code
from xxtim_requests$jn jn
where jn.trq_id = :trq_id
order by version_id desc)
where rn = 2;
The xxtim_requests$jn table has an ordinary index on (trq_id, version_id). This query is embedded in some PL/SQL with an INTO clause – so it will only fetch one record (plus a 2nd fetch to detect TOO_MANY_ROWS which we know won’t happen).
The table is relatively small (in dev it only has 6K records, and production data volumes are expected to grow very slowly) but regardless, I was pleased to find that (at least, in Oracle 12.1) it uses a nice optimisation so that it not only uses the index, it is choosing to use a Descending scan on it – which means it avoids a SORT operation, and should very quickly return the 2nd record that we desire.
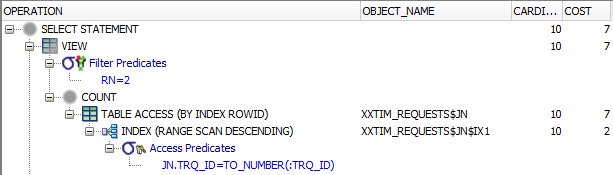
It looks quite similar in effect to the “COUNT STOPKEY” optimisation you can see on “ROWNUM=1” queries. If this was a much larger table and this query needed to be faster or was being run more frequently, I’d probably consider appending status_code to the index in order to avoid the table access. In this case, however, I don’t think it’s necessary.
If you have an Interactive Report with the Subscription feature enabled, users can “subscribe” to the report, getting a daily email with the results of the report. Unfortunately, however, this feature doesn’t work as expected if it relies on session state – e.g. if the query uses bind variables based on page items to filter the records. In this case, the subscription will run the query with a default (null) session state – APEX doesn’t remember what the page item values were when the user subscribed to the report.
The job that runs subscriptions, first sets the APEX globals (e.g. app ID, page ID) and evaluates any relevant authorizations (to check that the user still has access to the app, page and region); apart from that, only the query for the region is actually executed. Page processes are not executed, and page items with default values or expressions are not set and will be considered null if referred to by the query. In some cases you may be able to workaround this by using NVL or COALESCE in your query to handle null page items.
This is a query I used to quickly pick out all the Interactive Reports that have the Subscription feature enabled but which might rely on session state to work – i.e. it relies on items submitted from the page, refers to a bind variable or to a system context:
select workspace, application_id, application_name,
page_id, region_name, page_items_to_submit
from apex_application_page_ir
where show_notify = 'Yes'
and (page_items_to_submit is not null
or regexp_like(sql_query,':[A-Z]','i')
or regexp_like(sql_query,'SYS_CONTEXT','i')
);
For these reports, I reviewed them and where appropriate, turned off the Subscription feature. Note that this query is not perfect and might give some false positives and negatives.
Related idea for consideration: https://apex.oracle.com/ideas/FR-2393 – “Set up session for email subscription”
UPDATE (Mar 2022)
As of APEX 20.1, when a subscription is saved, the session is cloned, and the clone is used for all subsequent daily emails of the report. What this effectively means it that a snapshot of the value of each item in the application is taken (i.e. the value as stored in session state on the database) and this snapshot will provide values for any items used by the report.
In addition, the Database Session Initialization PL/SQL Code (under Security Attributes) is also executed, which is how you can initialise any application contexts that the report might need (e.g. for VPD).
Note that if the report relied on any APEX collections, these are not included in the clone; but reports that are based on collections should not generally be enabled for email subscriptions anyway.
I have an Interactive Report that includes some editable columns, and the users wanted to include some “quick picks” on these columns to make it easy to copy data from a previous period. The user can choose to type in a new value, or click the “quick pick” to quickly data-enter the suggested value.
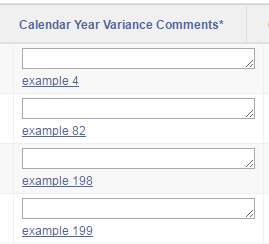
Normally, a simple page item can have a quick pick by setting the Show Quick Picks attribute on the item. This is not, however, available as an option when generating APEX items in a report.
To do this, I added code like the following to my report query: NOTE: don’t copy this, refer to ADDENDUM below
SELECT ...
,APEX_ITEM.textarea(5,x.ytd_comments
,p_rows => 1
,p_cols => 30
,p_item_id => 'f05_'||to_char(rownum,'fm00000'))
|| case when x.prev_ytd_comments is not null
then '<a href="javascript:$(''#'
|| 'f05_' || to_char(rownum,'fm00000')
|| ''').val('
|| apex_escape.js_literal(x.prev_ytd_comments)
|| ').trigger(''change'')">'
|| apex_escape.html(x.prev_ytd_comments)
|| '</a>'
end
as edit_ytd_comments
FROM my_report_view x;
This results in the following HTML code being generated:
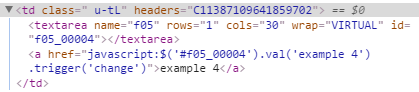
In the report definition, the EDIT_YTD_COMMENTS column has Escape Special Characters set to No. This runs a real risk of adding a XSS attack vector to your application, so be very careful to escape any user-entered data (such as prev_ytd_comments in the example above) before allowing it to be included. In this case, the user-entered data is rendered as the link text (so is escaped using APEX_ESCAPE.html) and also within some javascript (so is escaped using APEX_ESCAPE.js_literal).
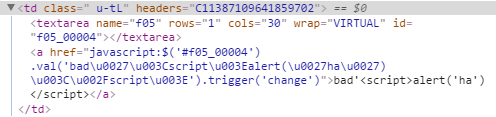
So, if the data includes any characters that conflict with html or javascript, it is neatly escaped:
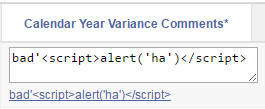
And it is shown on screen as expected, and clicking the link copies the data correctly into the item:
This technique should, of course, work with most of the different item types you can generate with APEX_ITEM.
Recommended further reading:
ADDENDUM 6/2/2017
A problem with the above code causes this to fail in Internet Explorer (IE11, at least) – when clicking on the quickpick, the user is presented with a page blank except for “[object Object]”. After googling I found this question on StackOverflow and fixed the problem by moving the jQuery code to a function defined at the page level.
I added this to the page Function and Global Variable Declaration:
function qp (id,v) {
$(id).val(v).trigger('change');
}
And modified the report query as follows:
SELECT ...
,APEX_ITEM.textarea(5,x.ytd_comments
,p_rows => 1
,p_cols => 30
,p_item_id => 'f05_'||to_char(rownum,'fm00000'))
|| case when x.prev_ytd_comments is not null
then '<a href="javascript:qp(''#'
|| 'f05_' || to_char(rownum,'fm00000')
|| ''','
|| apex_escape.js_literal(x.prev_ytd_comments)
|| ')">'
|| apex_escape.html(x.prev_ytd_comments)
|| '</a>'
end
as edit_ytd_comments
FROM my_report_view x;
I was writing a small javascript function, part of which needed to evaluate 10 to the power of a parameter – I couldn’t remember what the exponentiation operator is in javascript so as usually I hit F12 and typed the following into the console:
10**3

Wrote and tested the code, checked in to source control. Job done.
A few days later we deployed a new release that included dozens of bug fixes into UAT for testing. Soon after a tester showed me a screen where a lot of stuff wasn’t looking right, and things that had been working for a long time was not working at all.
Developer: “It works fine on my machine.”
After some playing around on their browser I noted that it seemed half of the javascript code I’d written was not running at all. A look at their browser console revealed two things:
- they are using Internet Explorer 11
- a compilation error was accusing the line with the ** operator
The error meant that all javascript following that point in the file was never executed, causing the strange behaviour experienced by the testers.
A bit of googling revealed that the ** operator was only added to javascript relatively recently and was supported by Chrome 52 and Edge browser but not IE. So I quickly rewrote it to use Math.pow(n,m) and applied a quick patch to UAT to get things back on track.
I think there’s a lesson there somewhere. Probably, the lesson is something like “if you try drive-by javascript coding, you’re gonna have a bad time.”
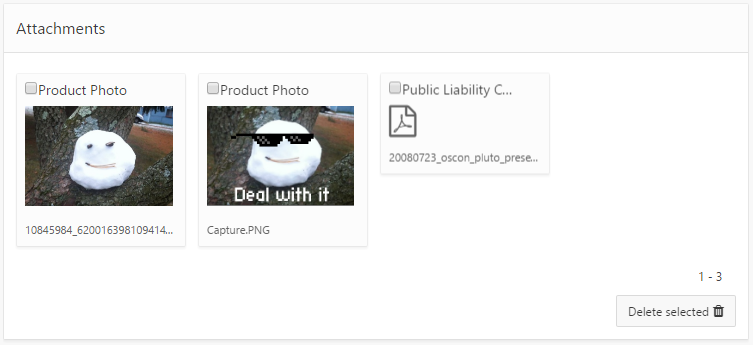 I wanted to use the “Cards” report template for a small report which lists file attachments. When the user clicks on one of the cards, the file should download and open in a new tab/window. Unfortunately, the Cards report template does not include a placeholder for extra attributes for the anchor tag, so it won’t let me add “target=_blank” like I would normally.
I wanted to use the “Cards” report template for a small report which lists file attachments. When the user clicks on one of the cards, the file should download and open in a new tab/window. Unfortunately, the Cards report template does not include a placeholder for extra attributes for the anchor tag, so it won’t let me add “target=_blank” like I would normally.
One solution is to edit the Cards template to add the extra placeholder; however, this means breaking the subscription from the universal theme.
As a workaround for this I’ve added a small bit of javascript to add the attribute after page load, and whenever the region is refreshed.
- Set report static ID, e.g. “mycardsreport”
- Add Dynamic Action:
- Event = After Refresh
- Selection Type = Region
- Region = (the region)
- Add True Action: Execute JavaScript Code
- Code =
$("#mycardsreport a.t-Card-wrap").attr("target","_blank"); (replace the report static ID in the selector)
- Fire On Page Load = Yes
Note: this code affects all cards in the chosen report.
“We always click ‘Apply Changes’, then we click the button we actually wanted” – a user
Typically an Apex report with an “Open” or “Edit” icon will simply do an immediate navigation to the target page, passing the ID of the record to edit. When the user clicks this link, the page is not submitted and the user is instead redirected.
It’s easy to quickly build large and complex applications in Apex but it’s also very easy to build something that confuses and disorients your users. They only need one instance when something doesn’t work how they expected it to, and they will lose trust in your application.
For example: if most buttons save their changes, but one button doesn’t, they might not notice straight away, and then wonder what happened to their work. If you’re lucky, they will raise a defect notice and you can fix it. More likely (and worse), they’ll decide it’s their fault, and begrudgingly accept slow and unnecessary extra steps as part of the process.
You can improve this situation by taking care to ensure that everything works the way your users expect. For most buttons in an Apex page, this is easy and straightforward: just make sure the buttons submit the page. The only buttons that should do a redirect are those that a user should expect will NOT save the changes – e.g. a “Cancel” button.
For the example of an icon in a report region, it’s not so straightforward. The page might include some editable items (e.g. a page for editing a “header” record) – and if the user doesn’t Save their changes before clicking the report link their changes will be lost on navigation.
To solve this problem you can make the edit links first submit the page before navigating. The way I do this is as follows (in this example, the report query is on the “emp” table:
- Add a hidden item
P1_EDIT_ID to the page
- Set Value Protected to No
- Add something like this to the report query (without the newlines):
'javascript:apex.submit(
{request:''SAVE_EDIT_ROW'',
set:{''P1_EDIT_ID'':''' || emp.rec_id || '''}
})' AS edit_link
- Set this new column to Hidden Column
- Modify the edit link Target:
- Type = URL
- URL =
#EDIT_LINK#
- Add a Branch at point “After Processing”
- Modify any existing Processing so that the request SAVE_EDIT_ROW will cause any changes on the page to be saved.
You can, of course, choose different item names and request names if needed (just update it in the code you entered earlier). For example, to make it work with the default Apex DML process you might need to use a request like “APPLY_CHANGES_EDIT_ROW”.
Now, when the user makes some changes to the form, then clicks one of the record Edit links, the page will first be submitted before navigating to the child row.
Adding buttons to Apex pages is easy. Making sure every last one of them does exactly what the user expects, nothing more, and nothing less, is the tricky part!
UPDATE 11/10/2018 – new feature added in Oracle SQL Developer 18.3
Juergen Schuster, who has been enthusiastically trying OraOpenSource Logger, raised an idea for the debug/instrumentation library requesting the addition of a standard synonym “l” for the package. The motive behind this request was to allow our PL/SQL code to remain easy to read, in spite of all the calls to logger sprinkled throughout that are needed for effective debugging and instrumentation.
In the judgement of some (myself included) the addition of the synonym to the standard package would run the risk of causing clashes on some people’s systems; and ensuring that Logger is installable on all systems “out of the box” should, I think, take precedence.
However, the readability of code is still an issue; so it was with that in mind that I suggested that perhaps an enhancement of our favourite development IDE would go a long way to improving the situation.
Therefore, I have raised the following enhancement request at the SQL Developer Exchange:
Logger: show/hide or dim (highlight) debug/instrumentation code
“The oracle open source Logger instrumentation library is gaining popularity and it would be great to build some specific support for it into SQL Developer, whether as a plugin or builtin. To enhance code readability, it would be helpful for PL/SQL developers to be able to hide/show, or dim (e.g. grey highlight) any code calling their preferred debug/instrumentation library (e.g. Logger).
“One way I expect this might work is that the Code Editor would be given a configurable list of oracle object identifiers (e.g. “logger”, “logger_logs”); any PL/SQL declarations or lines of code containing references to these objects would be greyed out, or be able to be rolled up (with something like the +/- gutter buttons).”
Mockup #1 (alternative syntax highlighting option):

Mockup #2 (identifier slugs in header bar to show/hide, with icons in the gutter showing where lines have been hidden):
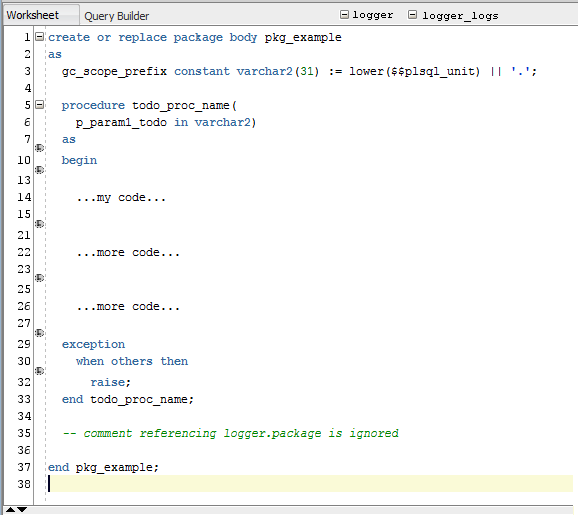
“Gold-plated” Option: add an option to the SQL Editor’s right-click context menu – on any identifier, select “Hide all lines with reference to this” and it adds the identifier to the list of things that are hidden!
If you like the idea (or at least agree with the motive behind it) please vote for it.
Oracle 12c introduced the ability to specify sequence.nextval as the default on a column, which is really nice – including the fact that it eliminates one of your excuses why you don’t decommission those old triggers.
Unfortunately it doesn’t work as you might expect if you use an INSERT ALL statement; it evaluates the default expression once per statement, instead of once per row.
Test case:
create sequence test_seq;
create table test_tab
( id number default test_seq.nextval primary key
, dummy varchar2(100) not null );
insert into test_tab (dummy) values ('xyz');
1 row inserted.
insert all
into test_tab (dummy) values ('abc')
into test_tab (dummy) values ('def')
select null from dual;
Error report -
SQL Error: ORA-00001: unique constraint
(SCOTT.SYS_C00123456) violated
A minor issue, usually, but something to be aware of – especially if you’re not in the habit of declaring your unique constraints to the database!
create sequence test_seq;
create table test_stupid_tab
( id number default test_seq.nextval
, dummy varchar2(100) not null );
insert into test_tab (dummy) values ('xyz');
1 row inserted.
insert all
into test_tab (dummy) values ('abc')
into test_tab (dummy) values ('def')
select null from dual;
2 rows inserted.
select * from test_tab;
i dummy
= =====
1 xyz
2 abc
2 def
ADDENDUM 28/10/2016
Another similar scenario which might trip you up is where you are inserting from a UNION view:
create sequence test_seq;
create table test_tab
( id number default test_seq.nextval primary key
, dummy varchar2(100) not null
);
insert into test_tab (dummy) select 'x' from dual;
-- success
insert into test_tab (dummy)
select 'y' from dual union all select 'z' from dual;
-- fails with ORA-01400 "cannot insert NULL into id"
insert into test_tab (dummy) select c from (
select 'y' c from dual union all select 'z' from dual
);
-- success
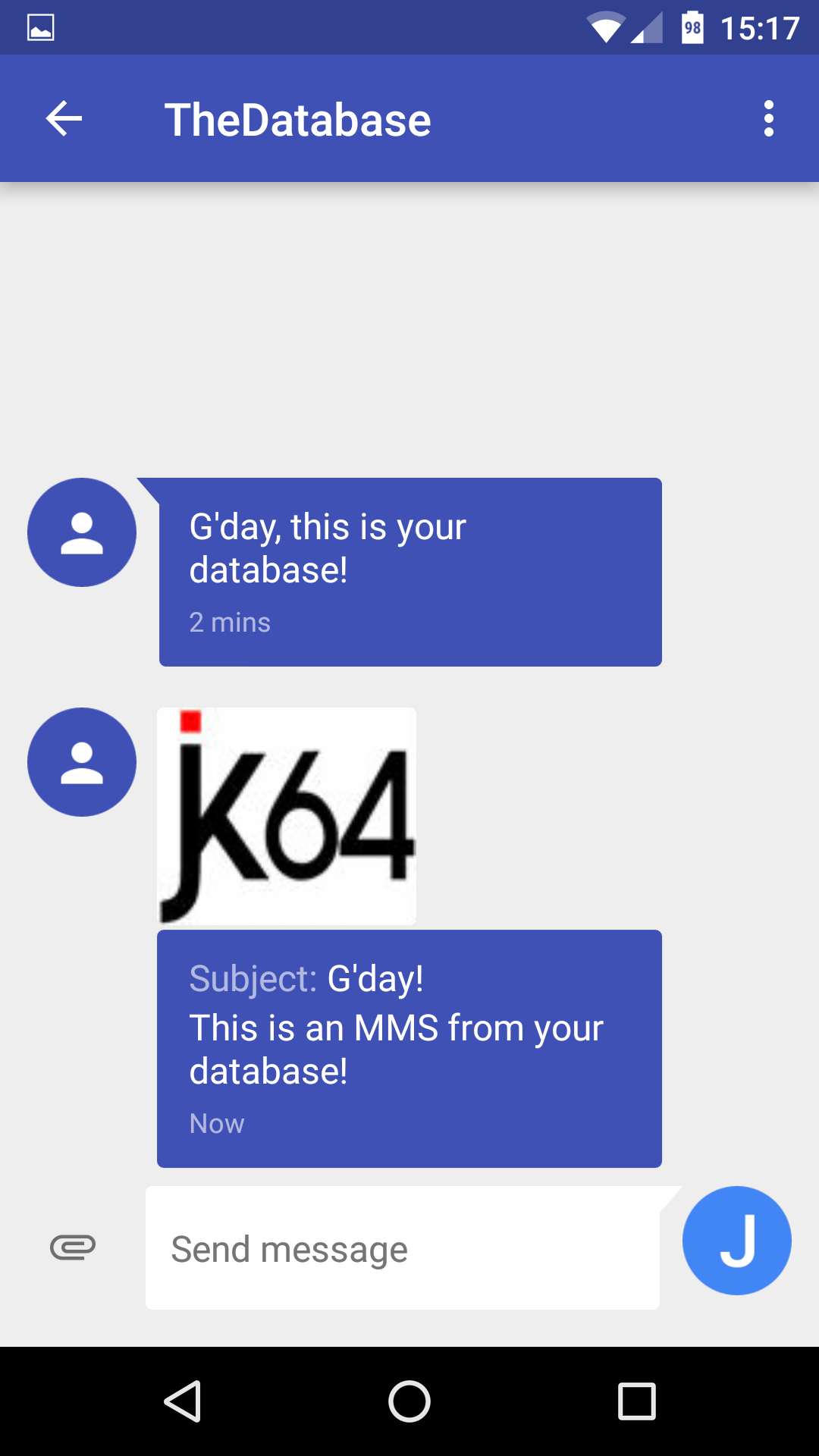
If you need to send almost any message to almost any phone from your Oracle database, and you want to use straight PL/SQL, you may want to consider using my Clicksend API.
- SMS (Short Message Service)
- MMS (Multimedia Message Service)
- Text to Voice
I have released the first beta version of my Oracle PL/SQL API for Clicksend. Read the installation instructions, API reference and download the release from here:
http://jeffreykemp.github.io/clicksend-plsql-api/
Sending an SMS is as simple as adding this anywhere in your code:
begin
clicksend_pkg.send_sms
(p_sender => 'TheDatabase'
,p_mobile => '+61411111111'
,p_message => 'G''day, this is your database!'
);
clicksend_pkg.push_queue;
commit;
end;
All you need to do is signup for a Clicksend account. You’ll only be charged for messages actually sent, but they do require you to pay in advance – e.g. $20 gets you about 300 messages (Australian numbers). You can get test settings so that you can try it out for free.
I’ve been using Clicksend for years now, and have been satisfied with their service and the speed and reliability of getting messages to people’s mobiles. When I encountered any issues, a chat with their support quickly resolved them, and they were quick to offer free credits when things weren’t working out as expected.
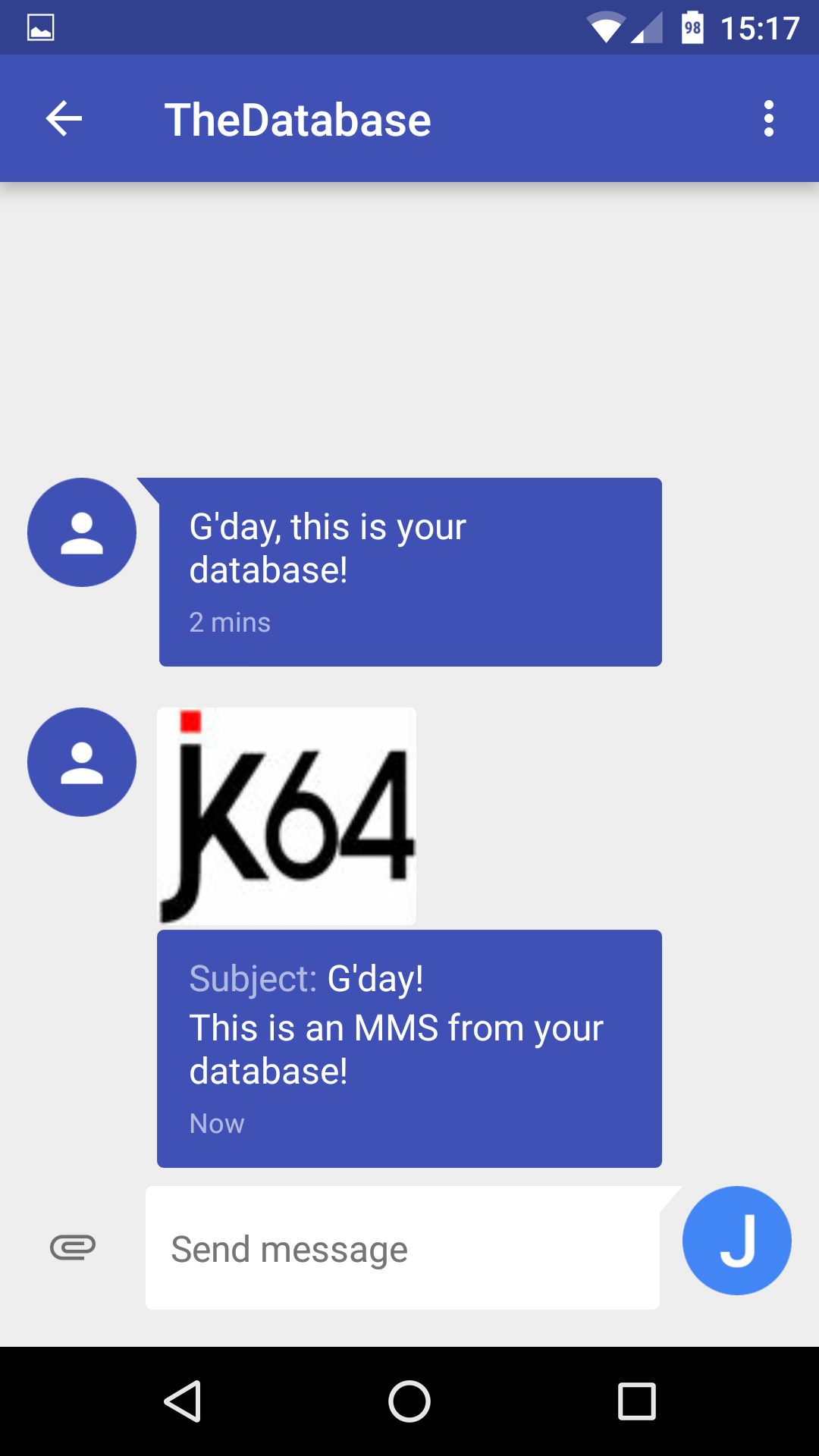
If you want to send a photo to someone’s phone via MMS (although I’m not sure what the use-case for this might be), you need to first upload the image somewhere online, because the API only accepts a URL. In my case, I would use the Amazon S3 API from the Alexandria PL/SQL Library, then pass the generated URL to the clicksend API. There is a file upload feature that ClickSend provides, I plan to add an API call to take advantage of this which will make this seamless – and provide some file conversion capabilities as well.
begin
clicksend_pkg.send_mms
(p_sender => 'TheDatabase'
,p_mobile => '+61411111111'
,p_subject => 'G''Day!'
,p_message => 'This is an MMS from your database!'
,p_media_file_url =>
'http://s3-ap-southeast-2.amazonaws.com/jk64/jk64logo.jpg'
);
clicksend_pkg.push_queue;
commit;
end;
You can send a voice message to someone (e.g. if they don’t have a mobile phone) using the Text to Voice API.
begin
clicksend_pkg.send_voice
(p_phone_no => '+61411111111'
,p_message => 'Hello. This message was sent from your database. '
|| 'Have a nice day.'
,p_voice_lang => 'en-gb' -- British English
,p_voice_gender => 'male'
,p_schedule_dt => sysdate + interval '2' minute
);
clicksend_pkg.push_queue;
commit;
end;
You have to tell the API what language the message is in. For a number of languages, you can specify the accent/dialect (e.g. American English, British English, or Aussie) and gender (male or female). You can see the full list here.
All calls to the send_sms, send_mms and send_voice procedures use Oracle AQ to make the messages transactional. It’s up to you to either COMMIT or ROLLBACK, which determines whether the message is actually sent or not. All messages go into a single queue.
You can have a message be scheduled at a particular point in time by setting the p_schedule_dt parameter.
The default installation creates a job that runs every 5 minutes to push the queue. You can also call push_queue directly in your code after calling a send_xxx procedure. This creates a job to push the queue as well, so it won’t interfere with your transaction.
All messages get logged in a table, clicksend_msg_log. The log includes a column clicksend_cost which allows you to monitor your costs. To check your account balance, call get_credit_balance.
Please try it out if you can and let me know of any issues or suggestions for improvement.
Link: http://jeffreykemp.github.io/clicksend-plsql-api/