Like most active sites our applications have a healthy pipeline of change requests and bug fixes, and we manage this pipeline by maintaining a steady pace of small releases.
Each release is built, tested and deployed within a 3-4 week timeframe. Probably once or twice a month, on a Thursday evening, one or more deployments will be run, and each deployment is fully scripted with as few steps as possible. My standard deployment script has evolved over time to handle a number of cases where failures have happened in the past; failed deployments are rare now.
One issue we encountered some time ago was when a deployment script happened to be run at the same time as a database scheduler job; the job started halfway during the deployment when some objects were in the process of being modified. This led to some temporary compilation failures that caused the job to fail. Ultimately the deployment was successful, and the next time the job ran it was able to recover; but we couldn’t be sure that another failure of this sort wouldn’t cause issues in future. So I added a step to each deployment to temporarily stop all the jobs and re-start them after the deployment completes, with a script like this:
prompt disable_all_jobs.sql
begin
for r in (
select job_name
from user_scheduler_jobs
where schedule_type = 'CALENDAR'
and enabled = 'TRUE'
order by 1
) loop
dbms_scheduler.disable
(name => r.job_name
,force => true);
end loop;
end;
/
This script simply marks all the jobs as “disabled” so they don’t start during the deployment. A very similar script is run at the end of the deployment to re-enable all the scheduler jobs. This works fine, except for the odd occasion when a job just happens to start running, just before the script starts, and the job is still running concurrently with the deployment. The line force => true in the script means that my script allows those jobs to continue running.
To solve this problem, I’ve added the following:
prompt Waiting for any running jobs to finish...
whenever sqlerror exit sql.sqlcode;
declare
max_wait_seconds constant number := 60;
start_time date := sysdate;
job_running varchar2(100);
begin
loop
begin
select job_name
into job_running
from user_scheduler_jobs
where state = 'RUNNING'
and rownum = 1;
exception
when no_data_found then
job_running := null;
end;
exit when job_running is null;
if sysdate - start_time > max_wait_seconds/24/60/60 then
raise_application_error(-20000,
'WARNING: waited for '
|| max_wait_seconds
|| ' seconds but job is still running ('
|| job_running
|| ').');
else
dbms_lock.sleep(2);
end if;
end loop;
end;
/
When the DBA runs the above script, it pauses to allow any running jobs to finish. Our jobs almost always finish in less than 30 seconds, usually sooner. The loop checks for any running jobs; if there are no jobs running it exits straight away – otherwise, it waits for a few seconds then checks again. If a job is still running after a minute, the script fails (stopping the deployment) and the DBA can investigate further to see what’s going on; once the job has finished, they can re-start the deployment.
It’s well known that after processing a page one often needs to add a Branch so the user is taken to another page, e.g. to start the next step in a process. It’s less common to need a Branch that is evaluated before the page is shown. This is a “Before Header” Branch and I use it when the user might open a page but need to be redirected to a different one.
A good example is a page that is designed to direct the user to two or more different pages depending on what data they requested.
Another way that a branch like this can be useful is where a user might navigate to a page that should show a record, but if the record ID is not set, I might want the page to automatically redirect the user back to a report page instead.
Of course, you have to take some care with these sorts of branches; if the target page also has its own “Before Header” branch, that will also be evaluated; if the user ends up in a loop of branches the page will fail to load (with a “ERR_TOO_MANY_REDIRECTS” error).
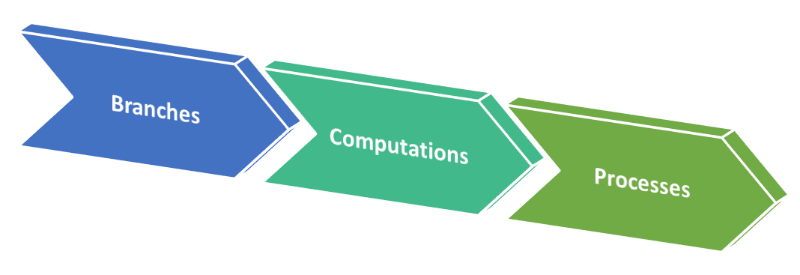
This is the order in which various steps are done before APEX shows a page:
Authentication check
Verify session
“Before Header” Branches
Authorization check
Computations
“Before Header” Processes
Regions, etc.
One of the implications of the above order is that any computations or processes that set or change application state (e.g. an application item) are not run before it evaluates conditions or attributes for any “Before Header” Branches. This applies regardless of whether the computations or processes are defined on the page, or defined globally in Shared Components. This little detail tripped me up today, because I had a branch that I needed to run based on a condition that relied on state that should have been set by a “Before Header” process defined globally.
If you need to redirect a user to a different page on the basis of any application state that is set by a computation or process, you can use a PL/SQL Process instead that does the redirect. The PL/SQL code to use is something like:
Warning: redirect_url raises the exception ORA-20876: Stop APEX Engine, so it’s probably preferable to avoid combining this with other PL/SQL code that might need to be committed first.
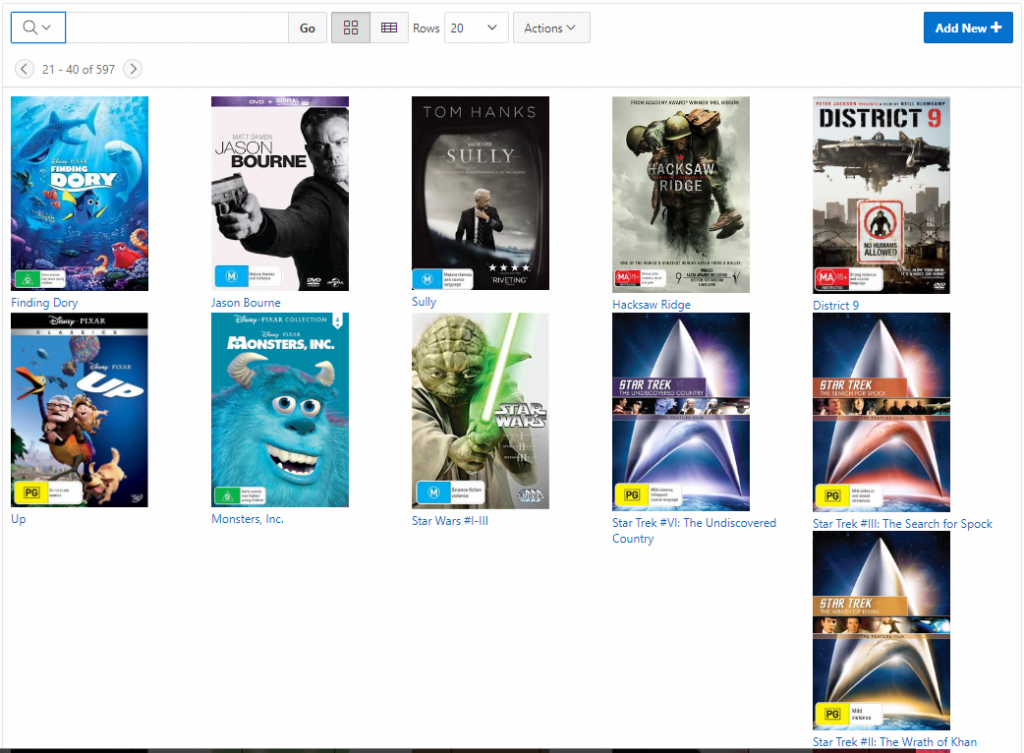
I had an interactive report an an old APEX application that I’ve kept maintained for quite a few years, which is able to show an Icon View that shows a thumbnail of the image for each item.
The problem was that the layout sometimes went wonky depending on the size of the image or the size of the label text. How the items were laid out depended on the width of the viewing window as well. I have set Columns Per Row to 5, and I’m using a Custom Icon View with the following Custom Link:
Each item shows an image, scaled down to width 140 pixels (my images come in all sorts of sizes), plus the title; either the title or the image may be clicked to open the details for it.
This is how it looked:
Depending on a number of variables (length of the label text, and the width of the viewing window) some rows would show their first item in the 5th column instead of over on the left; this would have a run-on effect to following rows. In addition, I wasn’t quite happy with the left-justified layout for each item.
To fix this I added some DIVs and some CSS. My Custom Link is now:
Some of the key bits here are that the container div has width and height attributes, and the image is constrained using max-width, max-height, width:auto and height:auto. Also, the work title is constrained to a 40 pixel high block, with overflow:hidden.
My report now looks like this:
The images are scaled down automatically to fit within a consistent size, and both the images and the labels are horizontally centered leading to a more pleasing layout. If an image is already small enough, it won’t be scaled up but will be shown full-size within the available area. Also, the label height is constrained (if an item label is too high the overflow will be hidden) which solves the layout problem I had before. If the image is not very tall, the label appears directly beneath it which is what I wanted.
The only remaining issue is that the icon view feature of the interactive report generates a table with rows of a fixed number of columns (5, in my case), which doesn’t wrap so nicely on a small screen when it can’t fit 5 in a row. I’ve set Columns Per Row to 1 now, and it seems to wrap perfectly; it shows up to a maximum of 6 items per row depending on the viewing window width.
POSTSCRIPT – Lazy Load
Thanks to Matt (see comment below) who pointed out that a report like this would benefit greatly from a Lazy Load feature to reduce the amount of data pulled to the client – for example, if the user requests 5,000 records per page and starts paging through the results, each page view could potentially download a large volume of data, especially if the images are quite large. I’ve implemented this now and it was quite straightforward:
Upload the file jquery.lazyload-any.js to Static Application Files
Add the following to the page attribute File URLs: #APP_IMAGES#jquery.lazyload-any.js
Add a Dynamic Action to the report region: Event = After Refresh Action = Execute JavaScript Code Code = $(".workicon").lazyload() Fire on Initialization = Yes
Modify the Icon View Custom Link code to put the bits to lazy load within a script tag of type “text/lazyload” (in my case, all the html contents within the “workicon” div), e.g.:
This was an important addition in my cases as some of the images were quite large; I don’t have to worry about load on my server because they are hosted on Amazon S3, but I do have to pay a little bit for the transfer of data.