I was working on an application in an APEX instance that was not configured for email (and would not be), but a number of interactive reports were allowing users to use the “Subscription” or the “Download as Email” features. If they tried these features, those emails would just go into the APEX mail queue and never go anywhere, so I needed to turn these off.
I listed all the interactive reports that need fixing with this query:
select page_id
,region_name
,show_notify
,download_formats
from apex_application_page_ir
where application_id = <my app id>
and (show_notify = 'Yes' or instr(download_formats,'EMAIL') > 0);
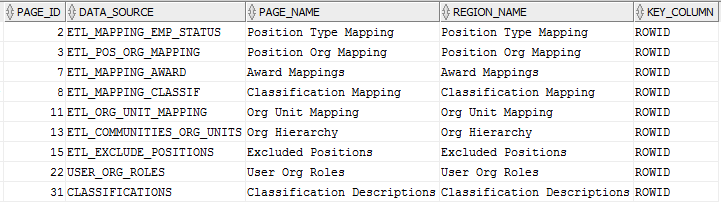
I needed to get a list of all the tabular forms in my application along with which table they were based on. This query did the trick:
select page_id
,attribute_02 as data_source
,page_name
,region_name
,attribute_03 as key_column
from apex_application_page_proc
where application_id = ...my app id...
and process_type_code = 'MULTI_ROW_UPDATE'
order by 1, 2;
If you have an ordinary Oracle APEX form with the standard Automatic Row Fetch process, and the page has an optional item with a default value, APEX will set the default on new records automatically. However, if the user queries an existing record, Oracle APEX will also fill in a missing value with the default value. This might not be what is desired – if the user clears the value they would expect it will stay cleared.
If you only want the default to be applied for new records, change the attribute on the item so that the default is only applied to new records:
Set Default Value Type to PL/SQL Expression
Set Default value to something like: case when :P1_ID is null then 'xyzzy' end
APEX_EXPORT – new package with supported methods for exporting APEX applications and other scripts into a CLOB: get_application, get_workspace_files, get_feedback, get_workspace
APEX_JWT – new package for JSON Web Tokens – encode, decode, validate
APEX_SESSION – new procedures: create_session, delete_session, attach, detach
What I’m particularly looking for is a good reference for the interactiveGrid API. Hopefully they’ll add this soon. There is a reference for a “grid” widget but that is not the API for interactive grids. I notice there are APIs for actions and model which are relevant to interactive grids.
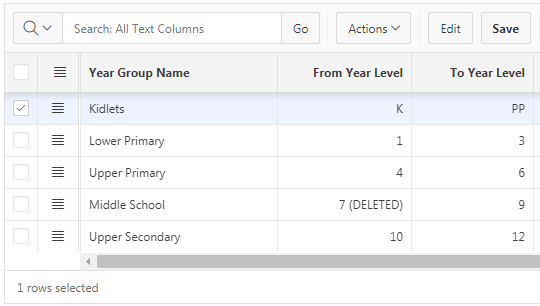
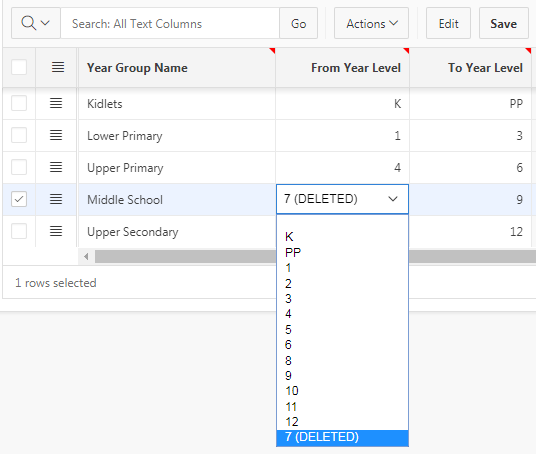
I had a column in an editable interactive grid based on a Select List, which takes valid values from a table that supports “soft delete” – i.e. records could be marked as “deleted” without affecting existing references to those deleted records.
The SQL Query for the LOV was like this (my example is a view on a reference table of school “year levels”):
select name, id from year_levels_vw
where deleted_ind is null
order by sort_order
The problem is that if a year level is marked as deleted, the select list will not include it due to the where clause; since Display Extra Values is set to “Yes”, the item on the page will instead show the internal ID which is not very useful to the user. Instead, I want to show the name but appended with a string to show it has been deleted:
select name
|| case when deleted_ind = 'Y' then ' (DELETED)' end
as disp_name, id
from year_levels_vw
order by deleted_ind nulls first, sort_order
So now the select list shows the name, even if it has been deleted. However, once users start using this system and they delete some year levels, each select list will include all the deleted values, even if they will never be used again. We’d prefer to only include a deleted value IF it is currently used by the record being viewed; otherwise, we want to omit it from the list.
If this was an APEX item in a single-record edit form, I’d simply change the SQL Query for the LOV to:
select name
|| case when deleted_ind = 'Y' then ' (DELETED)' end
as disp_name, id
from year_levels_vw
where deleted_ind is null or id = :P1_FROM_YEAR_LEVEL_ID
order by deleted_ind nulls first, sort_order
This way, the select list will only include the deleted year level if the underlying item was already set to that deleted ID. But we are now using an Interactive Grid – there is no page item to refer to.
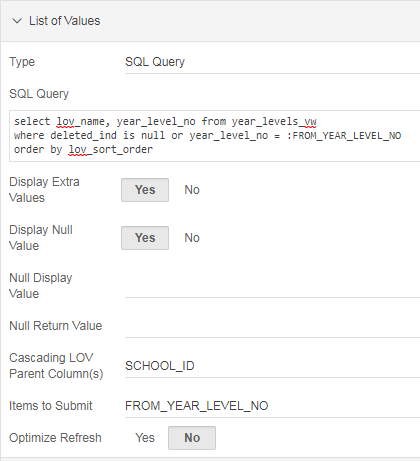
The method I’ve used to solve this is to take advantage of the Cascading LOV feature in order to allow the query to refer to the value of the column. The SQL Query for the LOV on my Interactive Grid is:
select name
|| case when deleted_ind = 'Y' then ' (DELETED)' end
as disp_name, id
from year_levels_vw
where deleted_ind is null or id = :FROM_YEAR_LEVEL_ID
order by deleted_ind nulls first, sort_order
Now, we need to make sure that “FROM_YEAR_LEVEL_ID” is available to the query, so we need to put it in the Items to Submit attribute. To make this attribute available, however, we must set Cascading LOV Parent Column(s) to something; I set it to the PK ID of the table, or some other column which doesn’t get changed by the user and isn’t actually referred to in the LOV Query.
Now, records not referring to a deleted value show only valid values:
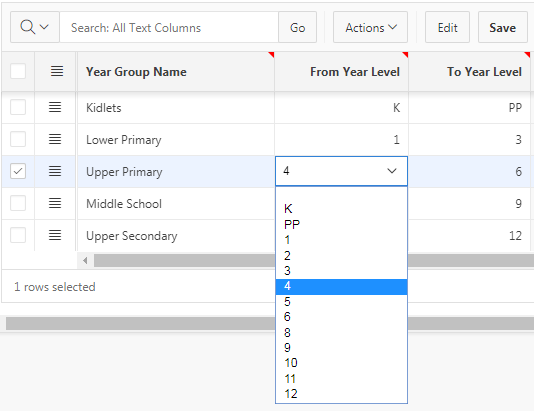
And records that refer to a deleted value include the deleted value in the list, as desired:
It should be noted that the design of the select list means that the user is allowed to save changes to the record while preserving the reference to the deleted year level. This is desired, in this case; if it wasn’t, however, I’d consider putting a validation on the page to stop the record being saved unless the user changes it to a valid value.
P.S. Concerned parents should note that this example was just testing the ability to delete a record from a database, and I’d just like to make it totally clear that there are no plans by the department to eliminate year 7 from schools. Honest!
ADDENDUM (19/3/2018):
There are two known issues:
If the item is the child of a Cascading LOV, when the parent item is changed, APEX automatically clears out any value in the child before rendering the list of values – which means the column value submitted will be NULL – which means the “deleted” items disappear from the list immediately. This means the user will not be allowed to save the record with a reference to a deleted value from the list.
The column filter list of values is empty – this is due to a known bug in APEX [Doc ID 2289512.1 FILTER NOT WORKING IN INTERACTIVE GRID WITH CASCADING LOV]. [thanks to Dejan for alerting me to this]
I received a question today from a developer who wanted to write a single static SQL query that could handle multiple optional parameters – i.e. the user might choose to leave one or more of the parameters NULL, and they’d expect the query to ignore those parameters. This is a quite common requirement for generic reporting screens, and there are two different methods commonly used to solve it.
Their sample query, using bind variables (natch), never returned any rows if any of the bind variables were null:
SELECT * FROM emp
WHERE job = :P_JOB
AND dept = :P_DEPT
AND city = :P_CITY
This is expected, of course, because “x = null” always evaluates to “unknown”, and this causes the rows to be omitted.
Option 1: add “OR v NOT NULL”, e.g.
SELECT * FROM emp
WHERE (job = :P_JOB OR :P_JOB IS NULL)
AND (dept = :P_DEPT OR :P_DEPT IS NULL)
AND (city = :P_CITY OR :P_CITY IS NULL)
Option 2: use NVL, e.g.
SELECT * FROM emp
WHERE job = NVL(:P_JOB, job)
AND dept = NVL(:P_DEPT, dept)
AND city = NVL(:P_CITY, city)
If the columns in the table do not have NOT NULL constraints on them, Option #2 will fail to return rows that have NULL in the relevant column – regardless of whether the user parameter is null or not. This is because “job = job” will always be “unknown” if job is null. In this case, Option #1 must be used.
If the columns do have NOT NULL constraints on them, then both Option #1 and Option #2 will work just fine. However, given the choice I would use Option #2 in order to take advantage of the potential performance optimisation that Oracle 12 can do with these types of NVL queries. There is a 3rd option, which is identical to Option #2 except that it uses the COALESCE function instead of NVL – but I would avoid this option as it will not get the performance optimisation.
On the other hand, if any of the attributes is the result of a costly operation (e.g. a function call), I would always use Option #1 (“OR NULL”) instead, because the NVL does not use short-circuit evaluation to avoid multiple function calls.
If there is a mix of columns that have NOT NULL constraints and others that don’t, I don’t really see any problem with mixing the two methods, e.g. in the case where dept has a NOT NULL constraint but job and city don’t:
SELECT * FROM emp
WHERE (job = :P_JOB OR :P_JOB IS NULL)
AND dept = NVL(:P_DEPT, dept)
AND (city = :P_CITY OR :P_CITY IS NULL)
Here’s a question for you to think about. What if the business rule states that the report should omit records where a column is null (i.e. the column may have nulls but they don’t want those records to ever appear in the report)? You may as well use NVL, e.g. in the case where dept has a NOT NULL constraint, but job and city don’t, but the report should omit records where job is null:
SELECT * FROM emp
WHERE job = NVL(:P_JOB, job)
AND dept = NVL(:P_DEPT, dept)
AND (city = :P_CITY OR :P_CITY IS NULL)
You might argue that future developers might be confused by the above query; it’s not exactly clear whether the developer intended to omit the records with null jobs, or if they made a mistake. Code comments might help, but alternatively you might choose to make the rule explicit, e.g.:
SELECT * FROM emp
WHERE job = NVL(:P_JOB, job) AND job IS NOT NULL
AND dept = NVL(:P_DEPT, dept)
AND (city = :P_CITY OR :P_CITY IS NULL)
If you feel strongly about this one way or another, please leave your comments below 🙂
This topic is a reminder that when there are multiple possible solutions to a problem, the choice should not be taken arbitrarily; and we should avoid enshrining one choice in any standards document as the “one true way”. This is because the answer is often “it depends” – different options may be valid for different scenarios, and have advantages and disadvantages that need to be taken into account.
So you’ve built an APEX application to solve a problem for one client, or one department, or just yourself – and you think it might be useful for others as well. How do you make that application available for other users, departments, or companies to reuse, while ensuring each sees only their own data and cannot mess around with others’ data?
Architecting a Multi-Tenant Application
To make your application multi-tenant you have a few options.
Option #1. Copy the application to another workspace/schema, another Pluggable Database (in Oracle 12c+) or another database server entirely.
Option #2. Modify your data model to allow completely independant sets of data to co-exist in the same physical tables (e.g. a security_group_id column that allows the database to discriminate data for each tenant).
The desirable properties of a multi-tenant system are as follows:
a. Tenant isolation – no tenant sees data for another tenant; no tenant can affect the app’s behaviour for another tenant; protect against “noisy neighbours” (i.e. those which impact system capacity and performance).
b. Administration – ability to backup/recover all data for a single tenant; ability to give a degree of control to each tenant (self service).
c. Maintainability – simplicity of deploying enhancements and bug fixes for all tenants, or for one tenant at a time (e.g. rolling upgrades).
d. Scalability – ability to easily add more tenants, ability to add more capacity for more tenants.
Some of these properties are more easily and effectively achieved with option #1 (separate servers or schemas for each tenant), such as Isolation and Administration. Other properties are more easily and effectively achieved with option #2 (discriminator column) such as Maintainability and Scalability. This is a gross generalisation of course; there are many solutions to this design problem each with many pros and cons.
Some inspiration may be gained from examining how Oracle Application Express achieves this goal: multi-tenant has been baked into the product, via its concept of Workspaces. Each tenant can be given their own workspace in APEX and are able to build and deploy applications in isolation from other workspaces. Internally, APEX maintains a unique security_group_id for each workspace. This works very well – a single Oracle database instance can serve thousands or tens of thousands of workspaces.
It should be noted that a benefit of pursuing Option #2 is that it does not necessarily preclude using Option #1 as well, should the need arise later on – for example, to provide more capacity or better performance in the presence of more demanding tenants. For this reason, plus the fact that it’s much easier to maintain and enhance an application for all users at once if they’re colocated, I prefer Option #2. Continue Reading →
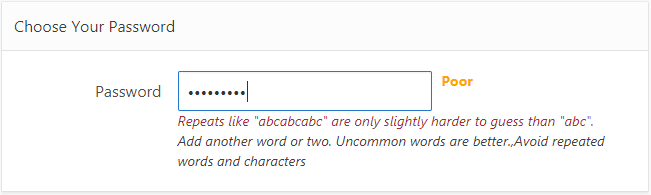
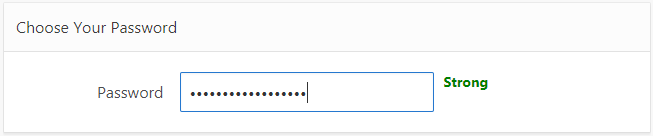
I needed a simple password strength prompt for users when they need to create or change their password on my website. After a bit of Googling I found the “Low-Budget Password Strength Estimator” which is supposedly used by Dropbox, so you know it’s good 🙂
This simple javascript library runs entirely within the client’s browser, and when presented with a candidate password, gives a score from 0 (very poor) to 4 (very good). It can also return extra feedback, including a warning message for poor passwords, as well as suggestions for making a password more secure.
So I’ve created a very simple Dynamic Action plugin (try the demo here) that allows you to add this functionality to any item on your page. You can specify a minimum length for the password, and can override the default messages for each score. You can also select whether or not the feedback warnings or suggestions are shown.
It seems to catch a lot of poor passwords, including ones comprising common words and names, and ones involving a simple sequence or repetition.
Obviously it’s only really useful for password entry fields; but don’t use it on your Login page!
Every Interactive Report has an optional set of “Link” attributes that allow you to specify the location where the user should be redirected if they click a link next to a record in the report. You can choose “Link to Custom Target” and use the Link Builder to easily specify the target application, page, item values to pass, and other attributes.
What if the report combines different entities, and you need to direct the user to a different page depending on the type of entity? Or, if you need to direct the user to a different page with different attributes depending on the status of the record?
One method is to generate the URL in the report query using apex_page.get_url (APEX 5+) or apex_util.prepare_url (APEX 4 or earlier), or (God forbid) you could generate the url yourself using string concatenation.
A more declarative solution is to instead use APEX page redirects. This solution involves the following:
Add some hidden items to the page to store the parameters for each target page;
Add a Branch to the page for each target page; and
Add a Request to the link to signal the page that a redirect has been requested.
NOTE This method does not work as described if you want to navigate to a modal page.
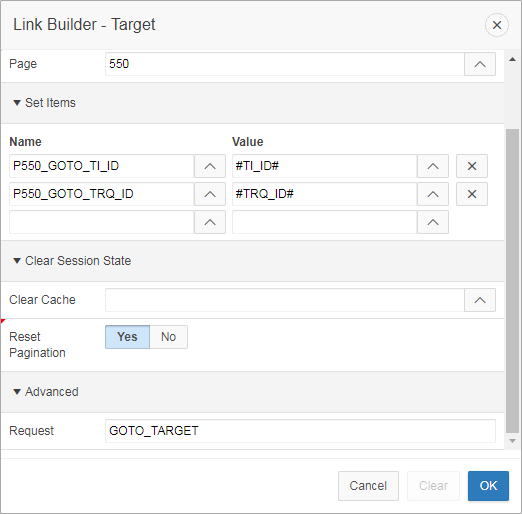
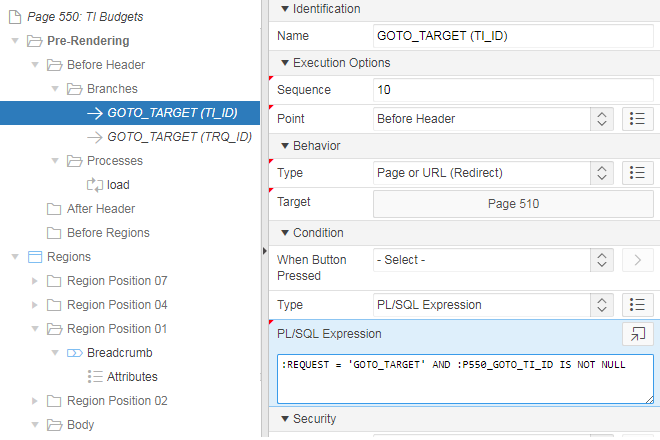
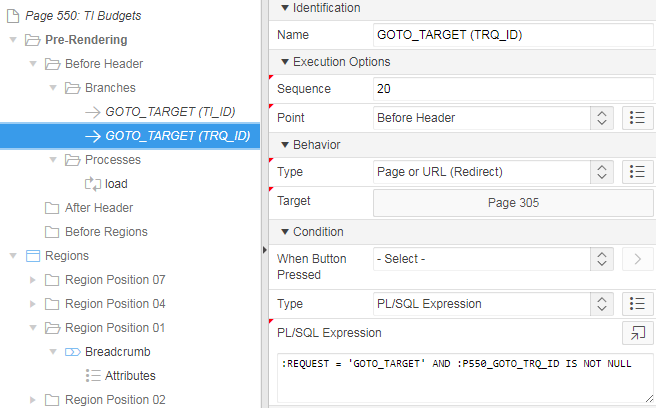
Here’s an example. My page 550 has an interactive report which combines TI records with TRQ records (both of which have a very similar structure). If the user clicks on a TI record they should be redirected to p510 with the corresponding TI_ID, and if they click on a TRQ record they should be redirected to p305 with the corresponding TRQ_ID.
Here’s the link attributes for this report:
Notice that the page now redirects back to itself with the request set to “GOTO_TARGET”, along with the IDs required. My report query has been constructed so that every record will only have a TI_ID or a TRQ_ID, never both at the same time; so the link will ensure that only one of the P550_GOTO_xxx_ID values will be set.
The page then just needs two Branches: one for each target. Conditions on each branch ensures they only get activated if the request has been set, and the branch is selected based on which “GOTO ID” item has been set:
For a normal navigation to this report (e.g. from another page), the request should be blank (or some other value) so none of the Branches should be triggered.
For a relatively simple scenario like this, I like the declarative approach. Each branch can take advantage of the full range of APEX features such as the link builder, security conditions, build options, etc.
Note: this method works just as well for Classic report links as well.
The thing to be mindful of is that the order of the branches, and the condition on each branch, must be carefully selected so that the correct branch is activated in each situation. I’ve shown a simple example which works because I have ensured that only one of the ID parameters is set at the same time. If a record has both IDs, the condition on the first branch “GOTO_TARGET (TI_ID)” will evaluate to True and it will be used, regardless of what GOTO_TRQ_ID was set to.
If there were numerous potential destination pages, with a large number of parameters to pass, I might choose the apex_page.get_url method instead. This is also what I’d usually do if the target was a modal page; alternatively, I’d use a “redirector” modal page as described in the comments below.
The order in which your deployment scripts create views is important. This is a fact that I was reminded of when I had to fix a minor issue in the deployment of version #2 of my application recently.
Normally, you can just generate a create or replace force view script for all your views and just run it in each environment, then recompile your schema after they’re finished – and everything’s fine. However, if views depend on other views, you can run into a logical problem if you don’t create them in the order of dependency.
Software Release 1.0
create table t (id number, name varchar2(100));
create or replace force view tv_base as
select t.*, 'hello' as stat from t;
create or replace force view tv_alpha as
select t.* from tv_base t;
desc tv_alpha;
Name Null Type
---- ---- -------------
ID NUMBER
NAME VARCHAR2(100)
STAT CHAR(5)
Here we have our first version of the schema, with a table and two views based on it. Let’s say that the tv_base includes some derived expressions, and tv_alpha is intended to do some joins on other tables for more detailed reporting.
Software Release 1.1
alter table t add (phone varchar2(10));
create or replace force view tv_alpha as
select t.* from tv_base t;
create or replace force view tv_base as
select t.*, 'hello' as stat from t;
Now, in the second release of the software, we added a new column to the table, and duly recompiled the views. In the development environment the view recompilation may happen multiple times (because other changes are being made to the views as well) – and nothing’s wrong. Everything works as expected.
However, when we run the deployment scripts in the Test environment, the “run all views” script has been run just once; and due to the way it was generated, the views are created in alphabetical order – so tv_alpha was recreated first, followed by tv_base. Now, when we describe the view, we see that it’s missing the new column:
desc tv_alpha;
Name Null Type
---- ---- -------------
ID NUMBER
NAME VARCHAR2(100)
STAT CHAR(5)
Whoops. What’s happened, of course, is that when tv_alpha was recompiled, tv_base still hadn’t been recompiled and so it didn’t have the new column in it yet. Oracle internally defines views with SELECT * expanded to list all the columns. The view won’t gain the new column until we REPLACE the view with a new one using SELECT *. By that time, it’s too late for tv_alpha – it had already been compiled, successfully, so it doesn’t see the new column.
Lesson Learnt
What should we learn from this? Be wary of SELECT * in your views. Don’t get me wrong: they are very handy, especially during initial development of your application; but they can surprise you if not handled carefully and I would suggest it’s good practice to expand those SELECT *‘s into a discrete list of columns.
Some people would go so far as to completely outlaw SELECT *, and even views-on-views, for reasons such as the above. I’m not so dogmatic, because in my view there are some good reasons to use them in some situations.

 So you’ve built an APEX application to solve a problem for one client, or one department, or just yourself – and you think it might be useful for others as well. How do you make that application available for other users, departments, or companies to reuse, while ensuring each sees only their own data and cannot mess around with others’ data?
So you’ve built an APEX application to solve a problem for one client, or one department, or just yourself – and you think it might be useful for others as well. How do you make that application available for other users, departments, or companies to reuse, while ensuring each sees only their own data and cannot mess around with others’ data? a. Tenant isolation – no tenant sees data for another tenant; no tenant can affect the app’s behaviour for another tenant; protect against “noisy neighbours” (i.e. those which impact system capacity and performance).
a. Tenant isolation – no tenant sees data for another tenant; no tenant can affect the app’s behaviour for another tenant; protect against “noisy neighbours” (i.e. those which impact system capacity and performance).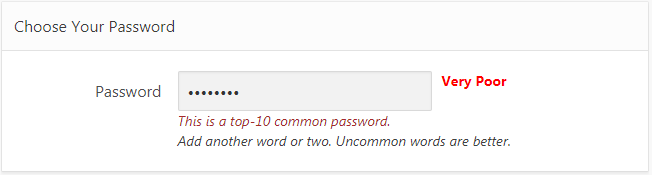


 The order in which your deployment scripts create views is important. This is a fact that I was reminded of when I had to fix a minor issue in the deployment of version #2 of my application recently.
The order in which your deployment scripts create views is important. This is a fact that I was reminded of when I had to fix a minor issue in the deployment of version #2 of my application recently.