I had this problem with an APEX application I’m building, and finally found the cause this morning, so I thought I’d share it.
This particular application has some pages which are only available to authenticated users, and some pages which are visible to everyone. One nice thing about APEX is that it automatically redirects users to the Login screen if they try to navigate to a protected page.
After authentication, the user doesn’t have to login again – they can now see all pages of the application that I want them to see. This used to work fine.
Recently I noticed that sometimes I’d Login with my username and password, click on a Tab, and it would ask me to Login again. In these instances, it’d only ask me to Login just the second time – after that, it would be fine. I wrote it off as a random glitch on my home-grown server. It seemed to be random, and after a while I noticed it was happening once every day. I looked all through my application, trying to find any links that didn’t pass the &SESSION. through, but I couldn’t find any such problems. I looked at some other applications on the same server – no problems there, it was just this one application.
Just this morning I went in, and happened to notice something not quite right. Normally, when I go into an application, the URL looks something like this:
http://www.xyz.com/apex/f?p=100:1:318727495645403::NO
The site should generate the long numeric Session ID automatically. However, I noticed my URL looked like this:
http://www.xyz.com/apex/f?p=100:1:0::NO
The Session ID was zero. This is a relatively new feature of APEX which I use for my fully-public applications (i.e. ones which require no authentication), where no Session ID is required – it means users can bookmark individual pages without having a long Session ID embedded in the URL.
The cause? When I updated my index page of APEX applications, I copied another entry without thinking, and so included the “0” for the Session ID. So when I first logged in, it gave me a new session, but somewhere internally APEX still had my Session ID = 0, requiring me to Login again. After this, the internal reference to my session was updated. I don’t know if this is expected behaviour or a bug in APEX.
The fix? Remove the 0 from the initial link (e.g. now it looks like “http://www.xyz.com/apex/f?p=100:1”) – zero session IDs are only appropriate for applications that require no login at all anyway.
I used to assume that whenever a TOO_MANY_ROWS exception is raised, the target bind variables would be left untouched. Until today I’ve never written any code that relies on the bind variables being in any particular state when a TMR exception is raised, so was surprised.
For example, given the code below, I would expect the dbms_output to indicate that v is null:
CREATE PROCEDURE proc (v OUT NUMBER) IS
BEGIN
SELECT 1 INTO v FROM all_objects;
EXCEPTION
WHEN TOO_MANY_ROWS THEN
dbms_output.put_line
('TOO MANY ROWS: v='
|| v);
END
/
DECLARE
v NUMBER;
BEGIN
proc(v);
dbms_output.put_line('AFTER: v=' || v);
END
/
TOO MANY ROWS: v=1
AFTER: v=1
What appears to happen is that the out bind variables will be assigned values from the first row returned from the query; then when a second row is found, the TOO_MANY_ROWS exception is raised.
According to the documentation (emphasis added):
“By default, a SELECT INTO statement must return only one row. Otherwise, PL/SQL raises the predefined exception TOO_MANY_ROWS and the values of the variables in the INTO clause are undefined. Make sure your WHERE clause is specific enough to only match one row.”
(Oracle Database PL/SQL User’s Guide and Reference (10gR2): SELECT INTO Statement)
So it appears my original stance (don’t assume anything about the variables’ state after TOO_MANY_ROWS is raised) was correct. Lesson learned: beware of performing a SELECT INTO directly on the OUT parameters of your procedure!
Jeffrey Kemp
10 March 2008
PL/SQL /
A tester for our client raised a problem where searches like ‘ABC%’ would perform satisfactorily, but searches like ‘%ABC’ would time out. Of course, the reason is that the index on the column cannot be used if a wildcard is at the start of the string, so a full table scan is always performed.
I think we’re going to accept the slow response for now, but a possible solution that we might consider in future is to use a function-based index on the REVERSE() function. Its drawback is that it requires modifying the code.
First, some test data:
CREATE TABLE jka AS
SELECT ROWNUM id, dbms_random.string('x',10) v
FROM dual CONNECT BY LEVEL <= 10000;
Now, create an ordinary index:
CREATE INDEX jka_normal ON jka (v);
BEGIN
dbms_stats.gather_table_stats
(USER
,'JKA'
,estimate_percent=>100
,cascade=>TRUE);
END;
This query can use a range scan on jka_normal:
SELECT * FROM jka WHERE v LIKE 'ABC%';
But this query will use a full table scan (can’t use the index):
SELECT * FROM jka WHERE v LIKE '%ABC';
Now, create a function-based index (not to be confused with a REVERSE INDEX):
CREATE INDEX jka_reverse ON jka(REVERSE(v));
BEGIN
dbms_stats.gather_table_stats
(USER
,'JKA'
,estimate_percent=>100
,cascade=>TRUE);
END;
This query can use a range scan on jka_reverse:
SELECT * FROM jka WHERE REVERSE(v) LIKE REVERSE('%ABC');
Edit: looks like Richard Foote beat me to it, in a discussion of reverse indexes (which unfortunately don’t contribute anything useful to this particular problem) – I did a quick search on Google without results, but Foote’s article must not have been indexed yet or too far down the list.
It was mentioned at the AUSOUG conference by one of the speakers that he couldn’t get the database to use a function-based index based on the regexp functions. I thought this was a little strange so decided to try for myself.
SQL> select * from v$version;
Oracle Database 10g Express Edition Release 10.2.0.1.0
Create a test table and gather stats on it:
SQL> create table testtable as
select rownum rn,
dbms_random.string(‘a’,10) string10,
rpad(‘x’,2000,’x’) padding
from all_objects
where rownum <= 5000;
SQL> exec dbms_stats.gather_table_stats(user,
‘TESTTABLE’, cascade=>TRUE);
This is our test query using regexp_instr:
SQL> explain plan for
select string10, regexp_instr(string10, ‘XE’)
from testtable
where regexp_instr(string10, ‘XE’) > 0;
Id | Operation | Name | Rows | Bytes | Cost
0 | SELECT STATEMENT | | 243 | 475K| 465
* 1 | TABLE ACCESS FULL| TESTTABLE | 243 | 475K| 465
1 – filter( REGEXP_INSTR (“STRING10”,’XE’)>0)
– dynamic sampling used for this statement
How many rows are actually returned by this query?
SQL> select string10, regexp_instr(string10, ‘XE’)
from testtable
where regexp_instr(string10, ‘XE’) > 0;
STRING10 REGEXP_INSTR(STRING10,’XE’)
———- —————————
fwXEKwoDhG 3
rSmdOXEkeu 6
WXEbrrjXcW 2
qWEThNXEBO 7
XEQtOwjOCW 1
MRXEoAicUQ 3
IpECtZbjXE 9
LdmXjyePXE 9
gXEaiGrjSX 2
PoqtvdGcXE 9
ZunAgePXXE 9
evXEFhBpzX 3
ZxkXstXEwJ 7
yVpjHzXECY 7
FkaPMpXEgR 7
RuXUnXEQSO 6
OooRCjXXEK 8
XzceiWPXEr 8
XEZlpdNMhG 1
jJjzfXEdDw 6
CowyXEuHDm 5
21 rows selected
Hmmm… there should be a better way.
Let’s try a simple function-based index to speed things up:
SQL> create index idx_regexp on testtable
(regexp_instr(string10, ‘XE’));
Will this query use the index?
SQL> explain plan for
select string10, regexp_instr(string10, ‘XE’)
from testtable
where regexp_instr(string10, ‘XE’) > 0;
Id | Operation | Name | Rows | Bytes | Cost
0 | SELECT STATEMENT | | 4444 | 48884 | 465
* 1 | TABLE ACCESS FULL| TESTTABLE | 4444 | 48884 | 465
1 – filter( REGEXP_INSTR (“STRING10”,’XE’)>0)
Why not? The calculated cost with the index was higher than with a full table scan.
SQL> explain plan for
select /*+ index(testtable idx_regexp) */ string10, regexp_instr(string10, ‘XE’)
from testtable
where regexp_instr(string10, ‘XE’) > 0;
Id | Operation | Name | Rows | Bytes | Cost
0 | SELECT STATEMENT | | 4444 | 48884 | 1512
1 | TABLE ACCESS BY INDEX ROWID| TESTTABLE | 4444 | 48884 | 1512
* 2 | INDEX RANGE SCAN | IDX_REGEXP | 4444 | | 10
2 – access( REGEXP_INSTR (“STRING10”,’XE’)>0)
Why was the cost higher? Let’s look at what would be in that index…
SQL> select regexp_instr(string10, ‘XE’) from testtable;
REGEXP_INSTR(STRING10,’XE’)
—————————
0
0
0
0
0
1
0
0
0
0
… (lots of zeroes and the occasional positive integer) …
0
0
0
5000 rows selected
The index has a row for each block in the table. No histogram on it, so it doesn’t know that most of the index is zeroes.
What if we just want stuff from the index?
SQL> explain plan for
select regexp_instr(string10, ‘XE’)
from testtable
where regexp_instr(string10, ‘XE’) > 0;
Id | Operation | Name | Rows | Bytes | Cost
0 | SELECT STATEMENT | | 4444 | 48884 | 4
* 1 | INDEX FAST FULL SCAN| IDX_REGEXP | 4444 | 48884 | 4
1 – filter( REGEXP_INSTR (“STRING10”,’XE’)>0)
Yes, that uses the index. So how do we get the rest of the data from the table? Let’s try something else.
SQL> drop index idx_regexp;
We can take advantage of the fact that NULLS are not stored in an index by converting any zeroes (i.e. the regular expression didn’t match) to NULL:
SQL> create index idx_regexp_better on testtable
(CASE WHEN regexp_instr(string10, ‘XE’) > 0
THEN regexp_instr(string10, ‘XE’)
ELSE NULL END);
SQL> exec dbms_stats.gather_table_stats(user, ‘TESTTABLE’, cascade=>TRUE);
Will our query use the new improved index?
SQL> explain plan for
select string10, regexp_instr(string10, ‘XE’)
from testtable
where regexp_instr(string10, ‘XE’) > 0;
Id | Operation | Name | Rows | Bytes | Cost
0 | SELECT STATEMENT | | 250 | 2750 | 465
* 1 | TABLE ACCESS FULL| TESTTABLE | 250 | 2750 | 465
1 – filter( REGEXP_INSTR (“STRING10”,’XE’)>0)
No. Why? Because it can’t use the index, even if we try to force it with a hint. The optimiser doesn’t know it can modify my expression into the one that was used to build the index.
SQL> explain plan for
select /*+ index(testtable idx_regexp_better)*/
string10, regexp_instr(string10, ‘XE’)
from testtable
where regexp_instr(string10, ‘XE’) > 0;
Id | Operation | Name | Rows | Bytes | Cost
0 | SELECT STATEMENT | | 250 | 2750 | 465
* 1 | TABLE ACCESS FULL| TESTTABLE | 250 | 2750 | 465
1 – filter( REGEXP_INSTR (“STRING10”,’XE’)>0)
What if we copy the expression from the index into the query? Yes, that’s better.
SQL> explain plan for
select string10, regexp_instr(string10, ‘XE’)
from testtable
where CASE WHEN regexp_instr(string10, ‘XE’) > 0
THEN regexp_instr(string10, ‘XE’)
ELSE NULL END > 0;
Id | Operation | Name | Rows | Bytes | Cost
0 | SELECT STATEMENT | | 21 | 231 | 22
1 | TABLE ACCESS BY INDEX ROWID| TESTTABLE | 21 | 231 | 22
* 2 | INDEX RANGE SCAN | IDX_REGEXP_BETTER | 21 | | 1
2 – access(CASE WHEN REGEXP_INSTR (“STRING10”,’XE’)>0 THEN REGEXP_INSTR(“STRING10”,’XE’) ELSE NULL END >0)
Brilliant!
This query crashes the session when it’s run or parsed.
I haven’t checked if this appears in other versions or not.
SQL> conn scott/tiger@orcl
Connected.
SQL> select * from v$version;
Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 – 64bi
PL/SQL Release 10.2.0.3.0 – Production
CORE 10.2.0.3.0 Production
TNS for Solaris: Version 10.2.0.3.0 – Production
NLSRTL Version 10.2.0.3.0 – Production
SQL> explain plan for with q as
2 (select ‘x’ d from dual
3 union all
4 select ‘y’ from dual)
5 select d from q
6 union all
7 select d from q
8 order by dbms_random.value;
explain plan for with q as (select ‘x’ d from dual
*
ERROR at line 1:
ORA-03113: end-of-file on communication channel
The crashes happened when I added the “order by dbms_random.value”. The problem seems to be in the optimiser since I get the same results whether I run the query or just explain it. Possibly something to do with the optimiser wrongly assuming the random function is deterministic?
There’s a simple workaround, so I’m not too worried. I just change it to this and it works fine:
with q as
(select ‘x’ d from dual
union all
select ‘y’ from dual)
select d, dbms_random.value o from q
union all
select d, dbms_random.value o from q
order by o;
Jeffrey Kemp
22 November 2007
bug / SQL /
This is a followup on my earlier series on setting up APEX on Linux. In it I described how I used Apache web server in front of APEX, instead of accessing APEX directly via OWA (this was so that I could use the same port to serve ordinary web pages and files via HTTP).
A consequence of that set up is that all my APEX pages are a little slow to load up because none of the images are being cached on the client. To solve this I added the following lines to my httpd.conf:
<LocationMatch /i>
ExpiresActive on
ExpiresDefault "access plus 1 month"
</LocationMatch>
<LocationMatch /apex>
ExpiresActive on
ExpiresDefault "access"
ExpiresByType image/gif "access plus 1 month"
ExpiresByType image/jpeg "access plus 1 month"
ExpiresByType image/bmp "access plus 1 month"
</LocationMatch>
My location “/i” points to the images used by APEX. Since there are only images in there I’ve told it to expire everything (ExpiresDefault) after a month.
The location “/apex” is for the actual APEX pages, including APEX application images which are not in /i/. I’ve set the default to “access” (in other words, don’t cache them), but added exceptions for the various image types in use to cache for a month.
[Previous]
I’ve got my Linux server running now, and I can access it from anywhere on the Internet. I can even do application development remotely in Apex, which is fun to show off.
Now, I have a number of small APEX applications (mainly personal use) which are running on my Windows PC, and I want to transfer them all to Linux. The steps I take are as follows:
- Backup
- Export the applications
- Export the data
- Export the workspaces
- Set up tablespaces
- Import the workspaces
- Import the data
- Import the applications
- Test
- Backup
Instead of trying to just copy everything across in one big bang, I wanted to selectively move certain applications and data across, with a few changes along the way. For example, one application was storing a lot of images in BLOBs in a table, but in the new database these are going to be stored on the filesystem to save space in the database. So I’ll only export the data for the other tables, not including the BLOBs (if needed I could export the data to files on the filesystem, but as it happens I have already been keeping copies of all these images on the filesystem anyway, so it’ll be a simple matter to transfer them across). Another change is that one workspace uses a schema name which I’d like to change in the new database.
In detail:
1. Backup
The docs always say “take a backup” before you do anything. On this occasion I decide to actually do this for once. So I do a complete export of the database on the Linux PC.
While that’s running, I switch over to the Windows box and:
2. Export the applications
I’ve only got half a dozen applications I want to transfer across, so it’s not too big a deal to log into each workspace, select an application, click Export/Import, choose Export, and click Export Application.
3. Export the data
I’ve only got a small amount of data and with one exception I just want to get exports of all objects for the various schemas used by the workspaces, so I use the exp utility, one at a time for each schema. The one exception is the schema with the BLOBs – in that case, I choose the mode that allows me to select individual objects to export. Not too hard, as long as I don’t have to do it every day!
The docs all say to use the new Data Pump feature. So “do as I say, not as I do”…
4. Export the workspaces
This is a very useful feature of Apex – it takes care of creating workspaces, schemas and users along with their privileges. To do this, I log into the APEX Administration function (e.g. via the INTERNAL workspace), select Manage Workspaces, and click Export Workspace. Select each workspace in turn and click Export Workspace. Choose UNIX for the file format and click Save File.
Ok, I’ve got all the files I need. I put them on a transfer disk (I’ve got a share on the Windows PC) and switch back to Linux. The backup I started earlier has finished, so now I can start importing it all.
5. Set up tablespaces
I decided to set up my tablespaces manually, so I can specify the file sizes and everything to my exact requirements. E.G.:
CREATE TABLESPACE FLOW_1DATAFILE '/usr/lib/oracle/xe/oradata/XE/FLOW_1.dbf'SIZE 5M NEXT 1M MAXSIZE 100M;
6. Import the workspaces
What could be simpler? APEX Admin, Manage Workspaces, Import Workspace, pick the workspace export file created in step 4, and click Install. I choose the option to create new schemas. In one case I change the schema name (mentioned above).
7. Import the data
Simple matter of running the imp command in a Linux command window. I got quite a few compilation errors due to dependencies between schemas (including some schemas that I’d decided not to import), but once they’re resolved it’s all good.
8. Import the applications
Log into each workspace and click Application Builder, Import. Choose the application exported in step 2 above. Click Next and I’m done!
9. Test
I use all my test cases that I’ve prepared thoroughly beforehand (not!)… ha. Well, in fact I just opened each application and checked a few pages here and there. A few bits and bobs not working but soon sorted out.
10. Backup
I take another backup to lock down everything in a known working state, and it’s all done!
I’m sure there’s two dozen other ways I could have done all this, some of which perhaps easier, more efficient or just more exciting. Certainly I wouldn’t advocate all these steps for a large installation. It’ll depend on your requirements. Another approach would have been to do a complete export of Oracle and import the whole thing.
Please add any comments to any of the posts in this series about your experiences in these areas, as others have done already. We can all learn from each other, and that’s what I love about blogging. Thanks!
Thanks for reading – I hope you’ve enjoyed this little series on “Dirt Cheap Oracle”. I hope I’ve demonstrated that it is possible, and relatively easy, to obtain and set up a cheap Linux box, and add to your APEX/Oracle experience skills in web server configuration and home networking, all for free.
I can see this kind of setup being really useful for small non-profit organisations like community groups, charities, and religious organisations. Get out there and give it a go!
[Previous]
The link here is to a diagram that illustrates what I talked about in recent posts, how to set up a Dynamic DNS service and how the various IP addresses and ports relate to your router and devices connected to it.
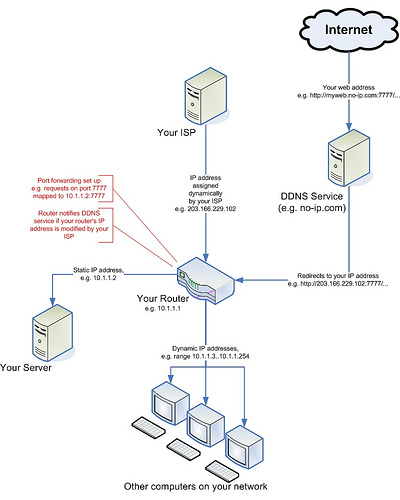
[Next]
[Previous]
I want people to get to both my Apache web server (port 8000) as well as Apex (port 8080) via the default HTTP port (80) through the router, but you can’t map one port to two ports – otherwise, how is the router to know which port to pass requests on to? There’s a good reason why I’ve chosen the web server to get all the traffic, and that’s because I have an idea how to get Apache to pass traffic to APEX, but not how the other way around could be done (EPG pass traffic to Apache).
This was a bit of a conundrum, and I was forced to do some spelunking in the documentation for Apache web server configuration. Reading these docs is highly recommended, it’s a lot of fun although at first it’s hard to know where to start. I’d recommend starting with the sections on Configuration Files and Configuration Sections, with a bit of browsing through the various commands, and then maybe the URL Rewriting Guide.
It wasn’t pretty; in the end it came down to one of two options:
(a) Redirect
(b) Rewrite
I can’t use redirection because whenever someone goes to my web page, redirection means Apache will send back a message saying “wrong address, please try this new address” which would include port 8080, which for at least one friend of mine would be blocked.
So I tried URL rewriting, adding the following lines into my /etc/httpd/conf/httpd.conf:
<Location /apex>
RewriteEngine On
RewriteRule (.*) http://%{SERVER_NAME}:8080%{REQUEST_URI} [last]
Order deny,allow
Deny from none
Allow from all
</Location>
(BTW if you’re wondering, the third line starting with “RewriteRule” is one long line, “{REQUEST_URI}…” should appear directly after “…8080%” without any line break)
This means: for any URL requesting /apex or anything under that folder, rewrite the request to go to the same server and address, but on port 8080.
This would have worked, except that according to the documentation, if the rewrite engine changes the host or port of the url, it will actually do a Redirect! So rewriting is no better than redirection for this case.
In the end, I found a third option:
(c) ProxyPass
I added the following lines into httpd.conf:
ProxyRequests Off
ProxyPass /apex http://localhost:8080/apex
ProxyPassReverse / http://localhost:8080
ProxyReceiveBufferSize 49152
(the above assumes that localhost is mapped in my hosts file)
This solved the problem for me. What the lines above mean is, any request for /apex or anything underneath it is internally passed on to http://localhost:8080/apex which will act like a proxy server for the request. This operation is transparent to the client, which doesn’t know that anything’s changed. I believe ProxyPassReverse is also needed so that requests going back from port 8080 is routed in the reverse direction; not entirely sure how that works but at least it works.
Now, that works, but when I access APEX pages via port 8000 (80 from the outside), I get all the text but no images. That’s because APEX was serving images via /i/ on port 8080 (via EPG), but now we have this proxy thing only passing requests for /apex/* to it, and Apache web server can’t find /i/.
At first I tried adding another ProxyPass line for /i to port 8080, and this did work; however, all the pages loaded very slowly, all the images were visibly taking time to load each time a page was refreshed, so no images were being cached. I figured this lack of caching was because Apache can’t tell that an image hasn’t been changed since the last time it was requested.
This performance problem was solved by getting all the Apex images and putting them on another folder on the Linux box (e.g. /usr/lib/oracle/apex/images) and adding the following line to httpd.conf:
Alias /i/ "/usr/lib/oracle/apex/images/"
This means that all the APEX images are now served by Apache web server instead of by Apex. It also means that application images I’ve loaded have to be copied out to the file system, but in my case there weren’t many and it didn’t take long.
It’s all very simple, isn’t it? Not. But at least it works, and reasonably well. My friends and family are suitably impressed, although they have no inkling of the trouble I went to to get it all working. Ah, the thankless life of an Oracle programmer – but it’s all worth it in the end when I can do full-on development remotely, wherever in the world I happen to be (e.g. down the road at a friend’s place).
Next problem: world peace. Or, migrating my existing APEX applications from the XP box to Linux. Depending on how much time I have.
[Next]
[Previous]
Disclaimer: don’t blame me if you follow any of the instructions here and get yourself into a right mess – think of me as a helpful but aloof guide who occasionally gets his words mixed up 🙂
I can access Apex from the Linux box, but not from my WinXP machine across the network. This is because the firewall in Linux by default blocks most ports. I’ve got APEX (using EPG) listening on port 8080, and Apache web server (for the static web pages and images) listening on port 8000, so I open up those two ports (System menu -> Administration -> Security Level & Firewall).
The router, by default, assigns IP addresses dynamically via DHCP to each device that connects to it; in order that I don’t have to keep logging into the router to see what today’s IP address is, I need to tell the router to reserve an IP address for the Linux box. To do that I log into the router’s administration page (for mine it’s http://10.1.1.1), and examine the DHCP settings page. There I find that two devices are connected, each with a unique MAC address, and with the IP address currently assigned to them. One is the WinXP machine, the other is the Linux box. I happen to know which one is which, but I suppose if I didn’t know I could have just disconnected one of them and seen which one disappeared from the router. Anyway, I copy the MAC address and tell the router to assign it a static IP address (in my case, 10.1.1.3) (a word of advice: on some routers you have to also change the settings that specify the range of dynamic IP addresses that can be assigned by DHCP, so that they don’t conflict with the static IP addresses; in my case, my router does not work that way).
By the way, if my explanation of this doesn’t help you, just google “static IP address” – you’ll find heaps of guides around – keep reading, and it’ll all make sense…
Now I can access it from WinXP via http://10.1.1.3. For convenience I add a line like the following to C:\windows\system32\drivers\etc\hosts:
10.1.1.3 linuxpc linuxpc
This means I can access it via http://linuxpc, at least from WinXP. The equivalent file on linux, used in exactly the same way, is /etc/hosts [Wikipedia: Hosts file].
What I want now is for friends and family to get to it from the outside. For security reasons there’s a number of things blocking that access which I need to take care of. Also, I want the URL that I give out to be relatively simple; a longish URL with strange numbers and characters can be intimidating and easy to get wrong. Also, at least one of my friends works at a place that seems to block different ports (e.g. 8000). So I want them to get in on port 80, which is the default for HTTP and doesn’t need to be specified in their browser.
At the moment the router ignores mosts requests from the outside world; it only exists to serve the little network connected locally to it and couldn’t care less about my friends and family. I need to make it just a little more friendly. First thing, I need to get a port mapped. In my router admin I navigate to the Port Forwarding (called “Virtual Server” on my router; on your router it might appear in “Network Address Translation (NAT/NAPT/PAT)” or “DMZ host”) section, and select the LAN IP I wish to map the port to (in my case, 10.1.1.3). This router gives me a whole lot of preset ports for various games and applications, but I want to do something different, so I select “User” and click “Add”. Here is where I can create a Rule for mapping ports. I want the router to accept TCP traffic on port 80 (the default for web stuff) but send it to port 8000 on the Linux box. So I give it a name (e.g. something imaginative like “Port80to8000”), select TCP for the Protocol, put in 80 for both Port Start and Port End, and pop in 8000 for the Port Map. I don’t need a range so Port Map End stays blank, and click Apply. Now, I just Add my new rule (Port80to8000) to the list of rules for 10.1.1.3, click Apply, and reboot the router. Now, traffic coming in from the outside on port 80 should be sent to port 8000 on the Linux box.
We’re not out of the woods yet, though, there’s a few more things blocking external access. Firstly, iiNet by default block any incoming traffic on port 80, as well as a few other ports, which is good from a security point of view, but doesn’t help me much, so I go into my account management page and switch this option off.
(Once that’s all done, I can test that external access to the port is working, by logging into the machine I want to test, and plugging 80 into this online tool: CanYouSeeMe.org – Open Port Check Tool.)
Finally, and this is the biggy, to get to my site from the outside, people need a URL; or at least, an IP address they can use (that won’t change from day to day). Now, I don’t have a domain name, nor do I have a static IP address – all I get is a dynamic (i.e. can change without notice) IP address assigned by iiNet. I could upgrade to a business broadband account with a static IP address along with a nice domain name, but I want to do this on the cheap, so I don’t.
Instead, I use DDNS (Dynamic DNS). I learned about this from an excellent article by Nathan Taylor in PC User magazine (May 2007). There’s a few sites out there that do this, the one I use is www.no-ip.com which provides a basic service for free. I sign up, get a domain name of my own (I won’t tell you what it is but it looks like mycomputer.no-ip.info), and plug in the settings into the DDNS page on my router.
The way this works is: whenever someone types in my domain name (e.g. http://mycomputer.no-ip.info) into their web browser, the request goes to no-ip.com. Their computer looks up their database for the current IP address for “mycomputer.no-ip.info”, and then forwards the request on to it. This process is pretty much seamless and without any overhead that I’ve noticed. Whenever iiNet change my IP address, my router sends a message back to no-ip.com with the new IP address and their database is updated so that future requests are passed on correctly.
If your router doesn’t support DDNS, don’t worry – you can get software that will run on a computer on your network, and it will do the same job – whenever the IP address changes, it will notify no-ip.com of the change.
After all that fun, I tried to test it from my WinXP box, but I just couldn’t get it to work. As it turns out, you just can’t access the local network using the external address from within that network – apart from using www.canyouseeme.org to check the port, you have to test your web site from outside your network. So I used my “phone a friend” lifeline and got him to try it out.
You guessed it, it worked first time. Ha! Well,… if I said that I’d be lying. It didn’t work first time, the actual process of working all of the above out was a little bit more bumpy than I’ve made out; but in the end it was all working, and I learned a great deal in the process.
There’s one more thing (oh no, I hear you moan…). You’ll notice I’ve only mapped port 80 to port 8000, which is the Apache web server, and not port 8080, which is APEX. That’s the subject of tomorrow’s post, so stay tuned!
[Next]
