NOTE: update for APEX 5 (see below)
I decided to try using a wrapper procedure to isolate calls to APEX_UTIL.set_session_state in an autonomous transaction. I’m currently using it in a project and seeing how it goes in terms of performance.
DISCLAIMER: Don’t just throw this into your mission-critical system without at least testing it thoroughly first.
Since I had Morten Braten’s Alexandria library handy, I simply modified his APEX_UTIL_PKG. If you’re not using this library you can create your own wrapper quite simply:
create or replace procedure sv
(p_name in varchar2
,p_value in varchar2 := NULL) as
PRAGMA AUTONOMOUS_TRANSACTION;
begin
APEX_UTIL.set_session_state
(p_name => p_name
,p_value => p_value);
COMMIT;
end sv;
Since my system has many schemas (one for each application), I would compile this in a “common” schema and then grant execute on it to the schemas that need it, and create local synonyms in each one so that my applications just need to call sv.
ADDENDUM:
As Joel Kallman rightly points out, putting set_session_state in an autonomous transaction means that the new value will not be visible to the rest of the calling code, so for example the call to v() will not return ‘Joe’ here:
sv('P1_NAME', 'Joe');
x := v('P1_NAME'); -- will not be 'Joe'
Therefore, it is intended that sv() be used as the final step in any procedure, e.g.:
PROCEDURE p1_controller IS
p1_name VARCHAR2(100);
BEGIN
p1_name := v('P1_NAME');
sv('P1_NAME', p1_name);
END;
UPDATE for APEX 5
As of Oracle APEX 5.0, APEX_UTIL.set_session_state supports a new optional parameter, p_commit (documentation). It is defaulted to true which preserves the old behaviour (i.e. it might or might not commit).
If you set p_commit to false, the procedure will not issue any commit. This removes the need for the autonomous transaction, and leaves the responsibility for committing to the developer; if it’s called from an APEX page process, it will be committed automatically.
Updated for APEX 5 – refer below
When should you commit or rollback a transaction? As late as possible, I would have thought, based on most of the advice in the Oracle world. You certainly want this to be predictable and consistent, at least.
Unfortunately, if you use APEX_UTIL.set_session_state in your PL/SQL process, the result is not so predictable.
Thanks to Martin D’Souza who alerted me to this. I love learning new things, but occasionally you get a bad surprise like this and it’s not so pleasant.
Test case set up – create a table with a single row, and create a simple Apex application with one page, with one region, with an item (P1_N) and a Submit button.
CREATE TABLE test (N NUMBER);
INSERT INTO test VALUES (1);
COMMIT;
TEST CASE #1
Add an On Submit process to the page which fires when the Submit button is clicked, which executes the following:
BEGIN
UPDATE test SET n = 3;
COMMIT;
APEX_UTIL.set_session_state('P1_N', 1);
UPDATE test SET n = 2;
APEX_UTIL.set_session_state('P1_N', 1);
ROLLBACK;
END;
What value would you expect to see in the database table now? I would have expected that the table would hold the value 3 – and indeed, it does.
TEST CASE #2
Modify the process slightly – after the second update, set the item to something different:
BEGIN
UPDATE test SET n = 3;
COMMIT;
APEX_UTIL.set_session_state('P1_N', 1);
UPDATE test SET n = 2;
APEX_UTIL.set_session_state('P1_N', 4); --changed here
ROLLBACK;
END;
This time, the second update to the table has been committed before we issued our ROLLBACK. The new value 2 has been saved to the database. Why?
It’s because APEX_UTIL.set_session_state will issue a COMMIT – but only if the value of the item is changed. If you happen to call set_session_state with the value that the item already has, it does nothing, and does not COMMIT. I understand why a COMMIT is ultimately necessary (Apex session state is stored in a table) – but I disagree that it’s necessary for it to commit my (potentially partial) transaction along with it.
This means that if an exception is raised somewhere in my process, the resulting rollback may or may not rollback the entire transaction, depending on whether any prior calls to set_session_state happened to COMMIT or not. This is difficult to predict and therefore makes debugging harder. Not to mention the fact that it violates the general principle of “either the whole transaction succeeds and is COMMITted, or it fails and the whole transaction is rolled back”. I’m sorry, Apex, but you should not arbitrarily commit part of my transaction without at least telling me.
Mitigations for this? I’m not sure yet. One suggestion from this forum thread was to make the procedure use an autonomous transaction. This would align it more closely to what most developers would expect, I think. Unfortunately it appears the suggestion was rejected (or put on hold indefinitely).
I’m planning on refactoring my code to shift all calls to set_session_state to as late in the process as possible; in addition, I’m thinking that I would put an explicit COMMIT prior to these calls so that my code would have more predictable behaviour. But the idea of wrapping set_session_state in a wrapper procedure with an autonomous transaction seems good to try out as well.
UPDATE for APEX 5
As of Oracle APEX 5.0, APEX_UTIL.set_session_state supports a new optional parameter, p_commit (APEX_UTIL documentation). It is defaulted to true which preserves the old behaviour (i.e. it might or might not commit).
If you set p_commit to false, the procedure will not issue any commit. This removes the need for the autonomous transaction, and leaves the responsibility for committing to the developer; if it’s called from an APEX page process, it will be committed automatically.
I recently saw this approach used in a complex Apex application built for my current client, and I liked what I saw – so I used a similar one in another project of mine, with good results.
- Pages load and process faster
- Less PL/SQL compilation at runtime
- Code is more maintainable and reusable
- Database object dependency analysis is much more reliable
- Apex application export files are smaller – faster to deploy
- Apex pages can be copied and adapted (e.g. for different interfaces) easier

How did all this happen? Nothing earth-shattering or terribly original. I made the following simple changes – and they only took about a week for a moderately complex 100-page application (that had been built haphazardly over the period of a few years):
- All PL/SQL Process actions moved to database packages
- Each page only has a single Before Header Process, which calls a procedure (e.g.
CTRL_PKG.p1_load;)
- Each page only has a single Processing Process, which calls a procedure (e.g.
CTRL_PKG.p1_process;)
- Computations are all removed, they are now done in the database package
The only changes I needed to make to the PL/SQL to make it work in a database package were that bind variable references (e.g. :P1_CUSTOMER_NAME) needed to be changed to use the V() (for strings and dates) or NV() (for numbers) functions; and I had to convert the Conditions on the Processes into the equivalent logic in PL/SQL. Generally, I would retrieve the values of page items into a local variable before using it in a query.
My “p1_load” procedure typically looked something like this:
PROCEDURE p1_load IS
BEGIN
msg('p1_load');
member_load;
msg('p1_load Finished');
END p1_load;
My “p1_process” procedure typically looked something like this:
PROCEDURE p1_process IS
request VARCHAR2(100) := APEX_APPLICATION.g_request;
BEGIN
msg('p1_process ' || request);
CASE request
WHEN 'CREATE' THEN
member_insert;
WHEN 'SUBMIT' THEN
member_update;
WHEN 'DELETE' THEN
member_delete;
APEX_UTIL.clear_page_cache
(APEX_APPLICATION.g_flow_step_id);
WHEN 'COPY' THEN
member_update;
-- clear the member ID for a new record
sv('P1_MEMBER_ID');
ELSE
NULL;
END CASE;
msg('p1_process Finished');
END p1_process;
I left Validations and Branches in the application. I will come back to the Validations later – this is made easier in Apex 4.1 which provides an API for error messages.
It wasn’t until I went through this exercise that I realised what a great volume of PL/SQL logic I had in my application – and that PL/SQL was being dynamically compiled every time a page was loaded or processed. Moving it to the database meant that it was compiled once; it meant that I could more easily see duplicated code (and therefore modularise it so that the same routine would now be called from multiple pages). I found a number of places where the Apex application was forced to re-evaluate a condition multiple times (as it had been copied to multiple Processes on the page) – now, all those processes could be put together into one IF .. END IF block.
Once all that code is compiled on the database, I can now make a change to a schema object (e.g. drop a column from a table, or modify a view definition) and see immediately what impact it will have across the application. No more time bombs waiting to go off in the middle of a customer demo. I can also query ALL_DEPENDENCIES to see where an object is being used.
I then wanted to make a Mobile version of a set of seven pages. This was made much easier now – all I had to do was copy the pages, set their interface to Mobile, and then on the database, call the same procedures. Note that when you do a page copy, that Apex automatically updates all references to use the new page ID – e.g. if you copy Page 1 to Page 2, a Process that calls “CTRL_PKG.p1_load;” will be changed to call “CTRL_PKG.p2_load;” in the new page. This required no further work since my p1_load and p1_process procedures merely had a one-line call to another procedure, which used the APEX_APPLICATION.g_flow_step_id global to determine the page number when using page items. For example:
PROCEDURE member_load IS
p VARCHAR2(10) := 'P' || APEX_APPLICATION.g_flow_step_id;
member members%ROWTYPE;
BEGIN
msg('member_load ' || p);
member.member_id := nv(p || '_MEMBER_ID');
msg('member_id=' || member.member_id);
IF member.member_id IS NOT NULL THEN
SELECT *
INTO member_page_load.member
FROM members m
WHERE m.member_id = member_load.member.member_id;
sv(p || '_GIVEN_NAME', member.given_name);
sv(p || '_SURNAME', member.surname);
sv(p || '_SEX', member.sex);
sv(p || '_ADDRESS_LINE', member.address_line);
sv(p || '_STATE', member.state);
sv(p || '_SUBURB', member.suburb);
sv(p || '_POSTCODE', member.postcode);
sv(p || '_HOME_PHONE', member.home_phone);
sv(p || '_MOBILE_PHONE', member.mobile_phone);
sv(p || '_EMAIL_ADDRESS', member.email_address);
sv(p || '_VERSION_ID', member.version_id);
END IF;
msg('member_load Finished');
END member_load;
Aside: Note here the use of SELECT * INTO [rowtype-variable]. This is IMO the one exception to the “never SELECT *” rule of thumb. The compromise here is that the procedure will query the entire record every time, even if it doesn’t use some of the columns; however, this pattern makes the code leaner and more easily understood; also, I usually need almost all the columns anyway.
In my database package, I included the following helper functions at the top, and used them throughout the package:
DATE_FORMAT CONSTANT VARCHAR2(30) := 'DD-Mon-YYYY';
PROCEDURE msg (i_msg IN VARCHAR2) IS
BEGIN
APEX_DEBUG_MESSAGE.LOG_MESSAGE
($$PLSQL_UNIT || ': ' || i_msg);
END msg;
-- get date value
FUNCTION dv
(i_name IN VARCHAR2
,i_fmt IN VARCHAR2 := DATE_FORMAT
) RETURN DATE IS
BEGIN
RETURN TO_DATE(v(i_name), i_fmt);
END dv;
-- set value
PROCEDURE sv
(i_name IN VARCHAR2
,i_value IN VARCHAR2 := NULL
) IS
BEGIN
APEX_UTIL.set_session_state(i_name, i_value);
END sv;
-- set date
PROCEDURE sd
(i_name IN VARCHAR2
,i_value IN DATE := NULL
,i_fmt IN VARCHAR2 := DATE_FORMAT
) IS
BEGIN
APEX_UTIL.set_session_state
(i_name, TO_CHAR(i_value, i_fmt));
END sd;
PROCEDURE success (i_msg IN VARCHAR2) IS
BEGIN
msg('success: ' || i_msg);
IF apex_application.g_print_success_message IS NOT NULL THEN
apex_application.g_print_success_message :=
:= apex_application.g_print_success_message || '<br>';
END IF;
apex_application.g_print_success_message
:= apex_application.g_print_success_message || i_msg;
END success;
Another change I made was to move most of the logic embedded in report queries into views on the database. This led to more efficiencies as logic used in a few pages here and there could now be consolidated in a single view.
The challenges remaining were record view/edit pages generated by the Apex wizard – these used DML processes to load and insert/update/delete records. In most cases these were on simple pages with no other processing added; so I left them alone for now.
On a particularly complex page, I removed the DML processes and replaced them with my own package procedure which did the query, insert, update and delete. This greatly simplified things because I now had better control over exactly how these operations are done. The only downside to this approach is that I lose the built-in Apex lost update protection mechanism, which detects changes to a record done by multiple concurrent sessions. I had to ensure I built that logic into my package myself – I did this with a simple VERSION_ID column on the table (c.f. Version Compare in “Avoiding Lost Updates”).
The only downsides with this approach I’ve noted so far are:
- a little extra work when initially creating a page
- page item references are now strings (e.g. “
v('P1_RECORD_ID')“) instead of bind variables – so a typo here and there can result in somewhat harder-to-find bugs
However, my application is now faster, more efficient, and on the whole easier to debug and maintain – so the benefits seem to outweigh the downsides.

Get it? “an item with many hats”… yeah ok.
Need to change the label of an item on-the-fly? When I run my Apex page it renders item labels like this:
<label for="P1_CONTACT_NUMBER">
<span>Contact Number</span>
</label>
If the label needs to change based on another item, I could set the label with the value of another item, e.g. “&P1_CONTACT_NUMBER_LABEL.” and when the page is refreshed it would pick up the new label. But at runtime, if the label needs to change dynamically in response to changes in other items, we need to do something else.
Caveat: The need for changing the label should be very rare – it’s bad practice to overload one field with multiple meanings. But if you must, this is what you can do.
It’s easy with a Dynamic Action running some Javascript. This changes the label text for the P1_CONTACT_NUMBER item depending on the value chosen for P1_CONTACT_METHOD, which might be a radio group or select list. The method uses jquery to search for a “label” tag with the attribute “for” that associates it with the desired item; we then navigate down to the “span” element, and call the “text” function to change the label text:
if ($v("P1_CONTACT_METHOD")=='SMS') {
$("label[for=P1_CONTACT_NUMBER]>span").text("Contact Mobile")
} else if ($v("P1_CONTACT_METHOD")=='EMAIL') {
$("label[for=P1_CONTACT_NUMBER]>span").text("Contact Email")
} else {
$("label[for=P1_CONTACT_NUMBER]>span").text("Contact Number")
}
The Dynamic Action is set up as follows:
Event = Change
Selection Type = Item(s)
Item(s) = P1_CONTACT_METHOD
Condition = (no condition)
True Action = Execute JavaScript Code
Fire On Page Load = Yes
Selection Type = (blank)
Code = (the javascript shown above)
 My current client has a large number of APEX applications, one of which is a doozy. It is a mission-critical and complex application in APEX 4.0.2 used throughout the business, with an impressively long list of features, with an equally impressively long list of enhancement requests in the queue.
My current client has a large number of APEX applications, one of which is a doozy. It is a mission-critical and complex application in APEX 4.0.2 used throughout the business, with an impressively long list of features, with an equally impressively long list of enhancement requests in the queue.
They always have a number of projects on the go with it, and they wanted us to develop two major revisions to it in parallel. In other words, we’d have v1.0 (so to speak) in Production, which still needed support and urgent defect fixing, v1.1 in Dev1 for project A, and v1.2 in Dev2 for project B. Oh, and we don’t know if Project A will go live before Project B, or vice versa. We have source control, so we should be able to branch the application and have separate teams working on each branch, right?
We said, “no way”. Trying to merge changes from a branch of an APEX app into an existing APEX app is not going to work, practically speaking. The merged script would most likely fail to run at all, or if it somehow magically runs, it’d probably break something.
So we pushed back a bit, and the terms of the project were changed so that development of project A would be done first, and the development of project B would follow straight after. So at least now we know that v1.2 can be built on top of v1.1 with no merge required. However, we still had the problem that production defect fixes would still need to be done on a separate version of the application in dev, and that they needed to continue being deployed to sit/uat/prod without carrying any changes from our projects.
The solution we have used is to have two copies of dev, each with its own schema, APEX application and version control folder: I’ll call them APP and APP2. We took an export of APP and created APP2, and instructed the developer who was tasked with production defect fixes to manually duplicate his changes in both APP and APP2. That way the defect fixes were “merged” in a manual fashion as we went along – also, it meant that the project development would gain the benefit of the defect fixes straight away. The downside was that everything worked and acted as if they were two completely different and separate applications, which made things tricky for integration.
Next, for developing project A and project B, we needed to be able to make changes for both projects in parallel, but we needed to be able to deploy just Project A to SIT/UAT/PROD without carrying the changes from project B with it. The solution was to use APEX’s Build Option feature (which has been around for donkey’s years but I never had a use for it until now), in combination with Conditional Compilation on the database schema.
I created a build option called (e.g.) “Project B”. I set Status = “Include”, and Default on Export = “Exclude”. What this means is that in dev, my Project B changes will be enabled, but when the app is exported for deployment to SIT etc the build option’s status will be set to “Exclude”. In fact, my changes will be included in the export script, but they just won’t be rendered in the target environments.
When we created a new page, region, item, process, condition, or dynamic action for project B, we would mark it with our build option “Project B”. If an existing element was to be removed or replaced by Project B, we would mark it as “{NOT} Project B”.
Any code on the database side that was only for project B would be switched on with conditional compilation, e.g.:
$IF $$projectB $THEN
PROCEDURE my_proc (new_param IN ...) IS...
$ELSE
PROCEDURE my_proc IS...
$END
When the code is compiled, if the projectB flag has been set (e.g. with ALTER SESSION SET PLSQL_CCFLAGS='projectB:TRUE';), the new code will be compiled.
Build Options can be applied to:
- Pages & Regions
- Items & Buttons
- Branches, Computations & Processes
- Lists & List Entries
- LOV Entries
- Navigation Bar & Breadcrumb Entries
- Shortcuts
- Tabs & Parent Tabs
This works quite well for 90% of the changes required. Unfortunately it doesn’t handle the following scenarios:
1. Changed attributes for existing APEX components – e.g. some layout changes that would re-order the items in a form cannot be isolated to a build option.
2. Templates and Authorization Schemes cannot be marked with a build option.
On the database side, it is possible to detect at runtime if a build option has been enabled or not. In our case, a lot of our code was dependent on schema structural changes (e.g. new table columns) which would not compile in the target environments anyway – so conditional compilation was a better solution.
Apart from these caveats, the use of Build Options and Conditional Compilation have made the parallel development of these two projects feasible. Not perfect, mind you – but feasible. The best part? There’s a feature in APEX that allows you to view a list of all the components that have been marked with a Build Option – this is accessible from Shared Components -> Build Options -> Utilization (tab).
Enhancement Requests:
1. If Build Options could be improved to allow the scenarios listed above, I’d be glad. In a perfect world, I should be able to go into APEX, select “Project B”, and all my changes (adding/modifying/removing items, regions, pages, LOVs, auth schemes, etc) would be marked for Project B. I could switch to “Project A”, and my changes for Project B would be hidden. I think this would require the APEX engine to be able to have multiple definitions of each item, region or page, one for each build option. Merging changes between build options would need to be made possible, somehow – I don’t hold any illusions that this would be a simple feature for the APEX team to deliver.
2. Make the items/regions/pages listed in the Utilization tab clickable, so I can easily click through and change properties on them.
3. Another thing I’d like to see from the APEX team is builtin GUI support for exporting applications as a collection of individual scripts, each independently runnable – one for each page and shared component. I’m aware there is a Java tool for this purpose, but the individual scripts it generates cannot be run on their own. For example, if I export a page, I should be able to import that page into another copy of the same application (but with a different application ID) to replace the existing version of that page. I should be able to check in a change to an authorization scheme or an LOV or a template, and deploy just the script for that component to other applications, even in other workspaces. The export feature for all this should be available and supported using a PL/SQL API so that we can automate the whole thing and integrate it with our version control and deployment software.
4. What would be really cool, would be if the export scripts from APEX were structured in such a way that existing source code merge tools could merge different versions of the same APEX script and result in a usable APEX script. This already works quite well for our schema scripts (table scripts, views, packages, etc), so why not?
Further Reading:
An enhancement request I was assigned was worded thus:
“User will optionally enter the Phone number (IF the phone was blank the system will default the store’s area code).”
I interpret this to mean that the Customer Phone number (land line) field should remain optional, but if entered, it should check if the local area code had been entered, and if not, default it according to the local store’s area code. We can assume that the area code has already been entered if the phone number starts with a zero (0).
This is for a retail chain with stores throughout Australia and New Zealand, and the Apex session knows the operator’s store ID. I can look up the country code and phone number for their store with a simple query, which will return values such as (these are just made up examples):
Country AU, Phone: +61 8 9123 4567 – area code should be 08
Country AU, Phone: 08 91234567 – area code should be 08
Country AU, Phone: +61 2 12345678 – area code should be 02
Country AU, Phone: 0408 123 456 – no landline area code
Country NZ, Phone: +64 3 123456 – area code should be 03
Country NZ, Phone: 0423 456 121 – area code should be 04
They only want to default the area code for landlines, so if the store’s phone number happens to be a mobile phone number it should not do any defaulting.
Step 1: create a database function (in a database package, natch) to return the landline area code for any given store ID.
FUNCTION get_store_landline_area_code (p_store_id IN VARCHAR2) RETURN VARCHAR2 IS
v_area_code VARCHAR2(2);
v_country_code stores_vw.country_code%TYPE;
v_telephone_number stores_vw.telephone_number%TYPE;
BEGIN
IF p_store_code IS NOT NULL THEN
BEGIN
SELECT country_code
,telephone_number
INTO v_country_code
,v_telephone_number
FROM stores_vw
WHERE store_id = p_store_id;
v_area_code
:= CASE
-- Australian International land line
WHEN p_country_code = 'AU'
AND REGEXP_LIKE(p_telephone_number, '^\+61( ?)[2378]')
--e.g. +61 8 9752 6100
THEN '0' || SUBSTR(REPLACE(p_telephone_number,' '), 4, 1)
-- Australian Local land line
WHEN p_country_code = 'AU'
AND REGEXP_LIKE(p_telephone_number, '^0[2378]')
THEN SUBSTR(p_telephone_number, 1, 2)
-- New Zealand International land line
WHEN p_country_code = 'NZ'
AND REGEXP_LIKE(p_telephone_number, '^\+64( ?)[34679]')
-- e.g. +64 3 1234 567
THEN '0' || SUBSTR(REPLACE(p_telephone_number,' '), 4, 1)
-- New Zealand Local land line
WHEN p_country_code = 'NZ'
AND REGEXP_LIKE(p_telephone_number, '^0[34679]')
THEN SUBSTR(p_telephone_number, 1, 2)
ELSE
NULL
END;
EXCEPTION
WHEN NO_DATA_FOUND OR TOO_MANY_ROWS THEN
NULL;
END;
END IF;
RETURN v_area_code;
END get_store_landline_area_code;
Phone number references:
http://en.wikipedia.org/wiki/Telephone_numbers_in_Australia
http://en.wikipedia.org/wiki/Telephone_numbers_in_New_Zealand
Step 2: add a Dynamic Action to prepend the area code to the phone number, if it wasn’t entered already:
Event: Change
Selection Type: Item(s)
Item(s): P1_CUSTOMER_PHONE_NUMBER
Condition: Javascript expression
Value: $v("P1_CUSTOMER_PHONE_NUMBER").length > 0 && $v("P1_CUSTOMER_PHONE_NUMBER").charAt(0) != "0"
True Action: Set Value
Set Type: PL/SQL Expression
PL/SQL Expression: my_util_pkg.get_store_landline_area_code(:F_USER_STORE_ID) || :P1_CUSTOMER_PHONE_NUMBER
Now, when the user types in a local land line but forget the prefix, the system will automatically add it in as soon as they tab out of the field. If the phone number field is unchanged, or is left blank, this will do nothing.
It assumes that the customer’s phone number uses the same prefix as the store, which in most cases will be true. Ultimately the user will still need to check that the phone number is correct for the customer.
I recently was working on an application in APEX 4.2.1.00.08, where the application had several pages with Interactive Reports.
On all these pages, the IR worked fine – except for one crucial page, where the IR’s action menu didn’t work (Select Columns, for example, showed a little circle instead of the expected shuttle region; all the column headings menus would freeze the page; and other issues).
In Console I could see the following errors get raised (depending on which IR widget I tried):
Uncaught SyntaxError: Unexpected token ) desktop_all.min.js?v=4.2.1.00.08:14
$u_evaldesktop_all.min.js?v=4.2.1.00.08:14
_Return widget.interactiveReport.min.js?v=4.2.1.00.08:1
b.onreadystatechange desktop_all.min.js?v=4.2.1.00.08:15
Uncaught TypeError: Object #<error> has no method 'cloneNode' desktop_all.min.js?v=4.2.1.00.08:14
dhtml_ShuttleObject desktop_all.min.js?v=4.2.1.00.08:14
_Return widget.interactiveReport.min.js?v=4.2.1.00.08:1
b.onreadystatechange desktop_all.min.js?v=4.2.1.00.08:15
Uncaught TypeError: Cannot read property 'undefined' of undefined widget.interactiveReport.min.js?v=4.2.1.00.08:1
dialog.column_check widget.interactiveReport.min.js?v=4.2.1.00.08:1
_Return widget.interactiveReport.min.js?v=4.2.1.00.08:1
b.onreadystatechange desktop_all.min.js?v=4.2.1.00.08:15
After a lot of head scratching and some investigative work from the resident javascript guru (“it looks like ajax is not getting the expected results from the server”), I found the following:
http://forums.oracle.com/message/10496937
The one thing in common was that my IR also had a Display Condition on it. In my case, the condition was based on an application item, not REQUEST. I removed the condition, and the problem went away.
I’ve tried to make a reproducible test case with a fresh application, but unfortunately with no success – which means I haven’t yet isolated the actual cause of the issue. A PL/SQL condition like “1=1” doesn’t reproduce the problem. If I have a PL/SQL Expression like “:P1_SHOW = ‘Y'”, or a Value of Item / Column in Expression 1 = Expression 2 with a similar effect, the problem is reproduced – but only in this application.
As a workaround I’ve used a Dynamic Action to hide the IR on page load if required.
Just a little tip I picked up at the InSync13 conference from listening to Scott Wesley. If you have a lot of conditions that look like this:
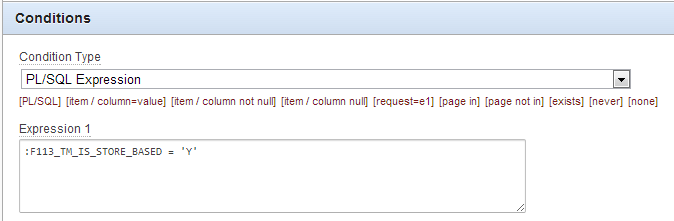 (conditions based on a PL/SQL Expression, where the PL/SQL itself doesn’t actually call anything outside of APEX – it’s only dependent on variables that Apex already knows)
(conditions based on a PL/SQL Expression, where the PL/SQL itself doesn’t actually call anything outside of APEX – it’s only dependent on variables that Apex already knows)
Because it’s a PL/SQL expression, the APEX engine must execute this as dynamic PL/SQL – requiring a parse/execute/fetch. This might take maybe 0.03 seconds or so. If there’s only one condition like this on a page, it won’t make any difference. But if there are 50 conditions on a page, it can make a difference to the overall page performance – adding up to 1 whole second or more to the page request, which can be noticeable.
The better alternative is to use the condition type Value of Item / Column in Expression 1 = Expression 2, e.g.:
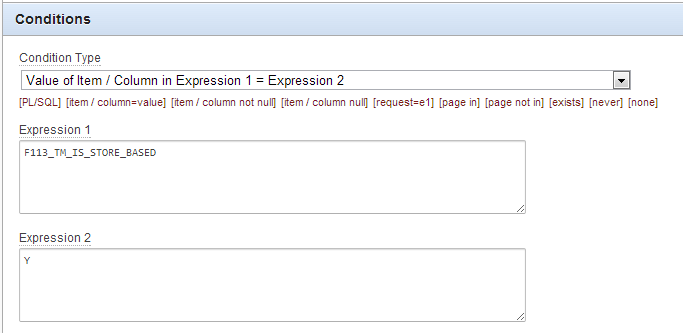
This condition type requires no dynamic PL/SQL – no parsing – which can reduce the time required to an almost negligible amount.
 I love the APEX UI, it makes development so much easier and more convenient – and makes it easy to impress clients when I can quickly fix issues right there and then, using nothing but their computer and their browser, no additional software tools needed.
I love the APEX UI, it makes development so much easier and more convenient – and makes it easy to impress clients when I can quickly fix issues right there and then, using nothing but their computer and their browser, no additional software tools needed.
However, at my main client they have a fairly strict “scripted releases only” policy which is a really excellent policy – deployments must always be provided as a script to run on the command line. This makes for less errors and a little less work for the person who runs the deployment.
In APEX it’s easy to create deployment scripts that will run right in SQL*Plus. You can export a workspace, an application, images, etc. as scripts that will run in SQL*Plus with almost no problem. There’s just a few little things to be aware of, and that’s the subject of this post.
1. Setting the session workspace
Normally if you log into APEX and import an application export script, it will be imported without problem. Also, if you log into SQL*Plus and try to run it, it will work fine as well.
The only difference comes if you want to deploy it into a different workspace ID to the one the application was exported from – e.g. if you want to have two workspaces on one database, one for dev, one for test, when you log into your test schema and try to run it, you’ll see something like this:
SQL> @f118.sql
APPLICATION 118 - My Wonderful App
Set Credentials...
Check Compatibility...
Set Application ID...
begin
*
ERROR at line 1:
ORA-20001: Package variable g_security_group_id must be set.
ORA-06512: at "APEX_040100.WWV_FLOW_API", line 73
ORA-06512: at "APEX_040100.WWV_FLOW_API", line 342
ORA-06512: at line 4
Side note: if you’re using Windows, the SQL*Plus window will disappear too quickly for you to see the error (as the generated apex script sets it to exit on error) – so you should SPOOL to a log file to see the output.
To fix this issue, you need to run a little bit of PL/SQL before you run the export, to override the workspace ID that the script should use:
declare
v_workspace_id NUMBER;
begin
select workspace_id into v_workspace_id
from apex_workspaces where workspace = 'TESTWORKSPACE';
apex_application_install.set_workspace_id (v_workspace_id);
apex_util.set_security_group_id
(p_security_group_id => apex_application_install.get_workspace_id);
apex_application_install.set_schema('TESTSCHEMA');
apex_application_install.set_application_id(119);
apex_application_install.generate_offset;
apex_application_install.set_application_alias('TESTAPP');
end;
/
This will tell the APEX installer to use a different workspace – and a different schema, application ID and alias as well, since 118 already exists on this server. If your app doesn’t have an alias you can omit that last step. Since we’re changing the application ID, we need to get all the other IDs (e.g. item and button internal IDs) throughout the application changed as well, so we call generate_offset which makes sure they won’t conflict.
2. Installing Images
This is easy. Same remarks apply as above if you’re installing the image script into a different workspace.
3. Installing CSS Files
If you export your CSS files using the APEX export facility, these will work just as well as the above, and the same considerations apply if you’re installing into a different workspace.
If you created your CSS export file manually using Shared Components -> Cascading Style Sheets and clicking on your stylesheet and clicking “Display Create File Script“, you will find it doesn’t quite work as well as you might expect. It does work, except that the file doesn’t include a COMMIT at the end. Which normally wouldn’t be much of a problem, until you discover late that the person deploying your scripts didn’t know they should issue a commit (which, of course, would have merely meant the file wasn’t imported) – and they didn’t actually close their session straight away either, but just left it open on their desktop while they went to lunch or a meeting or something.
This meant that when I sent the test team onto the system, the application looked a little “strange”, and all the text was black instead of the pretty colours they’d asked for – because the CSS file wasn’t found. And when I tried to fix this by attempting to re-import the CSS, my session hung (should that be “hanged”? or “became hung”?) – because the deployment person’s session was still holding the relevant locks. Eventually they committed their session and closed it, and the autocommit nature of SQL*Plus ended up fixing the issue magically for us anyway. Which made things interesting the next day as I was trying to work out what had gone wrong, when the system was now working fine, as if innocently saying to me, “what problem?”.
4. A little bug with Data Load tables
We’re on APEX 4.1.1 If you have any CSV Import function in your application using APEX’s Data Loading feature, if you export the application from one schema and import into another schema, you’ll find that the Data Load will simply not work, because the export incorrectly hardcodes the owner of the data load table in the call to create_load_table. This bug is described here: http://community.oracle.com/message/10309103?#10307103 and apparently there’s a patch for it.
wwv_flow_api.create_load_table(
p_id =>4846012021772170+ wwv_flow_api.g_id_offset,
p_flow_id => wwv_flow.g_flow_id,
p_name =>'IMPORT_TABLE',
p_owner =>'MYSCHEMA',
p_table_name =>'IMPORT_TABLE',
p_unique_column_1 =>'ID',
p_is_uk1_case_sensitive =>'Y',
p_unique_column_2 =>'',
p_is_uk2_case_sensitive =>'N',
p_unique_column_3 =>'',
p_is_uk3_case_sensitive =>'N',
p_wizard_page_ids =>'',
p_comments =>'');
The workaround I’ve been using is, before importing into a different schema, I just edit the application script to fix the p_owner in the calls to wwv_flow_api.create_load_table.
5. Automating the Export
I don’t know if this is improved in later versions, but at the moment you can only export Applications using the provided API – no other objects (such as images or CSS files). Just a sample bit of code (you’ll need to put other bits around this to do what you want with the clob – e.g. my script spits it out to serverout so that SQL*Plus will write it to a sql file):
l_clob := WWV_FLOW_UTILITIES.export_application_to_clob
(p_application_id => &APP_ID.
,p_export_ir_public_reports => 'Y'
,p_export_ir_private_reports => 'Y'
,p_export_ir_notifications => 'Y'
);
That’s all my tips for scripting APEX deployments for now. If I encounter any more I’ll add them here.
EDIT:
Related: “What’s the Difference” – comparing exports to find diffs on an APEX application – http://blog.sydoracle.com/2011/11/whats-difference.html
Here is a short story about a little problem that caused me a bit of grief; but in the end had a simple cause and a simple fix.
I had a dynamic action in my APEX 4.1 app that had to run some PL/SQL – which was working fine, except the PL/SQL kept on getting longer and longer and more complex; so quite naturally I wanted it to be encapsulated in a database procedure.
I did so, but it didn’t work: the page ran without error, but it seemed like the dynamic action wasn’t firing. It was supposed to change the value of some display items on the page in response to the change of a radio button item, but now they weren’t changing! There was no debug warnings or logs to give a hint either. I tried using Chrome’s developer tools to trace it but that just showed me a very high-level view of what the client was doing, and didn’t report any errors or warnings.
I reverted to my original code, and it worked fine. Ok, so that means it’s probably a problem with my procedure.
I checked and rechecked my procedure. Didn’t seem to be anything wrong with it. I added a line into the procedure to raise an exception. The APEX page dutifully reported the PL/SQL error in the Ajax call – which means that my procedure was being called successfully. Also, I included the return values in the exception message, and this proved that my procedure was correctly determining the values. They just weren’t being returned to the items on the page.
I tried raising an exception in the apex dynamic action’s PL/SQL Code. That worked. The exception message correctly showed the new values were being returned; they still weren’t being populated on the page.
I tried removing all the items from the Page Items to Return setting; then I gradually added them back in, one by one. I narrowed it down to just one item. If I included that item, none of the items were being updated when the procedure returned. If I excluded that item, all the other items were correctly being updated when the procedure returned. Of course, that wasn’t a solution, because there was a cascade of other dynamic actions that were dependent on that particular item, so it has to be updated.
After lunch and a short walk, it occurred to me: unlike the other parameters, that particular parameter was anchored to a database column defined as CHAR(1). Could that be a problem?
 Sure enough, when I changed the parameter’s data type from column%TYPE (which mapped to a CHAR) to just a plain VARCHAR2, everything worked.
Sure enough, when I changed the parameter’s data type from column%TYPE (which mapped to a CHAR) to just a plain VARCHAR2, everything worked.
Yet another reason to avoid CHAR, I guess.
