If you are using the APEX built-in Data Loading feature to allow your users to upload CSV files, you may have encountered this error.
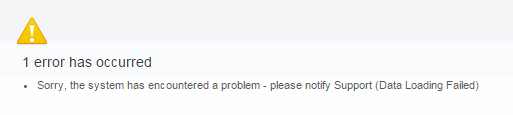
(Note: the error may appear differently in your application as I have built a custom error handling function)
It’s not a particularly useful message, and the logs don’t seem to shed much light on the problem either – reporting only the following:
DATA_LOAD - Final collection is created
...Execute Statement: select 1 from "DEMO"."MY_TABLE" where "RECORD_ID" = :uk_1
Add error onto error stack
...Error data:
......message: Data Loading Failed
......additional_info: ORA-01403: no data found
...
......ora_sqlerrm: ORA-01403: no data found
......error_backtrace:
ORA-06512: at "APEX_040200.WWV_FLOW_DATA_UPLOAD", line 4115
ORA-06512: at "APEX_040200.WWV_FLOW_PROCESS_NATIVE", line 213
ORA-06512: at "APEX_040200.WWV_FLOW_PROCESS_NATIVE", line 262
ORA-06512: at "APEX_040200.WWV_FLOW_PLUGIN", line 1808
ORA-06512: at "APEX_040200.WWV_FLOW_PROCESS", line 453
After trial and error I tracked down one potential cause of this error so I thought I’d share it in case it happens again. I’ll probably come across this again later and forget what the solution was and find this article.
In my case (APEX 4.2.4), the problem was caused by an invalid entry in the Column Name Aliases list of values. I was using a custom List of Values so that alternative names for the columns would be automatically mapped without the user having to select them every time. To do this, I had to edit the List of Values directly to add the alternative names; but I had mistyped one of the Return Values which must map to a real column name on the target table. Whenever I picked this column for an import, I’d get the “Data Loading Failed” error message. Correcting the return value resolved the issue.
In order to stop this happening again, I added the following check to my Apex QA script (this is run whenever the application is deployed):
PROMPT Invalid dataload column mappings (expected: none)
SELECT REPLACE(lt.owner,'#OWNER#',USER) AS owner
,lt.table_name
,le.return_value AS target_column_not_found
,le.list_of_values_name
,le.display_value AS col_alias
,lt.application_id
,lt.application_name
,lt.name AS dataload_definition
FROM apex_appl_load_tables lt
JOIN apex_application_lov_entries le
ON le.lov_id = lt.column_names_lov_id
WHERE NOT EXISTS (
SELECT NULL
FROM all_tab_columns tc
WHERE tc.owner = REPLACE(lt.owner,'#OWNER#',USER)
AND tc.table_name = lt.table_name
AND tc.column_name = le.return_value)
ORDER BY lt.name, le.display_sequence;
If the above query returns any rows, it’ll be a problem.
I’m a morning person, and my mind is usually sharpest on Monday or Tuesday mornings, so these are the best times for me to work on fiddly javascript stuff. Today was one of those mornings and here are the results, just in case I want to refer back to them later on.
I had many items dotted around an Apex application where the user is allowed to enter “Codes” – values that must be uppercase and contain no spaces or other punctuation characters – except underscores (_) were allowed.
To make things easier for the user, I wanted the page to automatically strip these characters out when they exit the field, instead of just giving validation errors (Note: I still included the validations, but the javascript just makes the process a bit smoother for the user doing the data entry).
My APEX application already has a global .js file that is loaded with each page, so all I had to do was add the following code to it:
function cleanCode (c) {
return c.replace(/[^A-Za-z0-9_]/g,"");
}
$(document).ready(function() {
//automatically remove non-code characters from
//"edit_code" class
$( document ).on('change', '.edit_code', function(){
var i = "#"+$(this).attr("id");
$(i).val( cleanCode($(i).val()) );
});
});
EDIT: greatly simplified regexp based on the excellent contribution by Jacopo 🙂
EDIT #2: corrected, thanks to Sentinel
Finally, on each “Code” page item, I set the following attribute (or append, if other classes have already been added):
HTML Form Element CSS Classes = edit_code
For code items within a tabular form, I set the following column attribute:
Element CSS Classes = edit_code
The UAT environment is a runtime APEX installation (4.2.4.00.08) and all deployments are done via SQL scripts. My application uses a small number of static files that for convenience we are serving from APEX (at least for now); to deploy changes to these static files, I export f100.sql and static_files.sql from APEX in dev and we run them in the target environment after setting a few variables, like this:
declare
v_workspace CONSTANT VARCHAR2(100) := 'MYWORKSPACE';
v_workspace_id NUMBER;
begin
select workspace_id into v_workspace_id
from apex_workspaces where workspace = v_workspace;
apex_application_install.set_workspace_id (v_workspace_id);
apex_util.set_security_group_id
(p_security_group_id => apex_application_install.get_workspace_id);
apex_application_install.set_schema('MYSCHEMA');
apex_application_install.set_application_id(100);
end;
/
@f100.sql
@static_file.sql
Many months after this application went live, and after multiple deployments in all the environments, we suddenly had an issue where the static files being served from one instance (UAT) were an older version. The logs showed the correct files had been deployed, and re-deploying into DEV seemed to work fine. I got the DBA to temporarily change the schema password in UAT so I could login to see what was going on.
When I ran this query in DEV, I got the expected two records:
select * from apex_workspace_files
where file_name in ('myapp.css', 'myapp.js');
When I ran it in UAT, I got four records – two copies of each file, and the BLOB contents showed that the older copies were the ones being served to the clients. I have no idea how the extra copies got created in that environment. It must have been due to a failed deployment but the deployment logs didn’t seem to show any errors or anomalies.
Killing the Zombie Static File
I tried editing the static_file.sql script to remove the files (as below), but it only ever removed the new files that were created; re-running it never causes it to drop the old file copies.
...
declare
l_name varchar2(255);
begin
l_name := 'myapp.css';
wwv_flow_html_api.remove_html(
p_html_name => l_name,
p_flow_id => nvl(wwv_flow.g_flow_id, 0) );
end;
/
...
Next thing I tried was something I picked up from here:
NOTE: run this at your own risk! It is not supported by Oracle.
declare
v_workspace CONSTANT VARCHAR2(100) := 'MYWORKSPACE';
v_workspace_id NUMBER;
begin
*** WARNING: DO NOT RUN THIS UNLESS YOU KNOW WHAT YOU ARE DOING ***
select workspace_id into v_workspace_id
from apex_workspaces where workspace = v_workspace;
apex_application_install.set_workspace_id (v_workspace_id);
apex_util.set_security_group_id
(p_security_group_id => apex_application_install.get_workspace_id);
delete from wwv_flow_files where filename like 'myapp.%';
* commit;
end;
/
That seemed to do the trick. Thankfully this problem only occurred in a test environment – I would be uncomfortable running this in Prod.
If you decide to use an editable tabular form to present a number of records for viewing and/or editing, but you have some users who are only allowed to view the data but not edit it, you’d think you could set the “Readonly” condition on the region; but this condition is only applied to any extra region items you add, not to the editable items within the report itself.
Here’s my tabular form, with the records still editable:
One way to get around this is to have two separate report regions on the page – one is the editable tabular report, the other is an ordinary standard report that doesn’t have any of the edit capabilities – and use conditions to hide one or the other depending on the user’s authorisation.
Another way is to use conditions and jQuery to make all the items in the tabular form readonly:
1. Put a condition on all the buttons (e.g. “Add Row”, “Delete”, “Save”, etc) so they are not shown if the user doesn’t have edit privilege
2. Put the same condition on the Multi-Row processes so that they will not run if the user doesn’t have edit privilege.
3. Set the static ID on the region so jquery can find it:
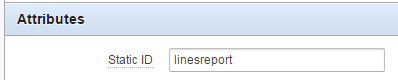
4. Add a Dynamic Action to make all the input items within that region disabled:
Event: Page Load
Authorization Scheme: {Not Editor} (this is just an example where I have an Authorization scheme called “Editor”; alternatively you could set a Condition instead)
True Action: Execute Javascript Code
$("#linesreport input, #linesreport select").prop("disabled",true)
Now, when the page loads, if the user doesn’t have edit privilege the items are rendered readonly, e.g.:
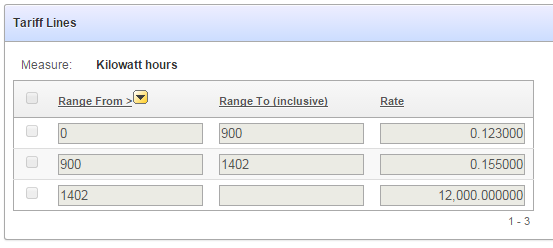
There are other variations on this theme, e.g. we could target the jQuery expression to just the text inputs while still allowing the user to use the checkboxes (e.g. if there was some action that we wanted to allow). Of course, if I wanted to hide the checkboxes completely, I’d just put the authorization on the [row selector] column in the tabular report definition.
The business analyst or QA wants to check all the help texts for all items in your apex application – don’t force them to navigate to each page and click on the labels, one by one; instead, give them a spreadsheet to review at their leisure.
Method 1: use the APEX data dictionary viewer
1. Open your application in the APEX application builder
2. Utilities -> Application Express Views
3. Choose APEX Application Page Items
4. Include PAGE_ID, PAGE_NAME, REGION, ITEM_NAME, LABEL, DISPLAY_AS, ITEM_HELP_TEXT
5. Click Filter >
6. Select APPLICATION_ID = <your app id>
7. Select ITEM_HELP_TEXT IS NOT NULL
8. Click Results >
9. Click Download
Method 2: query the data dictionary directly using your tool of choice
select page_id, page_name, region, item_name, label, display_as, item_help_text
from apex_application_page_items
where application_id = :my_app_id and item_help_text is not null
order by page_id, region, display_sequence;
The APEX application I’m working on has a search filter on a report page that looks like this:

The list of values is based on a user-defined “ref codes” table, which includes an option “Show By Default”. This option is currently set on the “Closed” and “Deleted” status and means that transactions with that status will not normally be listed in the report, unless the user explicitly selects either of those statuses, e.g.:

If no checkboxes are selected, the report shows all transactions by default, except for Closed or Deleted transactions.
To indicate this behaviour, I added an asterisk (*) next to the label on those checkboxes. I also wanted some hover text so that a user who has forgotten what the asterisk means can get an idea, e.g.:
<td>
<input type="checkbox" id="P23_FTS_STATUS_7" name="p_v05" value="CLOSED">
<label for="P23_FTS_STATUS_7" title="* not shown by default">Closed*</label>
</td>

However, the default apex Checkbox item doesn’t support putting extra attributes on the generated html labels – so I need to add the hover text by running some javascript after the page is loaded. jQuery to the rescue!
To add the hover text I simply add this to the Execute when Page Loads page attribute:
$("label[for*='P23_FTS_STATUS']:contains('*')")
.attr("title","* not shown by default")
This searches for all label nodes where the “for” attribute contains my item name (“P23_FTS_STATUS”), where the text contains a “*”. It then adds the “title” attribute with my desired value.
I had a registration form in Apex which asks the applicant to enter their Date of Birth in a date item; I then needed to calculate how old they would be at the start of the event, which determines a number of rules, such as whether we need to obtain their parent’s permission.
In my first release I implemented this with a Dynamic Action which ran SQL something like this:
select round(months_between(start_date
,to_date(:P1_DATE_OF_BIRTH,'DD-MON-YYYY'))
/ 12,1)
from events
where event_id = :P1_EVENT_ID;
This worked fine – it takes advantage of Oracle’s builtin support for date arithmetic. However, it was rather slow, because it needs to do a roundtrip to the database to run the query and return the result.
I wanted a pure javascript implementation to avoid the roundtrip, but my initial searches came up with a number of sub-par solutions involving extracting the year and month portions and applying simple arithmetic which did not take into account leap years.
Instead, I’ve gone with an easier solution taking advantage of the moments javascript package.
- Add the path to moment.min.js in the File URLs attribute of the page. You could get your own local copy or point to the relevant file from a cdn: http://cdnjs.com/libraries/moment.js/
- Add a function to the Function and Global Variable Declaration attribute of the page, which uses the moments object to convert the strings into date objects, and then call the diff method to get the number of years as a floating-point number, e.g.:
function getAge() {
var e = moment($v("P1_EVENT_DATE"),"YYYYMMDD")
,dob = moment($v("P1_DATE_OF_BIRTH"),"DD-MMM-YYYY");
return e.diff(dob,'years',true).toFixed(1);
}
- Add a Dynamic Action to the Date of Birth item which calls getAge() and sets the value of the Age display item.
The result is a much quicker response and less load on the database. This is an intentionally simple example, you could do it in different ways to suit your situation (e.g. if you have multiple date items you need to handle on the same page, you might pass them as parameters to the function).
The moments javascript package has an impressive list of features, including pretty-formatting a duration (e.g. a client-side version of the SINCE format e.g. “3 years ago”) documented here.
If you attended my presentation at AUSOUG Perth earlier this month, or if you’ve had a peek at the slides, you may be interested in a more concrete demonstration of the ideas presented. So if you’d like to install and play with a sample application that includes a TAPI generator, feel free to download this (EDIT: updated, see below).
Disclaimer: this is provided for information (and entertainment) purposes only.
Prerequisites:
Oracle Application Express 4.2.2 or later
Read the README file for installation instructions.
If you’re only interested in the schema-level TAPI and not the APEX application, the zip file includes the DDL script that you can run directly in a schema without requiring Apex.
EDIT (18/11/2014): updated sample code to do the right thing in WHEN OTHERS triggers.
EDIT (20/11/2014): updated sample code with a further example for a FK to a table, which doesn’t use a surrogate key. Also added an exception handler to the Apex application.
EDIT (2/12/2014): added Grid Edit for event types, as an example of how a tabular form might work with a TAPI; added deployment package; moved code to Bitbucket.
EDIT (16/02/2014): upgraded to APEX 5, plus numerous improvements – refer to:
More updates and improvements will be added in the future – watch this space.
APEX’s Blue Responsive Theme 25 is a great theme for building a user-friendly website, and unlike many other themes which make the item labels clickable to get help, it renders little question-mark icons to the right of each item that has a help message defined.
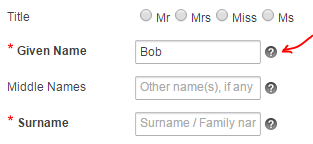
One issue with this design, however, is that a keyboard-savvy user (such as myself) hates to switch between keyboard and mouse – so they Tab between each field as they fill in a form. With this theme, however, those little question-mark icons are in the tab order, so the user has to Tab twice between each field. If they’re not looking at the page they might forget; and if one item doesn’t happen to have a Help icon, they have to remember to only Tab once. All of this adds up to a poor user experience.
To fix this, we simply tell the browser to move the Help icons out of the tab order – and yet again, jQuery comes to the rescue as we can simply pick out all the elements with the class itemHelpButton and set their tabindex to “-1”:
$(".itemHelpButton").attr('tabindex',-1);
Put this code in the page attribute Execute when Page Loads – when the page loads, this will set the tabindex on all the help icons on the page, so now the user can tab through the page without interruption.

What could be simpler than a set of “Next” and “Previous” buttons?
I love Interactive Reports, they make it easy to deliver a lot of power to users for very little development effort. However, with that power comes some complexity for building certain features not available in the base Apex toolset.
I had an IR with a fairly costly and complex query behind it, linked to another screen to view the details for a record. The users wanted to be able to view each record from the search result without having to click each record, go back to the Search, and click the next record, etc. Instead, they wanted “Next” and “Previous” buttons on the Single Record screen which would allow them to navigate the search results.
There are a few ideas on the web around how to implement this, and I considered two of them:
1. On the Single Record screen, run the query to determine what the next and previous records are in relation to the currently viewed record.
2. On the Search screen, instead of querying the tables/views directly, call a database procedure to store the query results in a collection; then, both the Search and the Single Record screens can query the collection.
Some problems with solution #1 include (a) the query might be quite expensive, so the Single Record screen may be too slow; and (b) if the data changes, the user might get unexpected results (“that record didn’t appear in my search results?”).
Another problem that both of these solutions share is that if the user has used any of the IR features such as custom filters, sort orders, etc. we won’t necessarily pick these up when determining what the Next/Previous records are. Certainly, the collection approach won’t pick these up at all.
Instead, I’ve gone for a different approach. Firstly, I’ve simplified the problem by dictating that the Next/Previous buttons will only allow the user to navigate the list of records they most recently saw on the search screen; therefore, if the results are paginated, we’ll only navigate through that page of results. If the user wants to keep going, they’ll go back to the Search screen and bring up the next page of results.
The solution is quite simple in concept but was a bit tricky to implement. The basic idea is that I encode the record IDs in the HTML generated by the report, and use some Dynamic Actions to grab the resulting list of record IDs, store them as a CSV in a page item, which can then be parsed by the View/Edit screen.
Here it is in detail, ready for you to try, critique or improve (in this example, my record’s id column is called ft_id, my Search screen is p23, and the Single Record screen is p26):
Part A: Save the IDs shown on the Interactive Report
1. In the Link Column on the interactive report region, add class="report-ft-id" to the Link Attributes.
2. In the Link Icon, add data-ft-id=#FT_ID# into the img tag.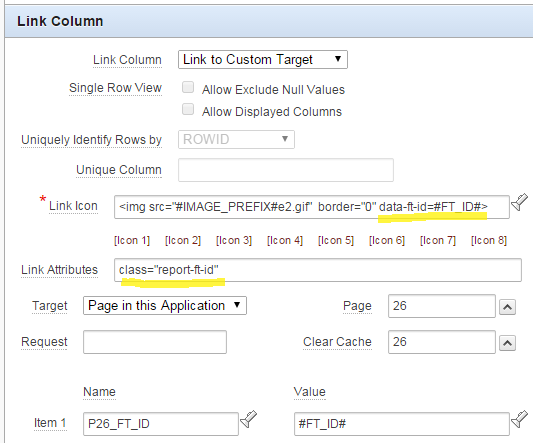
I added this to the img bit because the Link Column field doesn’t do the #FT_ID# substitution, unfortunately.
3. Add the following javascript function to the page’s Function and Global Variable Declaration:
function ft_id_list() {
return $(".report-ft-id >img")
.map(function(){return $(this).attr("data-ft-id");})
.get()
.join(",");
}
This function searches for any records shown on the page by searching for the report-ft-id class, extracts from each one the img node’s data-ft-id attribute, maps these into an array, and then squashes that array down to a comma-separated list.
4. Create a hidden item P23_FT_ID_LIST which will store the resulting list.
5. Create an application item FT_ID_LIST which will be read by the Single Record page.
6. Create a Dynamic Action triggered by the event Page Load, which saves the list of IDs into session state by performing two actions:
(a) Set Value based on a JavaScript Expression, ft_id_list();, assigned to the item P23_FT_ID_LIST
(b) Execute PL/SQL Code which runs the code :FT_ID_LIST := :P23_FT_ID_LIST;. Make sure to set Page Items to Submit to P23_FT_ID_LIST and set Page Items to Return to FT_ID_LIST.
This dynamic action will only fire when the page is initially loaded.
7. Copy the Dynamic Action, but this time set the event to Custom and the Custom Event to apexafterrefresh. This way, whenever the user changes the rows shown in the report (e.g. by paginating, or changing filters or sort order, etc.), the list will be refreshed as well.
Part B: Add the Next/Previous buttons
8. Create some procedures on the database (e.g. in a database package) which take a list of IDs and a “current” ID, and return the next or previous ID in the list:
FUNCTION next_id
(id_list IN VARCHAR2
,curr_id IN VARCHAR2
) RETURN VARCHAR2 IS
buf VARCHAR2(32767) := ','||id_list||',';
search VARCHAR2(100) := ','||curr_id||',';
pos NUMBER;
new_id VARCHAR2(32767);
BEGIN
pos := INSTR(buf, search);
IF pos > 0 THEN
-- strip out the found ID and all previous
buf := SUBSTR(buf, pos+LENGTH(search));
-- chop off the first ID now in the list
IF INSTR(buf,',') > 0 THEN
new_id := SUBSTR(buf, 1, INSTR(buf,',')-1);
END IF;
END IF;
RETURN new_id;
END next_id;
FUNCTION prev_id
(id_list IN VARCHAR2
,curr_id IN VARCHAR2
) RETURN VARCHAR2 IS
buf VARCHAR2(32767) := ','||id_list||',';
search VARCHAR2(100) := ','||curr_id||',';
pos NUMBER;
new_id VARCHAR2(32767);
BEGIN
pos := INSTR(buf, search);
IF pos > 0 THEN
-- strip out the found ID and all following
buf := SUBSTR(buf, 1, pos-1);
-- chop off all but the last ID in the remaining list
IF INSTR(buf,',',-1) > 0 THEN
new_id := SUBSTR(buf, INSTR(buf,',',-1)+1);
END IF;
END IF;
RETURN new_id;
END prev_id;
9. Add two hidden items to the Single Record screen: P26_FT_ID_NEXT and P26_FT_ID_PREV.
10. On P26_FT_ID_NEXT, set Source Type to PL/SQL Expression, and set Source value or expression to next_id(:FT_ID_LIST,:P26_FT_ID), and similarly for P26_FT_ID_PREV to prev_id(:FT_ID_LIST,:P26_FT_ID).
11. Add buttons Next and Previous, with Action set to Redirect to Page in this Application, pointing back to the same page, but setting the P26_FT_ID to &P26_FT_ID_NEXT. and &P26_FT_ID_PREV., respectively.
This method means that it doesn’t matter if the query behind the report changes, or if the user adds filters or uses different saved reports; the Single Record screen doesn’t need to know – it just needs to know what the list of IDs the user most recently saw on the Search screen were.
Some downsides to this approach include:
- Server load – the dynamic actions on the report refresh, which causes it to do an ajax call to the database on every refresh of the IR. But at least it saves the View/Edit screen re-executing the query on every page load.
- Rows Per Page limitation – since we save the list of IDs as a CSV in a single string variable, we may have issues if the user sets Rows Per Page to “All” with a large result set – so we need to limit the Maximum Rows Per Page to about 3,000 (this assumes that all the IDs will be less than 10 digits long) to fit in the 32,767 char limit. YMMV.
- Duplicate records – this method assumes that the IDs shown in the report will always be distinct. If this is not true, the next/previous functions will not allow the user to navigate through the whole list.
